My mistake, thanks for pointing it out, I forgot to change the date. I also rebranded the version 2.1, it should not have been 2.5!
I confirm the data in there are updated to yesterday.
My mistake, thanks for pointing it out, I forgot to change the date. I also rebranded the version 2.1, it should not have been 2.5!
I confirm the data in there are updated to yesterday.
Found that code #6816 does not exist. It is associated with post 63558.
May we have a new export? @amelia did a lot work on the dataset.
Hi @rebelethno ,
what time today are we re-grouping for the wrap up?
At about 14:30 in the main room!
@alberto, possible to have a new export of the codes?
New nicer version on the latest export on zenodo:
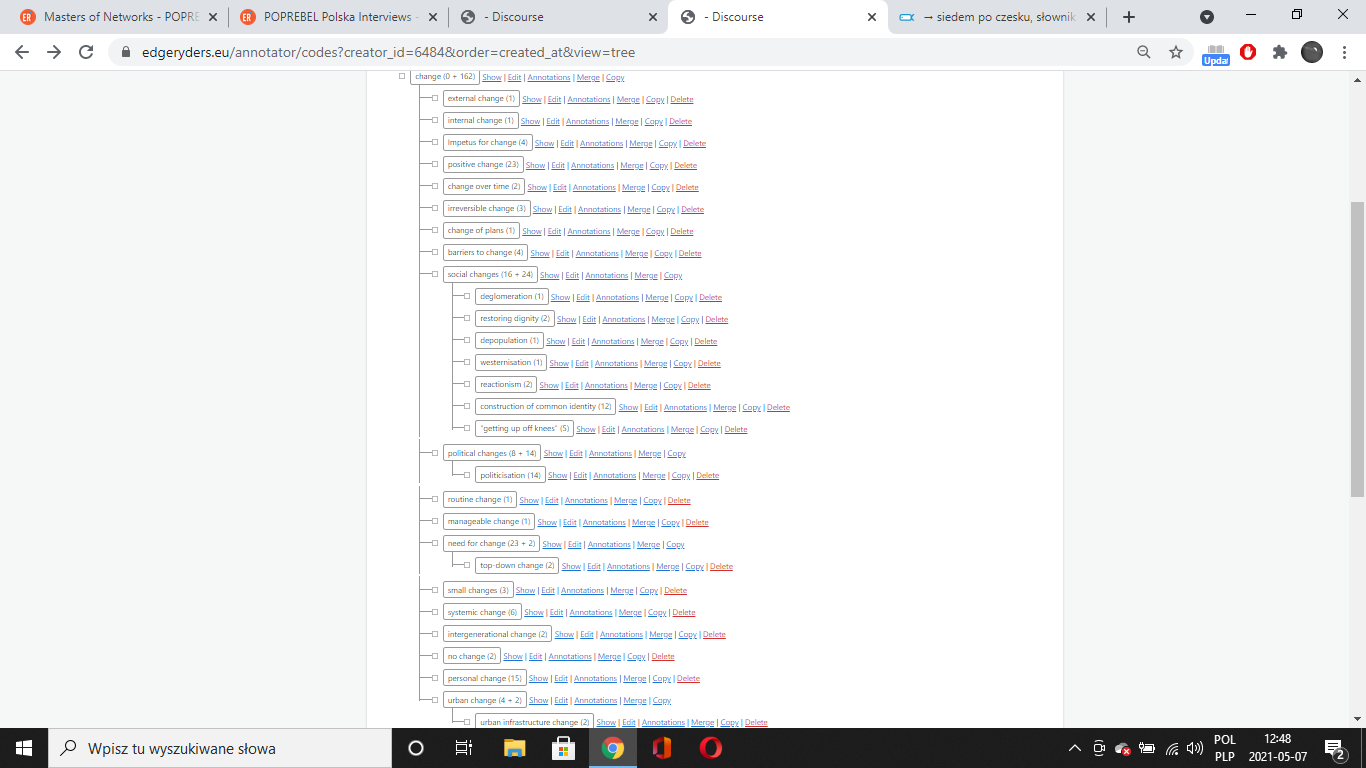
as a reminder : I took all posts in a chronological order. Then I built the code co-appearance dynamic network with a threshold>=5 in the example of the image and the video. The video shows a very basic animation of the graph construction (having a nice and smooth animation is a difficult problem). The tulip file contains 180 subgraphs. Each subgraph can be visualized and studied. The python code and the Tulip file are here: https://github.com/bpinaud/MoN5
@rebelethno, we are now back in the main room! Please join 
@alberto May we have again a new export of the data? @amelia just finished to edit all codes. My graphs will look much better.
Some of Amelia’s notes from 3 straight days of categorizing, merging, and general cleanup of our codes (and big thanks to @Jirka_Kocian and @SZdenek for all the help) :
All the codes are now visible on one page!!! hoooraaaay!
“Actions” codes are going to be useful, in my opinion, and we should try to format them the same (e.g. in “gerund” form). same with Resource Needs and Problems. Could break Actions down into things like “coping strategies” and “solutions” or something
People and Identities has a few different sub-cats
Places also has a few subcats – proper nouns and more general places (e.g. villages, cities).
There is work to be done cleaning up and merging codes – we could condense many together. also, quite a few could be deleted as they are too vague.
Now when we code, we should make sure to add new codes to the new categories.
Other note – we really need a way to only see annotations done in POPREBEL – it’s confusing to see a code with 50+ annotations only to realise that only 2 are from POPREBEL. (@hugi, @alberto, any thoughts on how we could do this? The mixing in the backend is getting very dicey.)
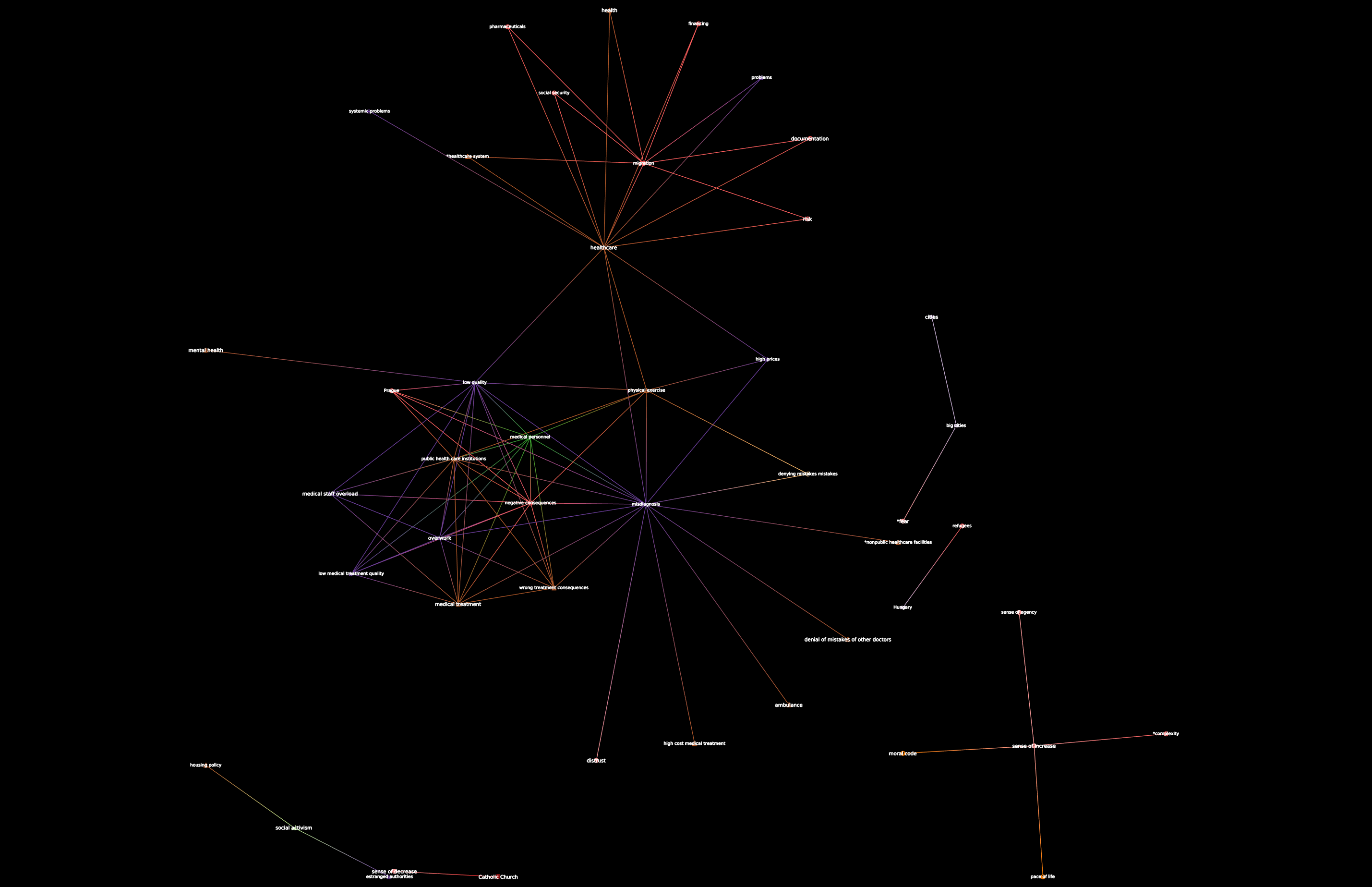
Check out @bpinaud’s great visualisations based on these new cats as well, and with the ability to see the codes unfold over time as new posts are added. Let’s discuss in our next bi-weekly!

Here is a early version of the virtual exhibition of the three data sets of data and the fun video about “walking and stomping on data” from opencare
I’ll be happy to continue working on this with you all and improve the visualizations. The code is on github: https://github.com/bpinaud/MoN5. It is the first time I used pandas for dealing with csv files. That is great. Usually, I let students do the work…
Indeed! I have my own source of confusion: the API endpoint for codes carries the number of annotations the codes has been used in. But that number is platform-wide, not corpus-specific! So, the code migration in NGI appears to be very important, appearing in many annotations, but most of those are not in NGI. @hugi I believe a check-in on multi-tenancy is in order.
Done now. Same Zenodo page, version 2.2.
Used the new data. Now 185 subgraphs with threshold=5. New tlpx file uploaded on github (https://github.com/bpinaud/MoN5)
Yes, this is because it was a big open care code!
There are no corpus-specific aggregations in OE, as far as I know, and never have been. All corpus-specific calculations happen on the Graphryder end, but those are not available to you through the API. In the Neo4j database (without multi-tenancy), you just count the number of ‘REFERS_TO’ edges coming in to a given code node. This is a very cheap operation, almost as cheap as storing it in a property.
In the multi-tenant Graphryder Neo4j database, we will store the number of annotations per code per corpus as properties on the IN_CORPUS relation between codes and corpus nodes, where ”corpus” is just a special label applied to tag nodes that define corpora. You will be able to access this through the GraphQL API, along with other pre-calculated data like the co-occurrence number per code pair and corpus.
That is just wonderful work, y’all!
I couldn’t attend the event because of a conference at my uni, but it looks just beautiful now!
I’m getting down to going through all the novelties.
<3
@rebelethno
Ok, so I’ve had a look at the meta “Z” categories and it would be of great use to us, I think, if we could apply the “sort by: number of annotations” tool to their entirety. For now it seems to work only for the annotations associated with a code that a given category derived its name from.
E.g. When aplying the sort by: number of annotations to the ethno-poprebel corpus we get COVID-19 with a 100 annotations for the COVID-19 code + 235 annotations for its children.
Next comes Emotions with 3 + 958
Then Ideology with 2 + 655
And so on.
Thus, maybe we could, if possible, also sort the categories by their total number of annotations (parents + children)…(on the other hand, with just a few of them, it’s not a big deal really, since if you click on them, they fold and you get this:
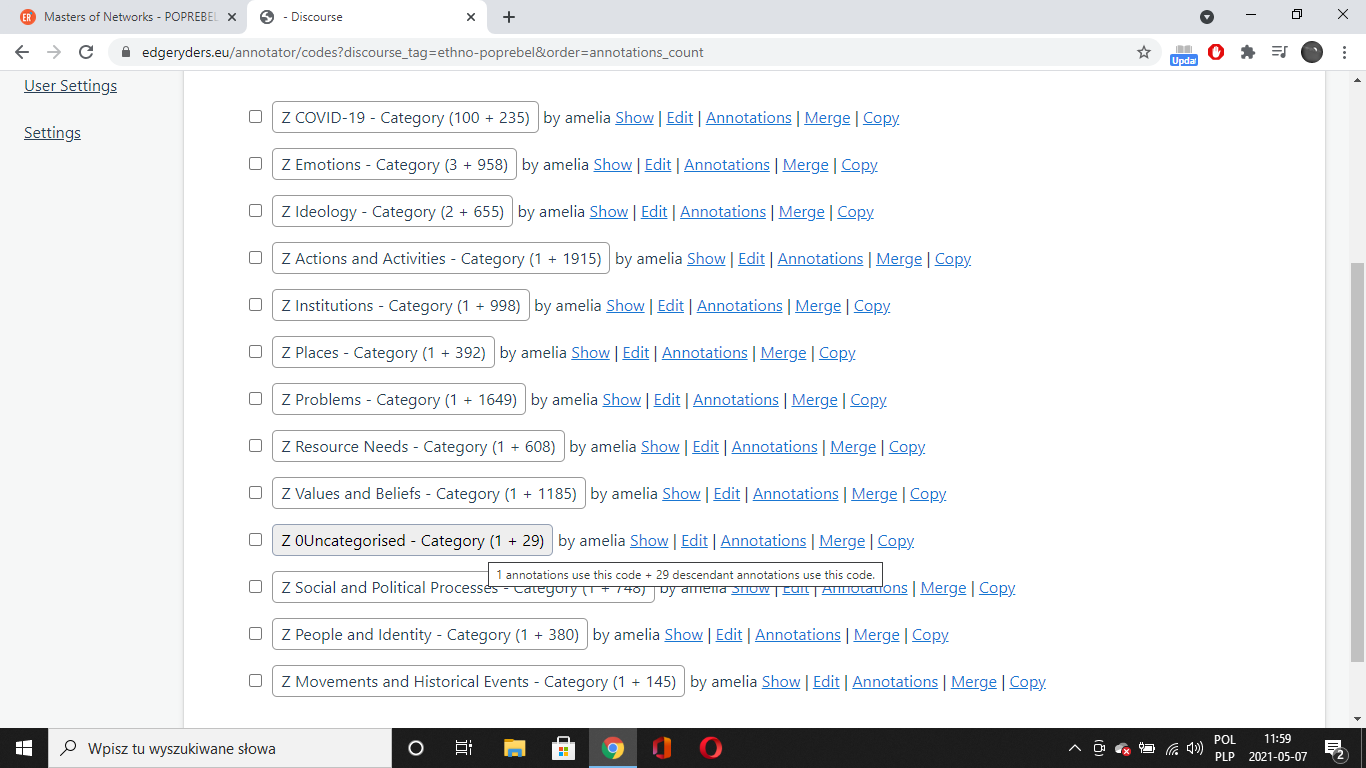
Maybe it could also be useful (again, if possible) to introduce a “sort by: number of children” option? What do you think?
I feel that seeing a total number of annotations could give us a glimpse into how salient certain topics are (once we sort the issue with the number showing all possible annotations, not just those for poprebel) and by looking at the number of children we could maybe see how informed/thorough/nuanced the conversation on a given topic is?
Like, say, if we had 335 people just mentioning Covid in their stories, we would get 335 annotations under the Covid code/category. However, if the same number of people speaks of:
That is, of course, under the proviso that the variance in the number of children is not just due to the coders’ bias. It seems rather clear to me that one coder’s interest in, and knowledge about, say, various aspects of the pandemic, will probably result in a greater number of children - they will be able recognize and distinguish between a greater number of different phenomena, name them and create specific codes for them.
PS Look at that curiosity - it shows zero codes created by me under poprebel; they appear only under Any Discourse Tag.
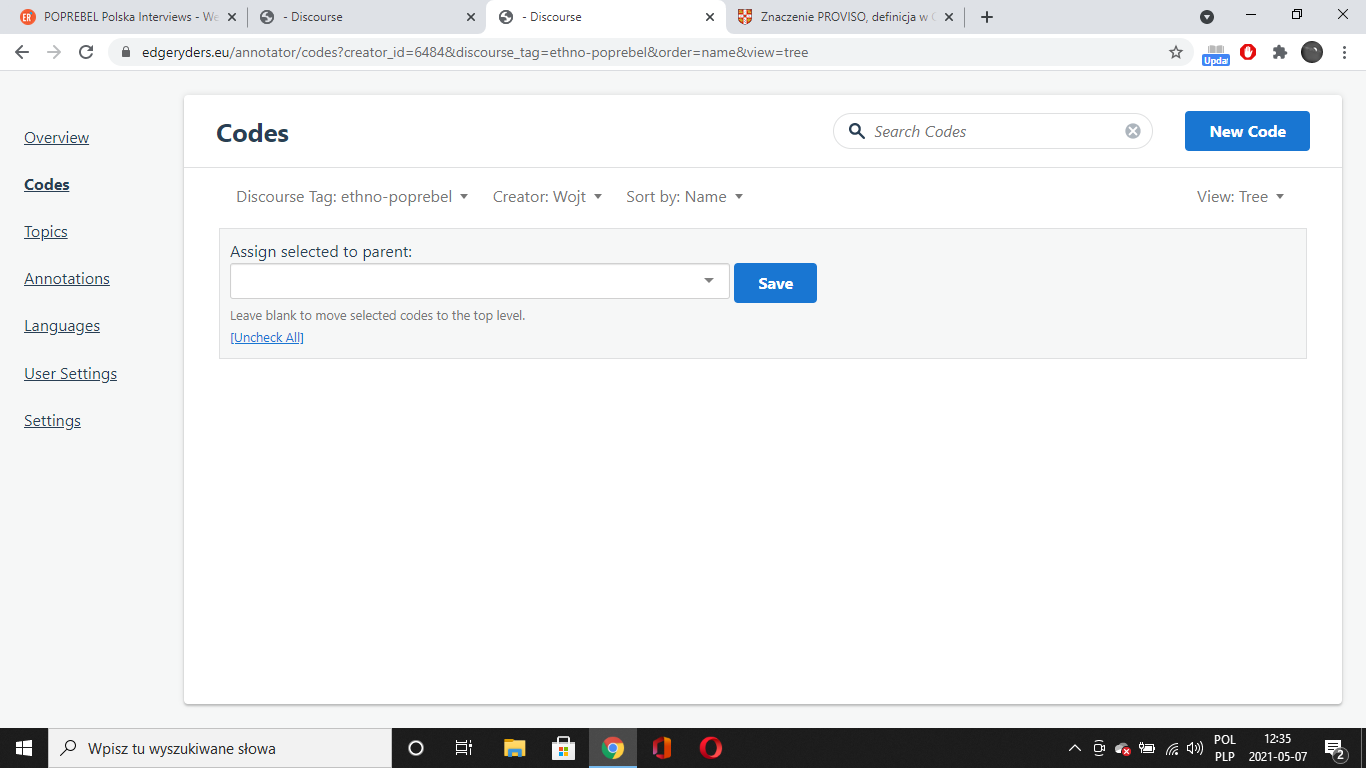
EDIT: You know how many of my codes appear under Any Discourse Tag? Seven. 7. Sieben. Sedm. Siedem kodów.
I distinctly remember creating more than 7…have the past several months been just some kind of a EU-funded figment of my imagination?
What do you think about putting the proposed category CHANGE under Z Social and Political Processes - Category?