One workaround would be to modify my script so that it does include annotations for posts in protected categories, but that the script redacts the content of those posts, the quoted snippet of text, and the author. That way, the annotations still contribute to the co-occurrence graph.
When the link to the post is clicked, it would still take you to the right URL, which you can then read if you have permission.
As I see it, there is really only one major problem with this. Every post need to be associated to a user in the RyderEx graph, and if we want to hide the real association we would have to create dummy users to hold ownership of protected posts. Either we create one dummy user that owns all redacted posts or one dummy user user that owns any protected post. That way, users with protected posts would be represented by two nodes in the participant graph - one with their real username, and one under a pseudonym.
True, but that would make the dashboard a lot less useful for community managers and outreach efforts.
I’m going to try the thing I proposed above, I think it will not be too hard to modify my script to do that.
Isn’t this a little bit of a play for the galleries anyway? Seeing that the only thing you need to to find out who wrote a post is to enter a string from any post into google, or the Edgeryders search function itself?
Even if you pseudonymize all users and redact content and titles of protected posts, it will still be very easy to figure out which user has written content in protected categories that has been annotated with “criticism”, “police” and “corruption” by doing the following:
Find the redacted post that has been annotated with “criticism”, “police” and “corruption”.
Find the pseudonymized user who has authored that post.
Find other posts by that user that are not protected.
Search for strings from those posts on Google or Edgeryders search to find the real user account.
In a sense, yes. But it seems you are thinking about security, whereas we were thinking about consent. Of course Edgeryders can never guarantee full anonymity, we say it right at the front door. The use case goes like this:
I agree to participate in research, write, my posts get coded and exported, etc.
Five years later, I decide to delete my user and content from Edgeryders.
The content disappears from Edgeryders, but can still be found on Zenodo, but attributed to @anon12345.
Marco felt it was a reasonable compromise.
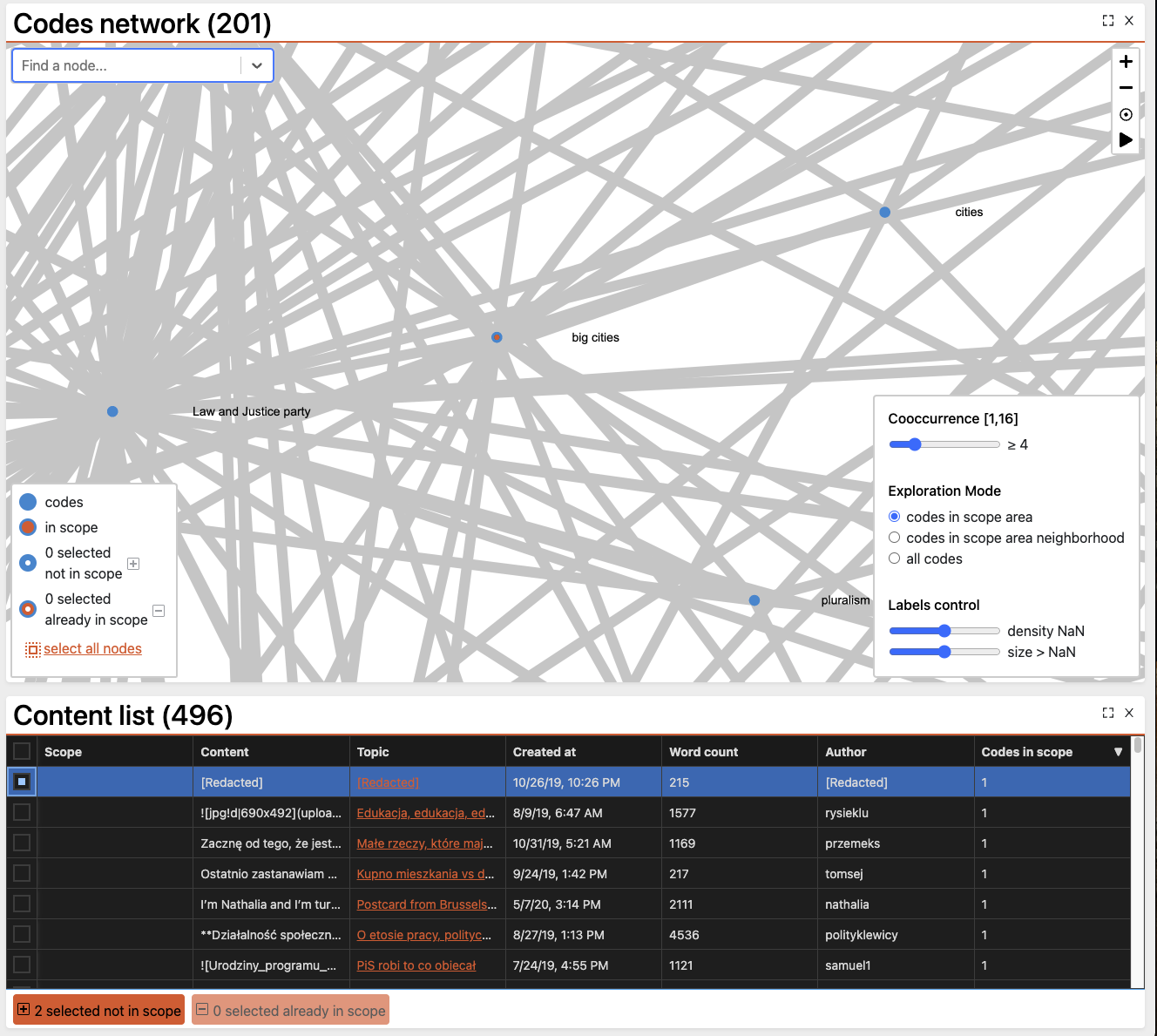
On another note, you once told me that the social network is induced like this:
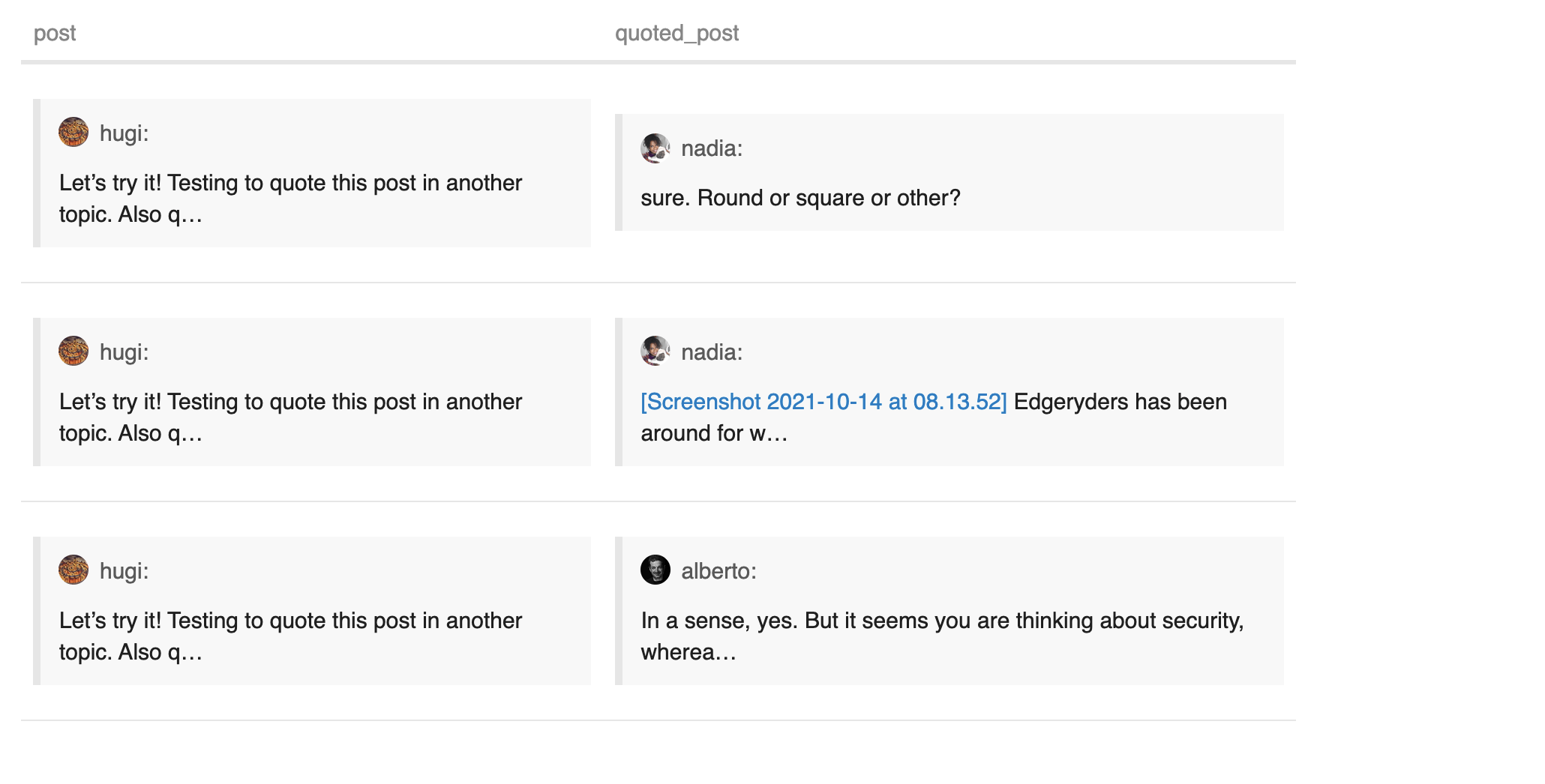
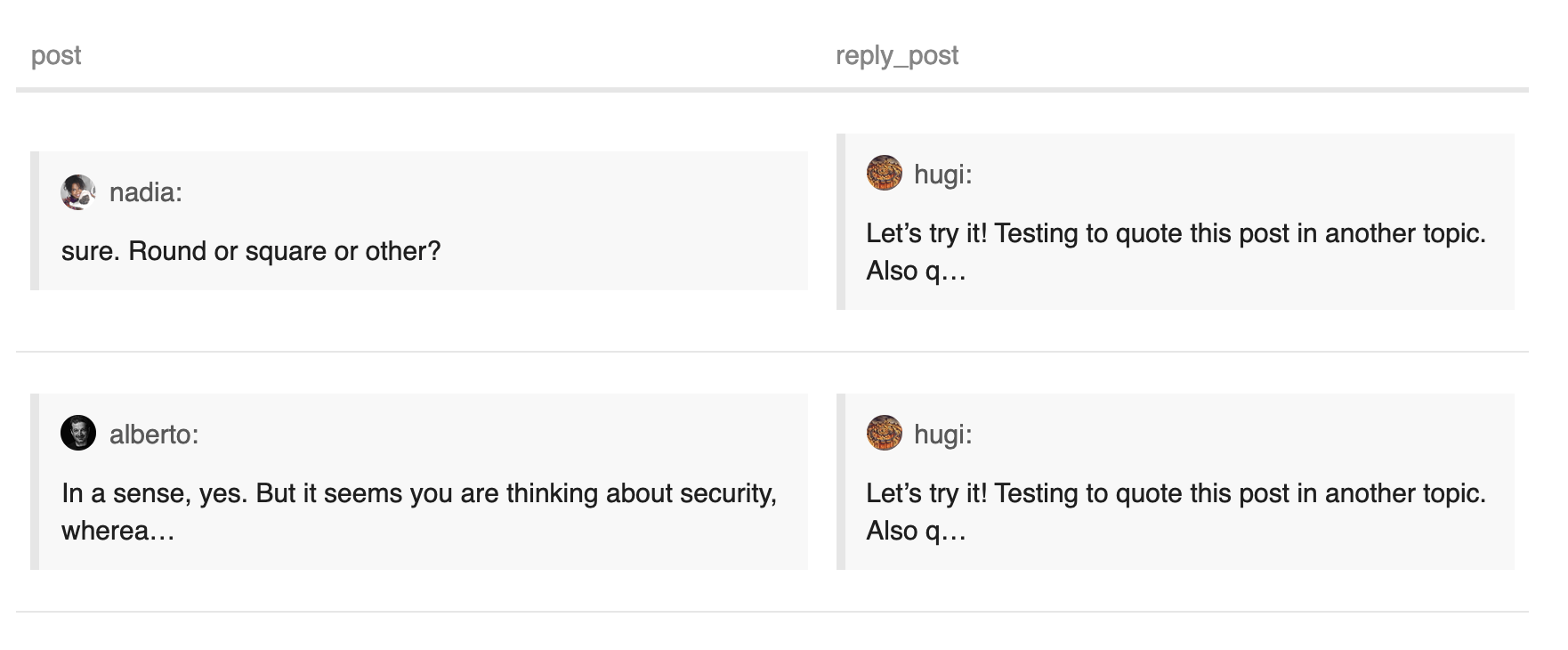
Post A is a reply to post B => link from user a (author of A) to b (author of B)
Post A contains a quote of post C => link from a to c
Post A is just a reply to topic ? link from a to the author of the first post in the topic.
What happens if post A is a reply to post B and it contains a quote from post C? Or if someone quotes posts of several different authors?
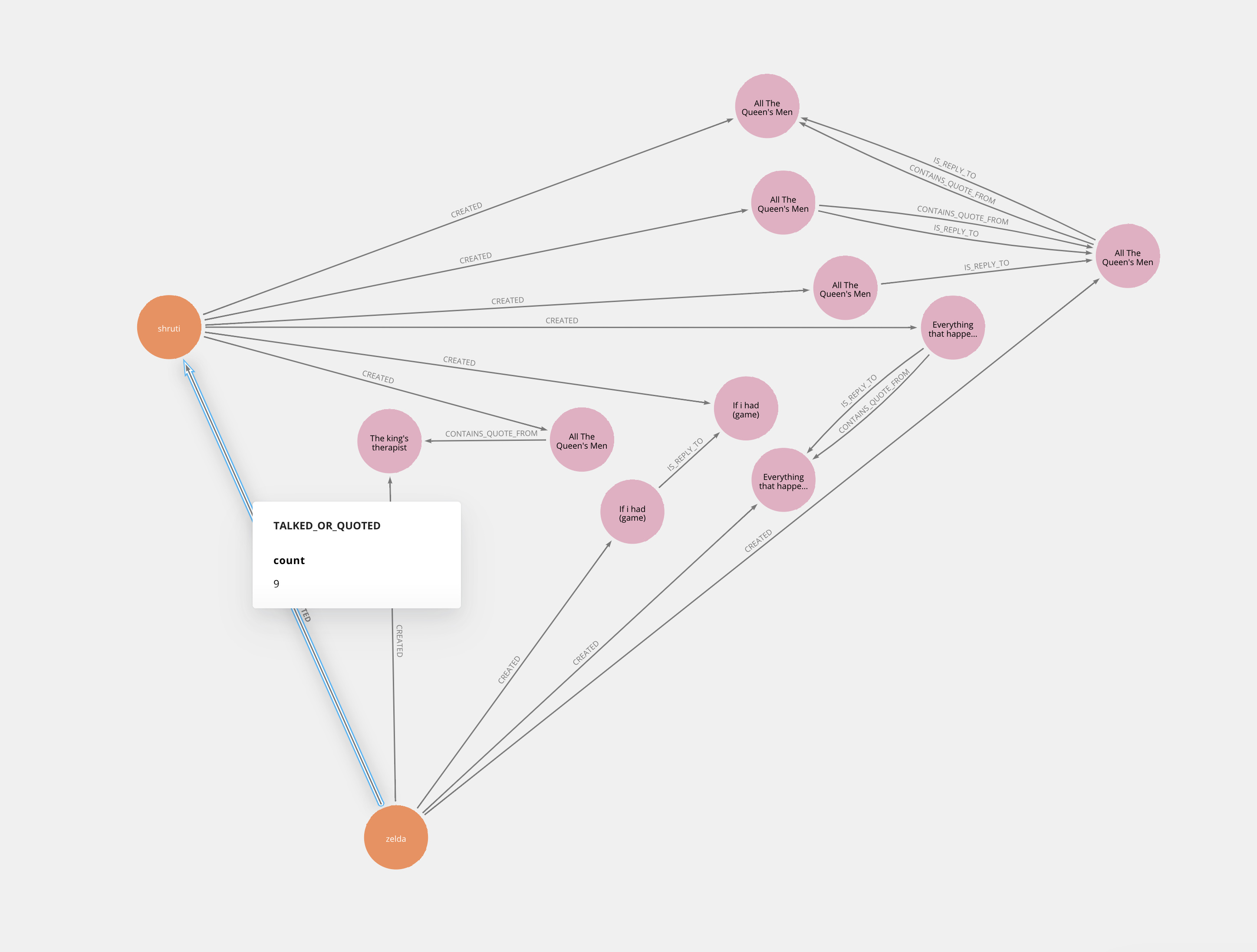
Discourse counts quotes within a thread as replies to the quoted posts. This means that a single post can be a reply to multiple posts at once.
RyderEx combines the quotes and replies into a single relationship between participants to count participant interactions. However, I now realize that the interaction counter on that relationship is wrong since it will count two interactions when somebody makes a quote which is also a reply. In the example above, the TALK_OR_QUOTED counter in 9, but it should in fact be 6.
Furthermore, Discourse does not consider a post A in topic X with first post Y a reply to topic Y. At the moment, neither does RyderEx, though this is pretty easy to change.
I have now pushed an update that enables pseudonymization, the inclusion of protected content, and redaction of protected content titles and text on a platform level. This means that BBU, Blivande, and Edgeryders.eu can share the same installation and still have different settings.
Since the POPREBEL corpus includes quite a lot of protected content, I think this is a good compromise for now. I personally think that the pseudonymized usernames are a bit silly given how easy it is to circumvent by just clicking a post, but I suppose it gives a little extra layer of protection by obfuscation.
These are the current settings for the platforms:
Edgeryders dashboard Usernames: Pseudonymized Protected content: Included, with text, titles, and annotations quotes redacted Consent policy: Only includes the content of users who have passed research consent funnel
Blivande dashboard Usernames: Original Protected content: Included, with text, titles, and annotations quotes redacted Consent policy: Assumes consent of all registered users
BBU dashboard Usernames: Original Protected content: Omited Consent policy: Assumes consent of all registered users
I noticed that the POPREBEL corpus has quite a few codes prefixed with *.
There is a function in the RyderEx import script that allows defining a list of prefixes, and any code with one of those prefixes is omitted along with all of its annotations. This config and list of prefixes is applied on a platform level. Let me know if you want to start using a prefix to omit annotations from the graph.
Adding or removing a prefix is very easy, and rebuilding the database only takes a couple of minutes.
As we finish the NGI and the POPREBEL report we will know more about this, and, if we are lucky, perhaps we can even pick a single measure, so it can make sense to pospone this development to late 2022.
However, it would be nice if we could get the single measure of link strength to be consistent with the methodological discussion we had with Jan and the ethnographers. This would have the extra advantage that we can get all of them to use the software in early 2022, and we would learn a lot from that.
Is there any way you could build edges based on a count of the occurrence of the two codes within a single post? If code1 occurs, in the same post, n times, and code2 occurs m times, then the contribution of that post to the weight of the code1 <=> code2 edge would be m x n. This would make RyderEx uniform with the analysis we are doing now (example).
Another question. How does Ouestware document the code? To be usable by someone who is not us, RX needs a good manual, at least. With Edgesense we relied a lot on inline help, and I wrote all the help text myself, inserting it into the appropriate places in the code repo. That was a simpler software, though.
It turns out the filters are a little more complicated than I thought, and I would have to do more digging to make sure the change gets applied everywhere. It ended up breaking the graph filtering, so adding users to a scope and seeing the code graph specific to only those users no longer worked.
Database connection is set up now for all three platforms accessed by RyderEx. I have run graphryder-import-psql.py successfully. Runtime is around 150 s, just a few seconds slower than with a local database connection. And wayyy faster than old Graphryder, very nice
I still have to do some security optimization (read-only user, encrypted connection) tomorrow. But connections are already restricted to a single combination of database, user and IP, so it’s ok for now.
P.S.: RyderEx drawing routines incl. zoom are very smooth and fast for a web-based application. Wondering what’s under the hood for drawing? WebGL?
@hugi, the coding work in POPREBEL is nearing its end. I would like to deliver them a graphryder dashboard, ideally with the “right” measure of link strength. We have,as I recall it, already refinanced that work (you + Ouestware) in internal budget reallocation for POPREBEL (cc @marina). What do you think about implementing it in the next month or so?