Check this out!
When @Jason_Vallet regenerated the database, he included some newer annotations that previously had been left out of it. The co-occurrences graph for co-occurrences >= 4 now looks like this:
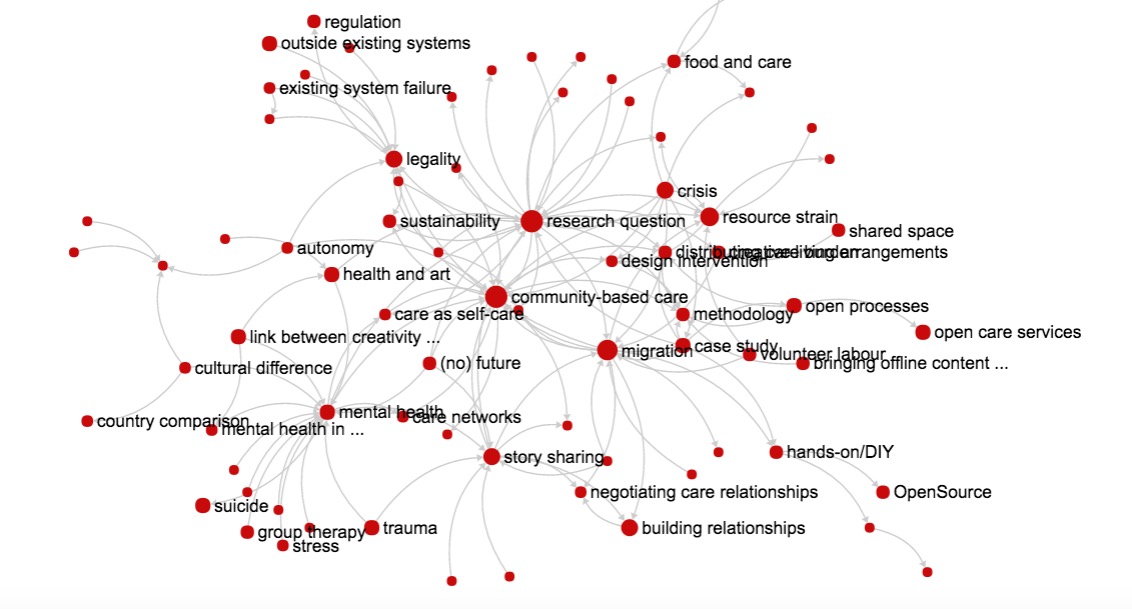
It reflects your answer very well, @Amelia . mental health has moved yet closer into the center of the graph (in November it was connected to it only via “skill sharing”). legality is still in the same position, as the only hub connecting some in-graph codes like autonomy, sustainability, community-based care and migration ; and some out-graph codes like existing system failure and, yes, safety.
Did you reply based on browsing the graph, or was it just off the top of your head, based on having done the coding?
The recent expansion of the discussions around mental health is, I think, tied to the onboarding workshop we organised in Galway in December 2016. Apparently the West of Ireland has an endemic suicide problem, especially among men. This has raised public awareness of issues like depression. So a lot of the people doing open care there are focused on mental care.
Finally, there is an interesting regularity. Try “stressing” the co-occurrences graph, by imposing that the number of co-occurrences sustaining each edge is higher than 4: at 5, 6 and even 7 the graph seems to be telling me the same story, although it gets more and more barebones-simple as you increase the minimum required edge strength. At co-occurrences >= 7 you get this:
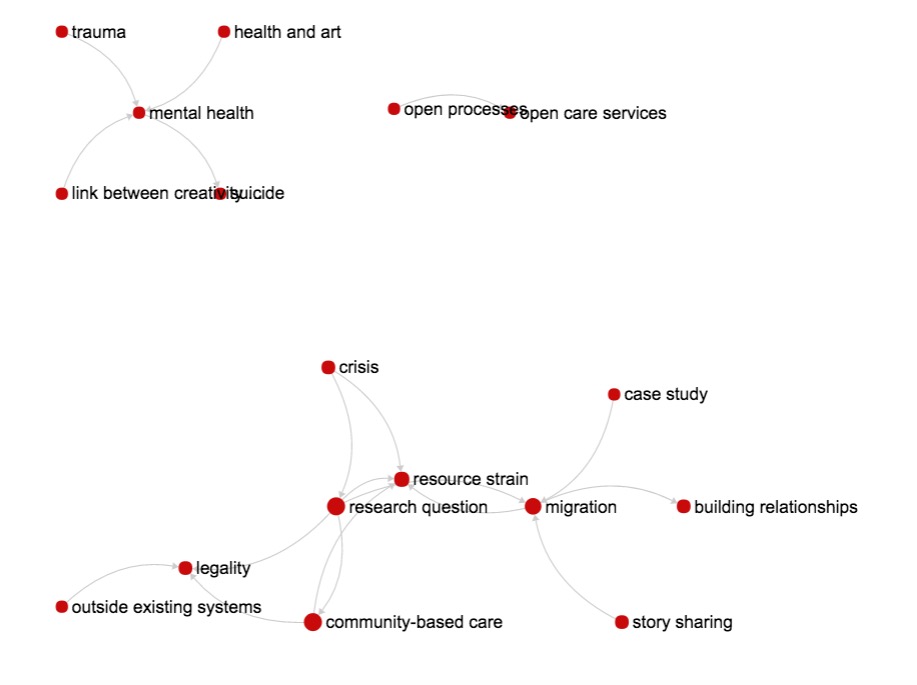
What are we talking about here? Well, if you ignore research question, as we should, community-based care becomes the center of the graph. It connects to legality and to resource strain, itself connected with crisis and migration. The latter is then connected to two codes representing solutions, or at least concepts underpinning solutions: building relationships and story sharing. mental health and open processes are each at the center of its own component: they are very important concepts (edge strength is at least 7!), but with a weaker connection to community-based care than codes in the giant component. I don’t know if this is an artefact of Amelia’s approach to coding or the signature of a coherent conversation, coded well. What do you think? Are we looking at Amelia thinking, or are we looking at the community thinking? Amelia? @Federico_Monaco ?
Maybe the way to present these (secondary) data is to start from a very high edge strength (5-7) to give ourselves a high-level description, and only then go on to lower our requirements on edge strength to discover new codes and new connections. It would be like looking at volcaninc islands emerging from the ocean: as they are pushed up, what looked initially as a set of disconnected islands reveals itself as the peaks of the same mountain range.