Similarly to what happened with the German corpus, the Czech one also is suffering from similar issues. @SantosCardonaPR and @Jirka_Kocian are aware of them. This post is to provide them with materials aimed at making the cleanup faster.
First of all, this spreadsheet contains all codes used in the Czech corpus, arranged in ascending alphabetical order of the English label. The rightmost column is the live link to the code’s page on Edgeryders’s back end, so you can quickly go from the spreadsheet to the back end.
Problem 1: duplicate codes
Duplicate codes are a common error. They happen when an ethnographer generates his own new code, unaware that an identical one was already used for the same corpus. If you scroll throught the spreadsheet, you will find them easily, as in this example:
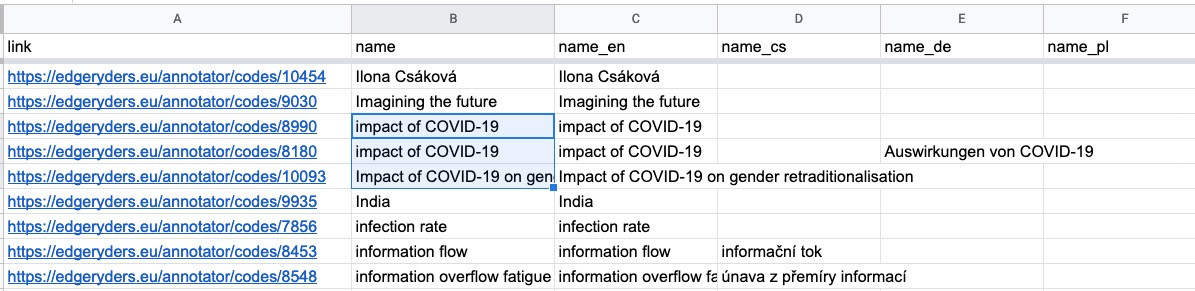
[details = Here are the 33 codes, used for annotating ethno-rebelpop-czech-interviews, that are synonimous with other codes (synonimous = same English label, ignoring capitalization).]
anti-vaxxers
caring about future generations
community
culdisorient
culman
czechs
donald trump
economy
eeconomicviol
envenergy
envgenprob
eu
europe
facebook
gender role models
gensexism
homophobia
impact of covid-19
morals
new routine
online platforms
polpol
populism
russia
social activism
social distancing
social isolation
social media
staying at home
viktor orban
volunteering
xenophobia
young generation
[/details]
Please note that there are less obvious duplicates, for example democracy and demokracie, and check for them too.
Problem 2: inaccurate labeling by language
Some codes have no English label. In most of them the English label was recorded in the database field of the label in another language, normally (in this corpus) Czech, but occasionally others. In the spreadsheet linked above, you can find them quickly sorting for the name_en column. There are only 33 such codes.

