After some tinkering, I have more information about the data structure used by OpenEthnographer.
There are two main entities: codes and annotations.
- Codes obtain by repurposing the Drupal entity called taxonomy term from the Taxonomy core module. OpenEthnographer creates and maintains a specific vocabulary of taxonomy terms called (you guessed it ) Open Ethnographer: https://edgeryders.eu/en/admin/structure/taxonomy/openethnographer . A code consists of a name, an ID, an optional description and a parent (obviously only for codes that are not at the top level in the hierarchy).
- Annotations obtain by repurposing the Drupal entity called annotation from the Annotator module. An annotation consists of a person (author, aka the ethnographer) associating a snippet of text in a Drupal node or comment to a taxonomy term. The latter is identified via
Tid in the database. You can join on Tid to find all the annotations associated to a specific code.
I have made views that return all entities of both kinds in JSON format:
- https://edgeryders.eu/en/openethnographer-codes
- https://edgeryders.eu/en/openethnographer-annotations
@melancon and @Amelia and @danohu – the latter might correct me if I am wrong.
ID missing in the ethno code json file
The title says it all: IDs are missing in the ethno code json file. We get things like:
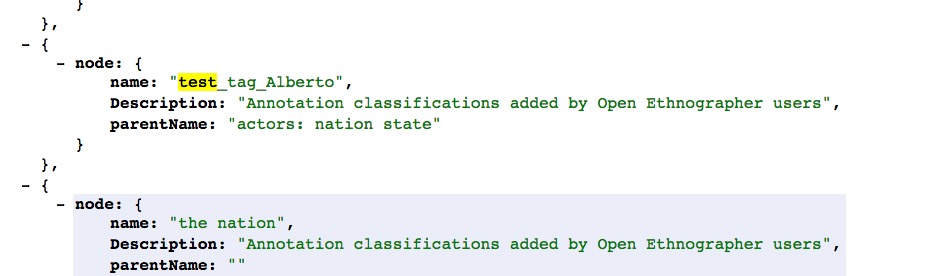
node: {
name: “actors: communities”,
Description: “Annotation classifications added by Open Ethnographer users”,
parentName: “”
}
1 Like
Just bad data
The view feeding the API is correctly configured. If you look at my test code, that was generated as a child of an existing code, you find it is reported normally.
This is what I think happened: Spot The Future was done with an earlier, RDFa based-version of OE. It used text styles, not taxonomy terms, as a proxy for ethno codes. Since text styles are not per se hierarchical, the parent term was stuck in a prefix, so that the ethnographer would see all “actors:XX” close to each other in the style menu (only ethnographers would see these text styles, normal users could not see them).
What it comes down to is: we have two possibilities. Either we rearrange the taxonomy, creating parent codes (in this case: “actors”), and then assign all codes of type “actors:XX” to be children of those parents; or we just ignore this stuff and generate fresh codes. Unfortunately, as we discussed. to generate fresh data we need some coding work on OE…
Tomorrow I will assess how much work I need to do to restructure STF codes. I will need something for the London conference, which by the way is confirmed and happening on September 15th.
prefix instead of ids?
Is that what you are saying? That these old ethno codes use text prefix to indicate child-parent relationship?
What I pointed at is that codes do not have an id (no id field contrarily to what your initial post says). This means we cannot link back from annotations (in the https://edgeryders.eu/en/openethnographer-annotations view) to codes (in the https://edgeryders.eu/en/openethnographer-annotations view) using the “Annotation ID” field.
?
Good news, bad news
Good news: the Drupal interface supports rearrangement of ethno codes (technically: of taxonomy terms, since our ethno codes are the terms of the OpenEthnographer vocabulary). Also, hierarchies are supported. I went as far as four levels deep, I suspect that there is no limit to how many levels you can add in the hierarchy. I have done the following:
- created a top-level
spotTheFuture term.
- created two children terms,
actors and assets as category terms. The assignment is done navigating to the Taxonomy term page, clicking "Relationships" and selecting the parent node.
- renamed all codes marked
actor:codename and asset:codename as codename , and selected actor and asset respectively as their parent node.
Note that a code can be a child to more than one parent. This means that the hierarchy of codes does not have to be a tree. For example “environmental science” could be a child both of “environent” and “science”. I have tested this on my test tag. THe result looks like this:
Bad news: the codes for STF do not correspond to the code tree with the hierarchy that we produced in 2014. I think @Inga_Popovaite might have re-built the hierarchy outside OE. I will ask.
In general, however, we will not need to have a hierarchy of codes that fans out from the project. There is no need. In fact, the whole idea of OE is that the codes can be shared across projects. When you want to grab a project from the API, you will use the annotations or the contentinstead:
- Grab all codes, because you are going to need them.
- Grab annotations, but filter out those that have not been made by the ethnographers who are part of your team. You can combine this filtering method by
- Grab content. Now, filter out all annotations that refer to content without the scope of your project. For example, the APIs for opencare return only opencare content. OE annotations APIs will return annotations that refer to non-opencare stuff, but you can decide to filter them out.
But in general, each ethnographer can use other ethnographer’s annotations as a guide to finding more material on Edgeryders. For example, suppose I am coding a conversation and find people talking about debt. I might want to navigate to the “debt” code (taxonomy term) page, from there to annotations that encode “debt”, and from there to the actial content where other ethnographers have found people talking about debt. This can be used as “parallax data” to give my research more debt.
To enable this, codes should be “floating around”, detached from specific projects and ethnographer. We will want to write guidelines for this: it’s not so much about using a piece of software, it’s about turning ethnography into a massively collaborative endeavour.
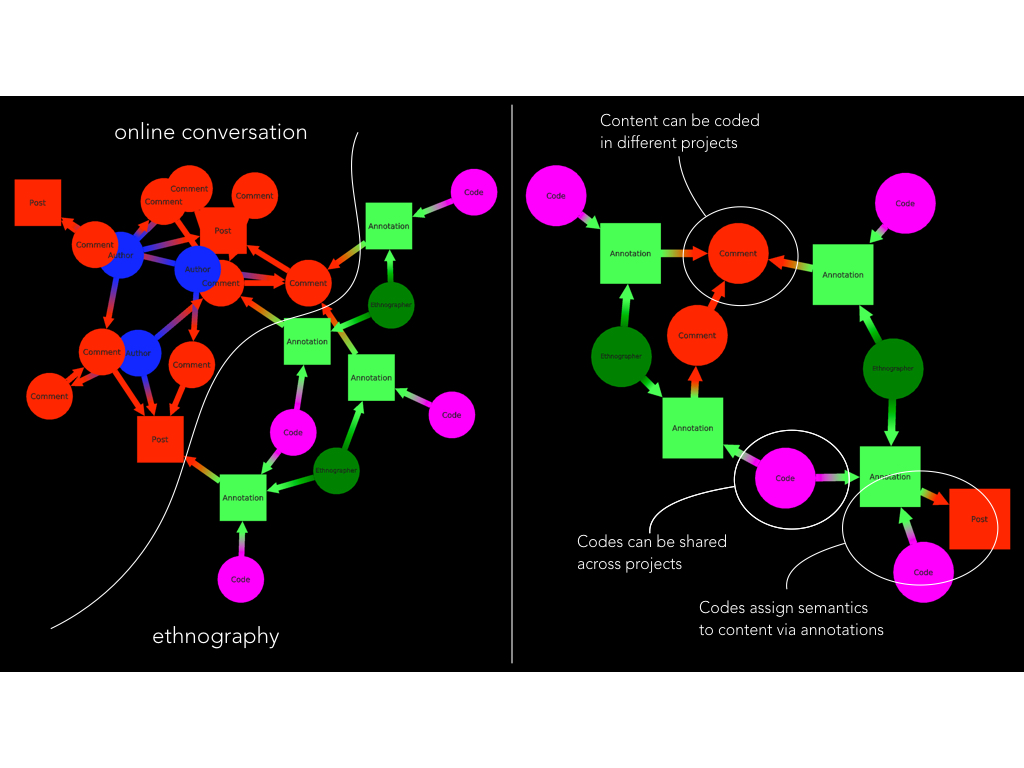
I made this visualization of the data model in OE, that illustrates the roles of codes and annotations.
Fetching codes
Hi @Alberto,
Yes, you are right. I created the hierarchy outside of ER platform for the STF study (as there was no OE prototype then…)
I have a quick question: the ER website changed quite a lot since the last time I used OE. How do I download a codeset after I finish tagging?
https://edgeryders.eu/en/annotation/export does not work anymore (this is the link I used before, for the Stewardship ethnography). What should I try instead? And another thing: as Digital Festival is the second project tagged by the same author (me), will I end up with a dataset that includes all my tags (this + Stewardship?), or will I be able to separate the new ones somehow prior to downloading?
APIs
Annotations and codes (not just yours) are exportable in JSON format via API. See the post that started this thread for the two links.
Thank you! Another question: how do I import it to rqda for further analysis? Maybe @Matthias or @danohu could help me here?
rjson
I am not familiar with RQDA, but there is a package of R to deal with json files. It’s called rjson: Importing data from a JSON file into R - Stack Overflow
You might be able to save the annotations JSON from the API, open it in R through rjson and save it in a format that RQDA can digest.
We will have someone (coincidentally also called Jason!) to work on OE starting September.
Missing the old OE version
I’ve grabbed both json files to R, but I can not use them for analysis because there is no link between anotations and codes. I could merge them together if both would have corresponding IDs, but they don’t (or is there something I am not seeing?). What happened to the first OE version that I used for the Stewardship project? Is it possible to activate it at least for a day or two so I could fetch the coded data from the Digital Festival and finish the analysis asap? Or should I look for different solutions and workarounds? I can redo all coding in rqda as there is not too much data – codes would correspond to the ones online – but then it beats the purpose of coding online. Any thoughts or/and suggestions @Alberto, @Nadia, @Matthias?
Export URL
@Inga_Popovaite , did you try the export URL https://edgeryders.eu/annotation/export to get the RQDA file of all your own codings. It should work, and in my case gives me a RQDA file (though ith no codings in my case).
This is documented in the manual under “How to export a file for further analysis?”, but admittedly it should get a UI element since it’s a kind of “hidden feature” the way it is now …
It was the first thing I tried, but…
But all I get is this:
@Matthias, any suggestions what I could try?
It’s a bug then
Since the function provides a RQDA file to me, and did so for you last year, it must be a bug. Probably triggered by one of your annotations that is somehow different from “normally”. (Not you fault obviously …). I don’t really have the capacity to dive into debugging this right now. How can we organize this then, @Alberto ?
Two possibilities
There are two possibilities, @Inga_Popovaite and @Matthias .
- Easy (and recommended): just code offline. We will have a person to properly set up OE, but he will start working in early September.
- Harder but more elegant: Inga had a point, my API for codes did not output the taxonomy term ID. But that was wasy to fix, because of course Drupal knows what the ID is, and in fact I fixed it. Moreover, the API for annotations already had a field for the code ID. I re-labeled "Term ID" for added clarity (and I used the same label for the codes API). The code can be associated to the annotation via the Term ID. So, the two JSONs contain everything needed to construct a RQDA file.
For example, this annotation is associated to the Term ID “982”:
{
“node” : {
“Annotation ID” : “25”,
“Author uid” : “5,672”,
“Name” : “Inga_Popovaite”,
“Date created” : “Tuesday, February 17, 2015 - 08:59”,
“Date updated” : “Tuesday, February 17, 2015 - 08:59”,
“Entity_id” : “3,593”,
“Entity_type” : “node”,
“Quote” : "Over the centuries, nation states all over the world have developed or acquired control of assets of all kinds. […]
“Tid” : “982”
}
To find out what “982” means, you need to look up the codes JSON:
{
“node” : {
“name” : “challenge: state struggle”,
“Description” : “Annotation classifications added by Open Ethnographer users”,
“parentName” : “”,
“Term ID” : “982”,
“Parent Term ID” : “0”
}
So, it is “challenge: state struggle”.
If I had an example of the file type RQDA accepts, I would maybe be able to write a Python script that “eats” the JSONs and returns a RQDA file. Shall I try? Matt, do you have this stuff already documented somewhere?
Would work, but fixing the bug is less effort then
Option 2 may technically work indeed, and it is kind of documented in code / READMEs since I did the RQDA file conversion twice by now (once a script the CKEditor based prototype, once for OpenEthnographer). It’s basically a SQLite file. Not too difficult to handle, yet also not that simple. But. Since your programming would duplicate most of the effort of what OpenEthnographer includes right now (with a bug), it’s not really economical. We should just fix the bug instead, then. Maybe let’s post a project on Upwork (formerly oDesk) and see who applies? Mmmh no then I spend more time giving instructions than I would need fixing this myself …
I can try and look at the documentation of your code?
But the only language that I know is Python. Sometimes it is possible to fix anyway, if the code is simple.
But… Python. Of course there is a library that manages SQLite files; so a very high-level plan for option 2 would be to call APIs from a Python script, load all their content into objects, then store them as a SQLite file. Should not be too hard. especially with this tutorial. What do you think? This would make my work more reliable. I might still get stuck but it is much less of a shot in the dark.
(I am always amazed at the sheer mass of high quality information available around open source software. It’s kind of a minor miracle.)
The task at hand
Just to measure up the task: is it the case that the SQLite file needs to encode:
- one table for the annotations + one table for the codes
- in each table, a column for each field
- IDs are considered strings:
"Term ID" : "982" , not "Term ID" : 982
- no need to worry about operations like indexing etc, because they will be handled by RQDA itself.
If that is the case, I should be able to create the tables with the appropriate columns, then iterate on the Python objects and append records to the tables.
This would obtain a legitimate SQLite file, but not sure if RQDA imposes additional constraints. Unfortunately, the link to the schema in the documentation (http://www.inside-r.org/packages/cran/RQDA/docs/RQDATables) does not work anymore (leads to a Microsoft page??) and I have not been able to find an alternative.
Coding offline
@Alberto, RQDA uses SQLite database format. I’ve started making a copy of all codes+annotations offline.
Another thing I’ve noticed: last year I’ve mentioned that the https://edgeryders.eu/annotation/export lost about 10% of coded information: it returned just empty codes with no annotations associated with them. Now, I was going through all the coded material and I saw that some of the text that I definitely marked up before (the tags for that particular part of text are in the drop down menu) has marking no more. And it all happened after I tried to export annotations several times. Any ideas why this is happening?..@Matthias?
And than you both for your help!