Daaamn, I must have forgotten that the interviews coded “the old way” were there. I really am sorry.
The difference stems primarily from the fact that the original was coded before I and Jan redid the codebook and the later version was coded with a much better understanding of what the codebook really looks like.
Second reason is that I tried to make each post a stand-alone unit of analysis and it clearly needed a different approach when a post contained the whole interview vs just a part of it (a reponse to the interviewer’s question).
We have 17 interviews coded on the platform right now, I might have changed names and there might be mistakes to dates, but I only spoke once to each person. Re the names - those are pseudonyms given by me, hence serve solely a organizational purpose.
Here are some commented picture, for @nica and all to repeat the analysis.
Core values
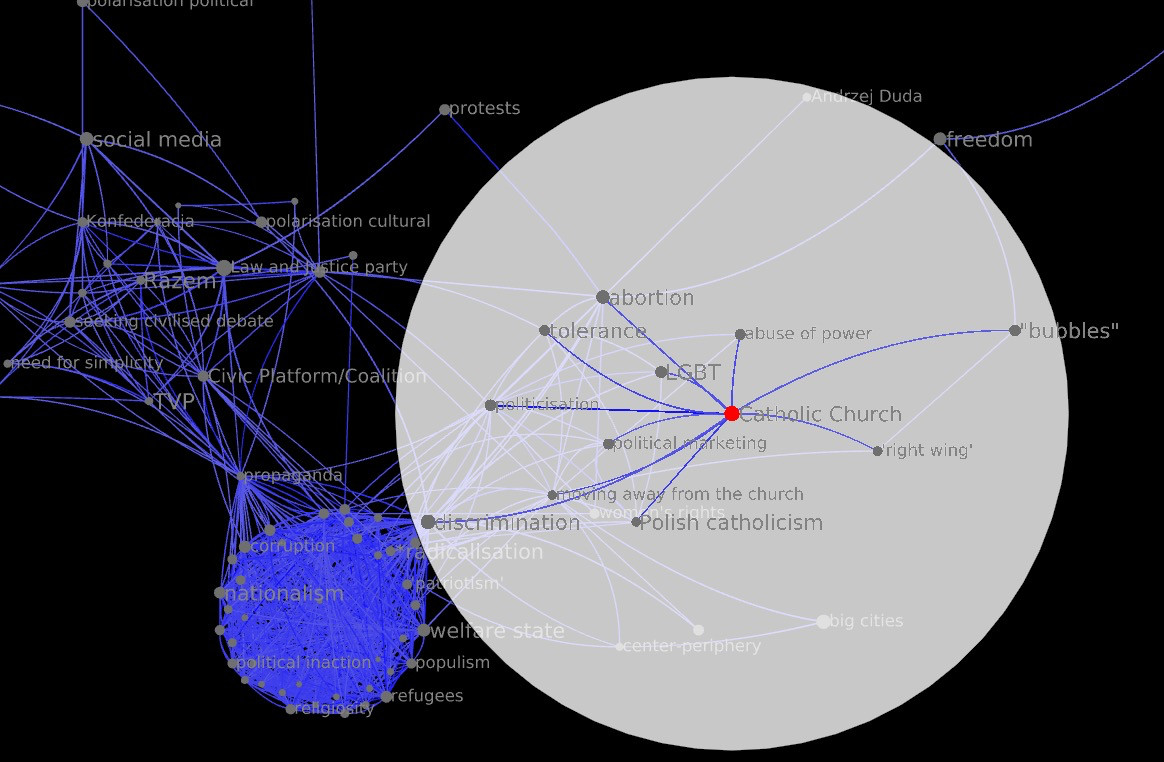
The maximal k k-core is a 42-core, and has 43 codes. Catholic Church does not belong to this core: its core value is 28. The maximal k k-core to which `Catholic Church belongs is a 28-core with 82 codes. This is the third-innermost core: there are also a 29-core and the maximal 42-core. The 28-core with Catholic Church (in red) is shown.

List of codes in the innermost 42-core
non-catholic religious organisation, kościoły niekatolickie
government inefficiency, niewydolność rządu
“LGBT ideology”,
atheism, ateizm
political choice right, wybór polityczny prawica
discrimination, dyskryminacja
“getting up off knees”, “wstawanie z kolan”
*diaspora, diaspora
restoring dignity, przywracanie godności
Russians, Rosjanie
Partitions, rozbiory
nationalism, nacjonalizm
invoking history, odwoływanie się do przeszłości
Germans,
savior complex,
religiosity, religijność
labour rights,
state support, wsparcie państwa
‘patriotism’, ‘patriotyzm’
welfare state, państwo opiekuńcze
privatization, prywatyzacja
propaganda,
*radicalisation, radykalizacja
apoliticism, apolityczność
need of a third option, potrzeba trzeciej opcji
*frustration, frustracja
corruption, korupcja
countryside,
political inaction, bezczynność polityków
500+,
provinciality, prowincjonalność
political scandal,
exclusion, wykluczenie
Civic Platform/Coalition, Platforma/Koalicja Obwytelska
Law and Justice party, PiS
the uncultured,
populism, populizm
conservatism, konserwatyzm
‘Polishness’, ‘polskość’
demonization, demonizacja
“non-heterosexual”, “niehetero”
refugees, uchodźcy
ethnic and religious minorities, mniejszości
List of codes in the 28-core containing "Catholic Church"
non-catholic religious organisation, kościoły niekatolickie
government inefficiency, niewydolność rządu
"LGBT ideology,
atheism, ateizm
political choice right, wybór polityczny prawica
discrimination, dyskryminacja
“getting up off knees”, “wstawanie z kolan”
*diaspora, diaspora
restoring dignity, przywracanie godności
Russians, Rosjanie
Partitions, rozbiory
nationalism, nacjonalizm
invoking history, odwoływanie się do przeszłości
Germans,
savior complex,
religiosity, religijność
labour rights,
state support, wsparcie państwa
‘patriotism’, ‘patriotyzm’
welfare state, państwo opiekuńcze
privatization, prywatyzacja
propaganda,
*radicalisation, radykalizacja
apoliticism, apolityczność
need of a third option, potrzeba trzeciej opcji
*frustration, frustracja
corruption, korupcja
countryside,
political inaction, bezczynność polityków
500+,
provinciality, prowincjonalność
political scandal,
exclusion, wykluczenie
Civic Platform/Coalition, Platforma/Koalicja Obwytelska
Law and Justice party, PiS
the uncultured,
populism, populizm
conservatism, konserwatyzm
‘Polishness’, ‘polskość’
demonization, demonizacja
“non-heterosexual”, “niehetero”
refugees, uchodźcy
ethnic and religious minorities, mniejszości
Simmelian backbone
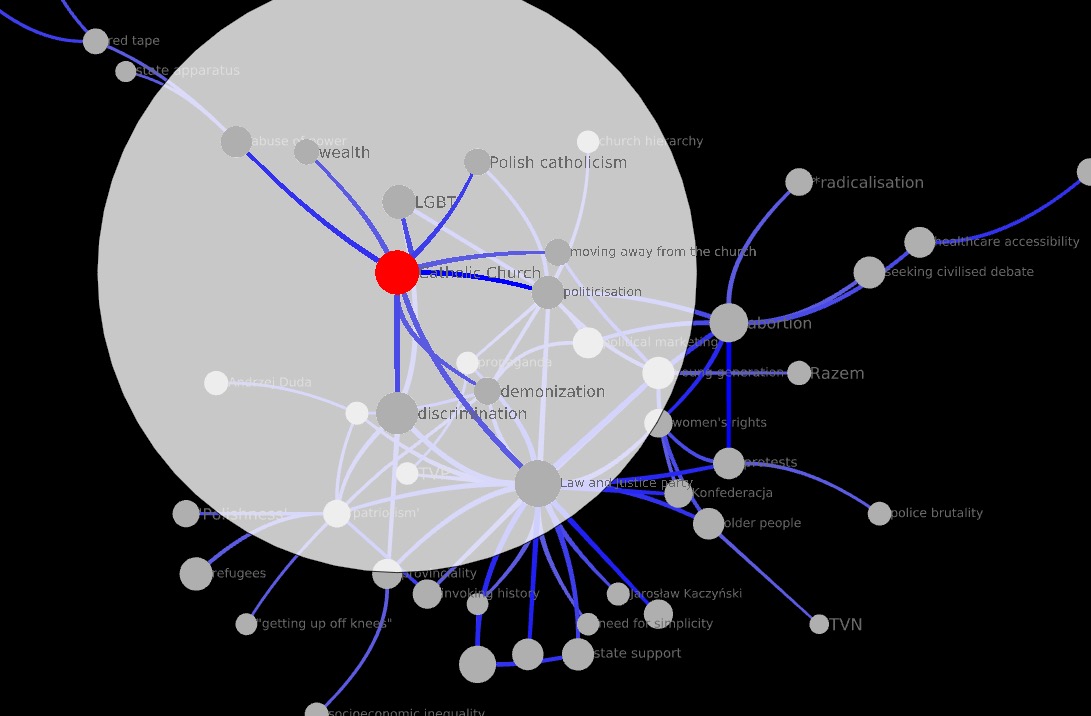
The backbone of this smaller network is quite different from that of the network derived from the data with the repeated interviews. It is also simpler. Already with r > 20 three communities are clearly visible; but here the network is still quite large (115 codes) and dense (1,808 edges) for ego network analysis. Further reducing to r > 30, the picture becomes clearer:
At this level of reduction, Catholic Church is not really bridging between communities. It, does, however, belong firmly to a community of codes that are political rather than spiritual. To the northwest, the edges from the neighbors of Catholic Church all, save one, go through young generation. To the southeast, there is a very dense community of codes connected by high-redundancy edges. The highest-redundancy edge adjacent to Catholic Church is still to politicisation (r = 55). The highest-redundancy edge in the whole corpus occurs between Polishness and patriotism(r = 61).
Association depth
The structure of this network seems to be dominated by a few central codes: Law and Justice Party, Politicisation, Abortion, and indeed Catholic Church. This becomes clearest when selecting edges for d > 4 or d > 5. The ego network of Catholic Church, when edge selection happens in this way, remains oriented towards “political” codes. Here d > 4 is shown.
Association breadth
These last conclusions are supported by the reduction by association breadth. Overall, codes that are deeply associated also tend to be broadly associated (correlation coefficient = 0.88). This is what you see at b > 2, which means looking only at co-occurrences endorsed by at least three of the 17 informants:
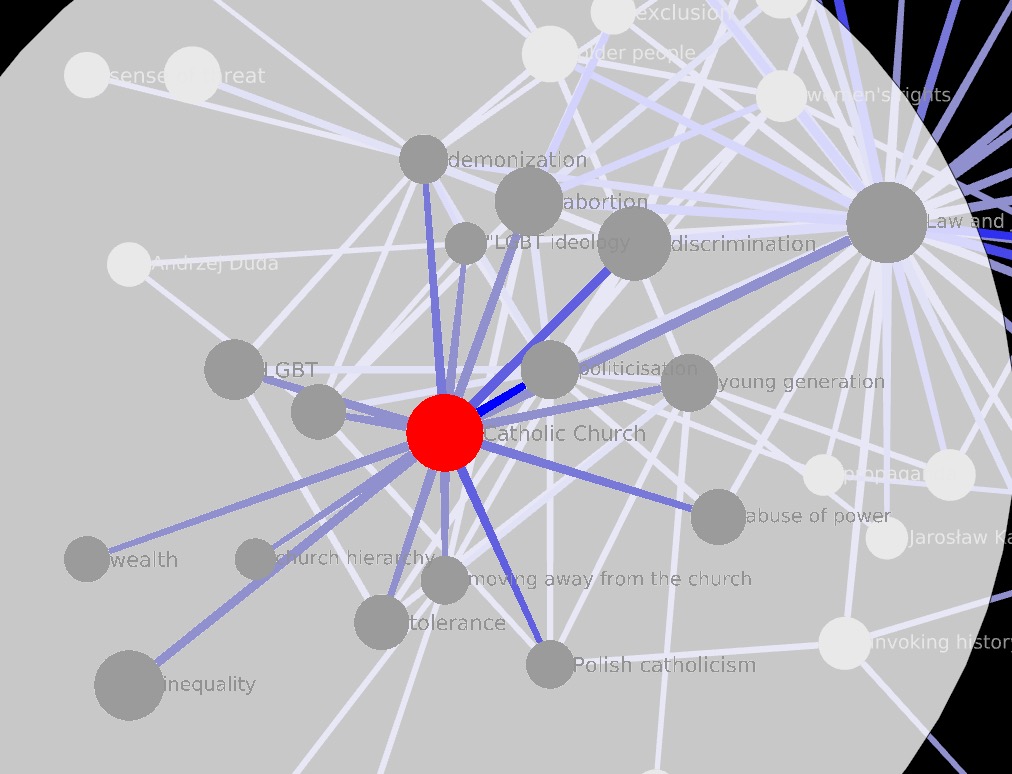
1 Like
I have found the problem: there are “phantom” topics. like this.
Can I please ask you to clean up your data, and keep it clean? One topic per interview: one pseudonym per real informant; personal notes well separated out from interview transcription. Which means: everything that is not a properly coded interview for the ICQE2022 corpus should not have the ethno-icqe2022 tag.
So based on this it looks like we will have to re-draft part of the ethnographic section so that they makes sense with this data – the Core Values section and the Simmelian backbone one. The depth and breadth can stand as they are. This is not a disaster – I can re-draft this week, and since we have more time because of the submission deadline being pushed back, we will have time to polish the updated draft.
But it is extremely important that all the data is clean and organized by the time we start actively writing the final report draft. So it is important that over the next few weeks, all the information is in the format @alberto mentioned – one topic per interview, one pseudonym per informant, notes/annotations clearly separated out from the transcriptions.
Is it feasible for us (everyone who will be involved with the final report) to have a meeting to do a quick real-time “audit” of the data in the first week of June, so we can work together to collectively identify and trouble-shoot any issues that might remain?
2 Likes
In this case, I don’t believe that it’s my mistake, but @Wojt for tagging all the topics in the section, including those that I kept for the purpose of adding interviews there later on. Those topics are not “phantom”, but for some reason were tagged and included in the dataset. My data and organized is clean, it is just organized in a particular way, that you didn’t get at first - I would appreciate it if you could ask first, instead of making assumptions.
I think Wojt made here an honest mistake by misunderstanding how the platform works, and over-tagging, instead of just picking the interviews that were actually supposed to be there. You know, none of us were using the platform to analyze before - and in particular, the coders, who are the ones responsible for coding the data using ER. So there is a learning curve.
It is frustrating, but now that we know what happened - using the conference tag where it shouldn’t be - we can easily fix it. Luckily we have time bc of the extended deadline!
I think I did. I really and truly apologize for putting more work on your shoulders, team.
2 Likes
Yes, the data needs to be tidied up. That particular format might not work as well for the final report as it does for ICQE22: for example, we also have forum posts, and maybe we want to use them, though they do not fit in the “one interview, one topic” scheme.
This is a great idea, and I fully support it. We might even do some minor methodological innovation in documentation: how do you publish field notes in data form?
We are not looking for guilty parties here, just learning from our mistakes how to go about this better. And what we learned is this: to make research accountable, we should try to put ourselves in the shoes of someone wishing to understand our process, delve in our data and see if they can agree that our results derive more or less naturally from the data. We should organize our work so as to make this as easy as possible.
This means making the organization of data explicit. For example, in this case, maybe a topic called “Organization of data for the ICQE22 paper”, which would explain in some detail what goes where, and also some contextual information (example: link to the consent form; where the consent forms are kept, etc.). I disagree with Magda that people should ask first: it is on us to be transparent, not on others to guess at how exactly we are working.
Agree!
1 Like
Please take a look at the updated version of the ethnographic analysis sections based on the updated visualizations from @alberto and let me know what you think. The updated sections are in yellow. Please note that this version still features the old graphs.
1 Like
@icqe22_authors the full draft is now ready for review on Overleaf. It incorporates:
- New data analysis
- New visualizations in Figure 2
- Nica’s redrafting of section 6 (and one extra clause in section 7)
- My own comments and attempts at integrating sections 6 and 7 into the whole.
1 Like
@alberto I don’t see your comments in Overleaf. Is there a function I need to turn on to see comments?
No function. It is a column to the right of the code, which is folded in by default and looks like a vertical stripe… Click on the arrow on the stripe to expand the comments column.
Currently reading the paper. Just fixed some LaTeX here and there (see my comments).
Thanks Bruno. To all @icqe22_authors: I plan to submit on Friday afternoon Brussels time, please make sure you re-read before then.
@alberto, @Nica and all, I will be reading today. If necessary, I will continue tomorrow, as early as possible.
I am done. Well done. I suggested several edits, mostly at the beginning. Ciao.
1 Like
@alberto Hey boss, do you want me to have a look at the whole thing one more time or do anything else before the deadline? I gather you want to upload it on Friday, right? Ciao
1 Like
Yes, the whole thing is what we need to revise now.
I have done my reading - I suppose you @alberto will be reacting to (accepting or rejecting) our suggestions. If you have questions, holler.