Some time ago we agreed to schedule our kickoff meeting at the same time as the Living On The Edge 5 Edgeryders event, to take advantage of that particular effort. That means 25-28 February 2016.
What’s missing is a schedule of our activities, and time is getting tight if we are to engage with other people out there (and we are). I propose we do two things.
One day of talking. This would be a closed-door meeting for the consortium only. Closed-doors means we all are welcome to invite external people (for example with a view to future partnerships), but other than that we will just have a regular meeting. We will cover collaboration procedure and tools; admin; and detailed planning on the first six months of so of the project. We will also schedule the second consortium meeting.
One day of doing. This would be an open-door event scheduled within LOTE5, which anybody can attend – the more the merrier. Call it the first of the OpenCare onboarding workshops. Here we have several possibilities. I see at least three very attractive things we could do:
Masters of Networks. A hackathon based on network methodology and data. @melancon and myself have some experience in delivering those – of course we would need care-related network data. See this short video to get an idea of what happens at Masters of Networks events.
A workshop on designing community-driven care services. This could be led by Ezio Manzini.
One or more talks to present the project by conveying the urgency of the issue. I would love a talk by @markomanka on healthonomics, for example – how incentives are very seriously warped in this field. @Lakomaa might also have something to say in this respect: additionally, in Italy we found a health economist (works as a comptroller in the Italian public health system) called Simona Ferlini who has a lot of insider knowledge to contribute.
My preference would be for doing all of the above, and perhaps even more. Maybe @Costantino and @zoescope can think of some maker-related stuff to do? But of course these things eat up time. There is no point in doing a hackathon in less than a full day’s work, for example. So, if we do everything, the program could look like this:
Closed door meeting: 24th February.
Masters of Networks: 25th of February, within LOTE5
Design workshop and talks: 26th of February, within LOTE5.
Also ping @Luciascopelliti, who could bring the point of view of precisely how welfare is failing in the city, and what people are doing to fix the failure.
Wow, thanks for putting that great and stimulating video – and I am not saying that because I appear on the screen. I think it is a good way to publicize the event and attrack more people.
My experience is that MoN need at least two days to produce anything juicy. The first day is usually dedicated to handle data, trigger and massage ideas, the second day is often useful to take a distance, have a second look at the available visualizations (often made late at night after dinner …).
We usually work around network data provided by domain experts, together with questions they have around their communities (part of the game is to properly spell out these quesitons).
We could also try to put our hands on welfare data – would that be available through national opendata portals, for instance? We can work network data and any other kind of data, and hopefully mix them.
So my question/proposal is to have MoN spread over Feb 25 ad Feb 26. That being said, it may be possible to squeeze things into 1 1/2 day to keep everything within 3 full days ?
WeMake can contribute with a talk to present some interesting projects and approaches around the topics of care and makers culture.
As the plan is already pretty interesting, do you think there will be time to have an additional hands-on activity? (minimum 4 hours for an introduction on a technology and its potential - or 8-10 hours if we want to try and prototype something).
If there is time, the easiest thing (without having the machines of a fablab) would be to bring to Brussels 10 Arduino kits we usually use for our workshops on which 20/25 people from different backgrounds could be activated in understanding what does it mean to work on smart objects.
I understand we need to find a viable compromise and share time between all activities. But I personally would benefit from getting involved with what you guys do. Because “doing things” is at the center of OpenCare, I am ready to compress the MoN part and mayeb keep it to a introductory activity to future MoNs …
I would agree with @melancon: let’s keep the MoN to a demo/introduction for future activities. Could data sources like the following be useful for the demos?
Concerning my lecture, there is a lot we may want to discuss: from the incentives you mention, to the warped ways we account for the costs… The role of informal care, and the exorbitant overheads of bureaucracy in institutional care…
But let me ask, before I promise anything: How much time would you plan on dedicating to each lecture? Shouldn’t we somewhat align the topics to the day we insert the lectures in (as inspiration for MoN, or for the design hackaton)?
I had a quick look at the data, I could download datasets from the OECD, I saw there a tons of data on the WB portal, I have some ideas what GapMinder offers.
The essential ingredient I need to be able to build an interesting and useful demo is “questions”. What type of information/knowledge may we expect to get out of these datasets? We could “replay” things similar to GapMinder, but then how better would that be than simply listening to Rosling’s videos (and he is a heck of a speaker)?
How can these datasets be used to reveal something useful for OpenCare?
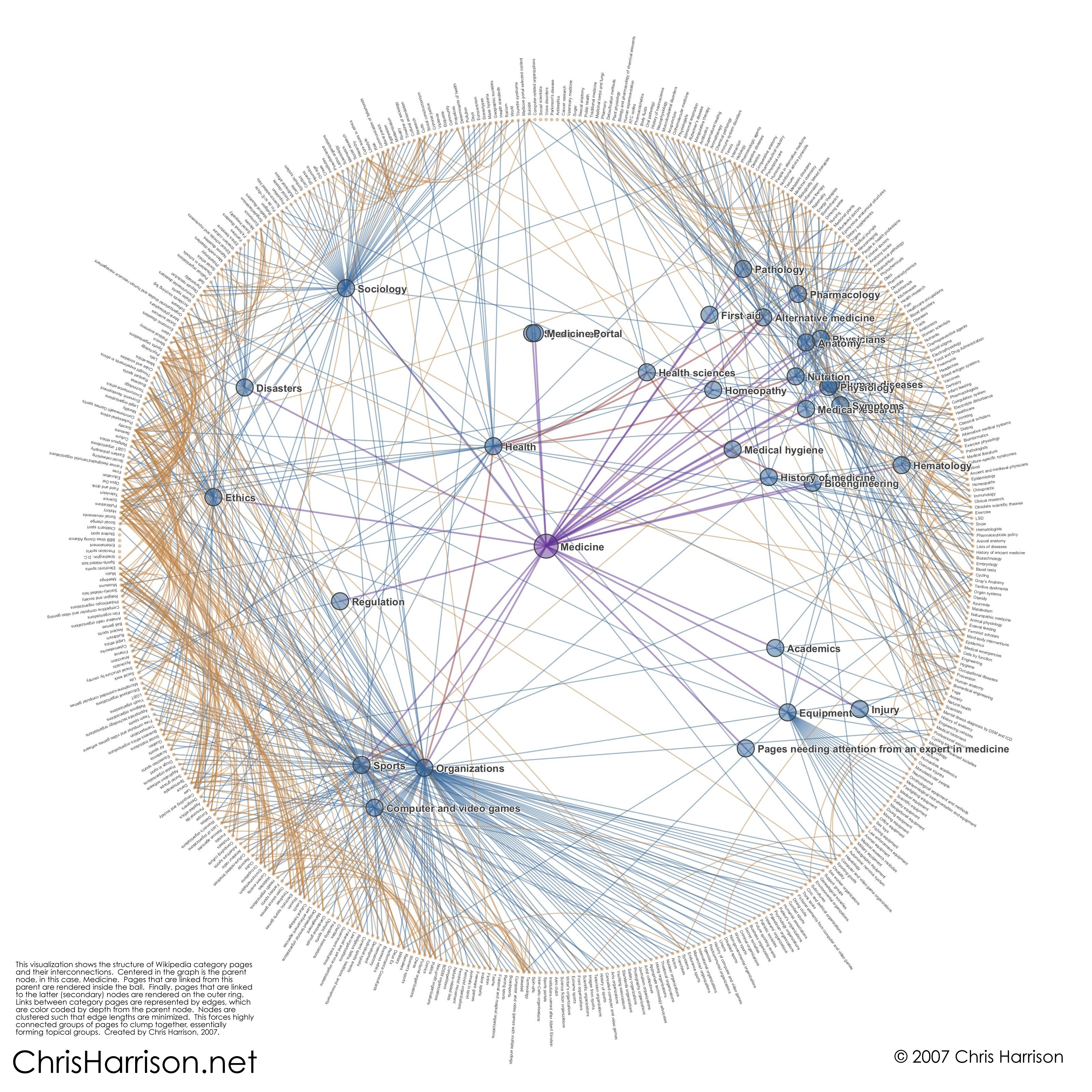
We have been thinking about Wikipedia pageviews as an indicator of (partial) disintermediation in diagnosis; people look up pages on medical condition to make sense of the symptoms they feel.
A network science version of this would be to:
(basic, but by no means easy to implement) draw a network of health-related Wikipedia pages (page A in connected to page B if it contains a link to page B). This can be seen as a representation of the concept space as seen from "the crowd".
(advanced) draw a network from a comparable academic dataset. This can be seen as a representation of the concept space as seen from credentialed experts.
In facts, while I was trying to figure out what they could share with us, I haven’t been able to find any documentation of how they would store less-than-anonymised-and-aggregated data about traffic…
I see your point @melancon, but let me get this straight: are we still planning to give a demonstration of the techniques arsenal, or are we aiming at answering actually meaningful questions?
I am afraid if we embark in the second, not only will it take a bit more to figure out what to ask, but the MoN will fall back to the initial condition of requiring at least a couple of days to produce anything better than a shabby collection of conflicting-half-thought visualisations (Hans is not just good because of the questions)…
The value of visualization strongly depends on the motivation one has to explore the data. Dozens of different visualization can be built form the same dataset.
WHat I am suggesting is not to undertake a quest for question on the occasion of the workshop, but to have them beforehand so I can prepare a “show” that would demonstrate the arsenal, based on real and convincing motivations.
I also had a look at what could be done using the wikipedia pages, as suggested by Alberto. I am still unsure about the feasibility (putting our hands on usage statitics could be quite difficult).
So, I am still interested in hearing people about how the oecd data could be useful for OpenCare.
So we both agree wikipedia is shaky ground… I will try to contact somebody at the Wikimedia Foundation to ask them whether the data could even be collected in the form we might need, but not for the LOTE5 deadline.
I will try to think of something about the OECD exercise instead, to contribute to the “brainstorming”
Page view stats are easy. Wikipedia maintains hourly dumps of all page views stats (documentation).
The difficult part is disentangling the pages about care from the pages about everything else. This cannot be done directly (it is not a field of the dataset); it has to be done by association. There are two ways to do that:
by ontology. There is a Wikiproject Medicine: https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Medicine which even maintains its own statistics page. It follows that there is somewhere a piece of code that knows how to tell pages which are part of this project from pages which are not ("Medical articles are determined to be those NS0 articles tagged within the scope of WP:MED according to a category dump at the time of report generation"). Somewhere, someone has that code and could give it to us.
by emergence, based (you guessed it) on the network of links connecting different entries to each other. Within Wikipedia, you can expect to see pages about medicine to cluster into a community of pages more closely connected to each other than to the rest of the encyclopedia. Something like this seems to be done by tools like WikiLoopr (try it: for example http://www.wikiloopr.com/diabetes)
There are at least three interesting questions concerning OpenCare that you could address by looking at Wikipedia data:
Which entries are people looking up (hint: not necessarily the ones you would think)? Is that indication of self-diagnosis going on? What can we learn about that (example: are some countries more inclined to do that than other countries?). This is a non-network question.
How does collective intelligence in Wikipedia relate pages about care to each other? How does this compare to a similar web of relationship, but derived from academic datasets? This question pertains to networks of documents (Wikipedia entries) connected by hyperlinks (somebody did it in 2007).
How does collective intelligence proceed in building that content? This question pertains to a network of Wikipedians connected by affiliation (having edited the same page).
There are many visualizations to look up for inspiration.
What I am not sure of is the following: since the traffic is only saved as aggregated data (as in “number of page visualisations”) rather than in detailed form (as in “the same anonymous user has visited the following pages in sequence”), how do we build a meaningful network being blinded to their co-occurrence?
…so we have, on one side the visualisation load, and on the other the content relatedness… the latter being a bit less an expression of crowd intelligence than search co-occurrences would be, since the entries in wikipedia (and the edits) tend to be subdued to references…
If you re-read my comment above, @markomanka, you will see that data on pageviews are non-network (item 1). Data on patterns of linking across entries (2) and collaboration on different entries (3) naturally induce networks.
…I am just unsure how would we interprete the possible analyses, being unable to access the hidden confounders acting on them…
…should we maybe think of a bootstrapping pipeline, testing several (realistic?) weightings/architectures of confounders, to get a distribution of trustworthiness of the models (and their interpretations)?
Just running one analysis on the data doesn’t seem to me any better than just formulating an informed prejudice… maybe different, but not better.
@markomanka, @melancon and anyone else interested: let’s move the debate on MoN to a different thread. This one has become long, messy and difficult to search.
I like the 3 days structure, day1 closed door, day2 MoN, day3 Ezio Manzini ws + our contributions.
I’m not sure about dedicating 2 days to MoN but, even if I watched the video, I’ve never experiences something similar. I definitely wouldn’t miss Manzini ws on designing community driven care services!
I can bring with pleasure (afternoon day3 if I understood well) the point of “welfare in the city” and the challenging that the public system is facing!
We have a fundamental tradeoff. On the one hand, we can reach the maximum amount of people by doing several things in parallel: data geeks might like MoN better, whereas designers will flock to Ezio etc. But on the other hand, we need to learn from each other and share tools, and we cannot do that if, say, Marco is talking about healthonomics in one room at the same time that Zoe is hacking devices in another room.
I recommend prioritising mutual learning over engagement. Doing things in sequence, which is normally inefficient, in this case is good (we will probably increase work in parallel as the project progresses). So, two possibilities:
The @Luciascopelliti ticket: day one closed doors, day 2 MoN reduced to one day, day 3 other contributions, cast as LOTE5 events to piggyback on the communication infrastructure. This is actually my preferred outcome provided that MoN can be pre-produced a lot. For example, this was made in one-day hackathon, but the main graph had been pro-produced; and that meant finding the data, downloading them, cleaning them, and writing the Python script that put it in network form. But I am but a mere network apprentice, whereas @melancon has wizardly powers and can do that stuff in his sleep , so this may actually be doable.
Posponing MoN to the second consortium meeting (Bordeaux in May?) to focus on workshop-y stuff and talks.
The third alternative, that of doing a two-day MoN but nothing else, I do not really like. I love networks, but I do not think non-geeks need some extra love at this stage. Do you agree, @Noemi?
@markomanka and @MassimoMercuri: whatever you guys do (Lego is excellent, BTW! Who does not like Lego?) will be pushed out as part of the LOTE5 event. It comes down to: we can negotiate with the LOTE5 team the time and facilities needed for each session.
@zoescope: do you want us to look into an alliance with the Brussels makers? This seems like an easy win: equipment is there and we have more makers coming into contact with the Belgian makers. Perhaps you know some already – and we do know @Thomas_Goorden.
All, great to see enthusiasm jumping through the roof. Like @Melancon, @zoescope and the rest I too am curious to dip my feet into as many and diverse talks and workshops. A lot of us in OpenCare don’t know each other’s work except in “keywords”, and the more we can learn the more useful for the different takes on care to make sense taken together, which is why we have a consortium in the first place.
I’d like to propose a small adjustment: it seems there’s agreement for Day 1 to be meeting-style. Given that Day2, the 25th is the launch day for Living on the Edge conference, we have to consider a broader audience making contact for the first time. It would be great to use it as OpenCare context setting and public launch: an overview on care fails rather than data. I suggest planning Manzini’s, Lucia’s, Marko’s and other talks+ maker workshops from the team here, and leave MoN for 26th, when it can run in parallel with other Lote sessions.
@markomanka the easiest to manage is if you let us know how much time you would need at a minimum, rather than the other way around. If you know that you are giving a talk on the day of OpenCare official public launch in front of a v mixed audience, what picture would you like to paint the most?


{kind=link}