thanks for your fast reply and for asking explanation about my long comment.
If the whole network is already updated with coding by @Amelia you might pick up the whole, otherwise only the part already mapped by codes.
About the files…good question! i would like to go on with the experiment and start from the highest score of co-occurences as in Milan splitting between posts and comments. I have no clue about links, but the path made up only by comments by Tulip could be a interesting trek to follow. I’m just guessing how to read the collective text using netwokr analysis as a visual index.
If you may provide me by e-mail of a sample file (only comments with highest co-occurrence present, just to say) i try it and see what happens.
Thanks for following my ideas and providing your precious support.
Basically you’d need to select threads that have at least one annotation associated to them.
This is because:
Amelia has organized the coding by thread. She starts with a post; then she codes all the comments of that post; then moves on to the next post, etc.
Some posts and comments will be unintersting, and receive no annotations at all – but they still have been coded! This is. for example, the case with the many comments I leave asking for questions, or clarifications etc.
So a good rule is:
A post or comment C is considered as coded iff it there exists an annotation the entity_id of which refers to a post or comment in the thread to which C belongs.
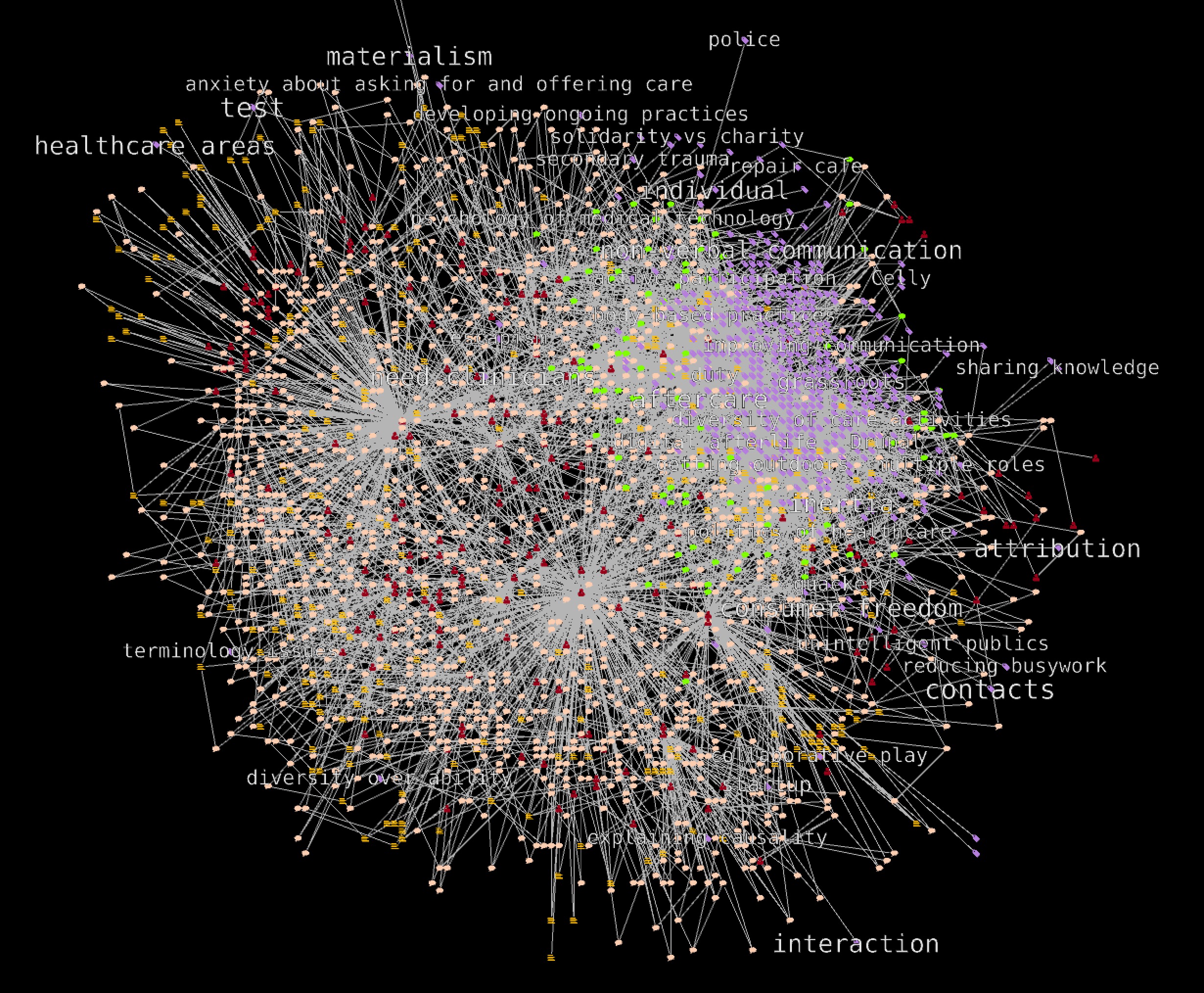
@Amelia is still working and tagging data. Posts and comments in the data we use do not all have been tagged. I remember showing an image of the full network (people, content and tags) that showed the portion of content that Amelia had already tagged (purple patch on the right upper side of the picture).
Maybe my request to @bpinaud is too early, but it is worth working on some hypothesis to validate and calibrate a useful model of analysis to access later on the complexity of tags from OP3NCARE network of posts and comments. Such early model will be useful for experiments to check if it works and to inspire others.
It currently looks like I will be talking to/working with Dan from another online company-community-hybrid.
They have a couple of years worth of co-creation conversations that would perhaps be an interesting addition to another CAPPSI submission. I’ll be meeting Dan in January and probably have some time to talk this over. Especially a summary of technical requirements would probably be helpful in determining how realistic vs desirable such an excercise would be.
I’m just now starting to poke around the academic community they already have some connections to in the US. They do have a (somewhat) independent legal entity in the EU though (could be relevant for h2020 purposes).
The EU entity has English, French & German language skills and is based in Berlin. A French one is in the making afaik.
Most intense meeting time will kick off in 2nd week of January.