Statistics are easy
Page view stats are easy. Wikipedia maintains hourly dumps of all page views stats (documentation).
The difficult part is disentangling the pages about care from the pages about everything else. This cannot be done directly (it is not a field of the dataset); it has to be done by association. There are two ways to do that:
- by ontology. There is a Wikiproject Medicine: https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Medicine which even maintains its own statistics page. It follows that there is somewhere a piece of code that knows how to tell pages which are part of this project from pages which are not ("Medical articles are determined to be those NS0 articles tagged within the scope of WP:MED according to a category dump at the time of report generation"). Somewhere, someone has that code and could give it to us.
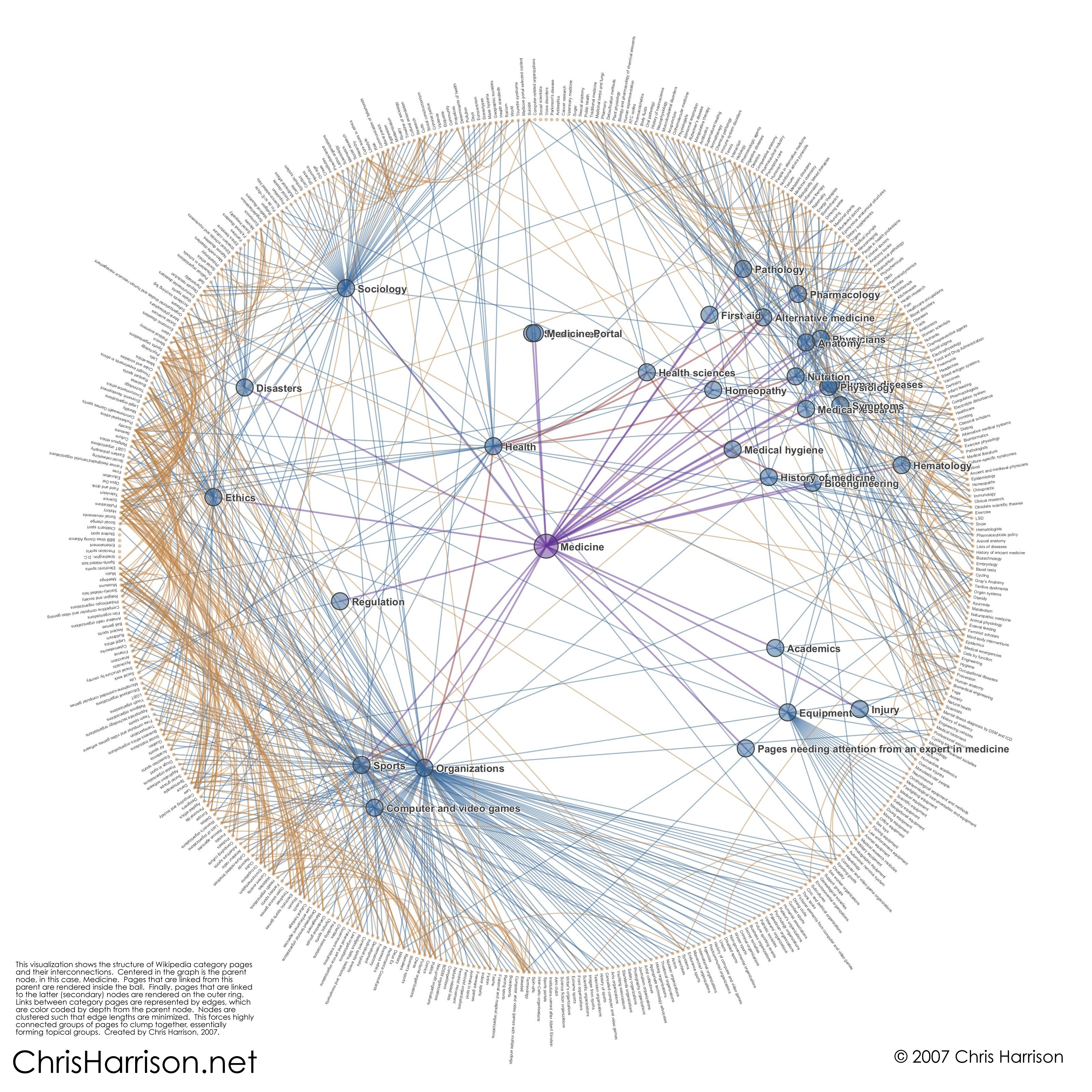
- by emergence, based (you guessed it) on the network of links connecting different entries to each other. Within Wikipedia, you can expect to see pages about medicine to cluster into a community of pages more closely connected to each other than to the rest of the encyclopedia. Something like this seems to be done by tools like WikiLoopr (try it: for example http://www.wikiloopr.com/diabetes)
There are at least three interesting questions concerning OpenCare that you could address by looking at Wikipedia data:
- Which entries are people looking up (hint: not necessarily the ones you would think)? Is that indication of self-diagnosis going on? What can we learn about that (example: are some countries more inclined to do that than other countries?). This is a non-network question.
- How does collective intelligence in Wikipedia relate pages about care to each other? How does this compare to a similar web of relationship, but derived from academic datasets? This question pertains to networks of documents (Wikipedia entries) connected by hyperlinks (somebody did it in 2007).
- How does collective intelligence proceed in building that content? This question pertains to a network of Wikipedians connected by affiliation (having edited the same page).
{kind=link}
There are many visualizations to look up for inspiration.
Any of this is to your liking, @melancon, @markomanka and all?