This is a wiki. Additions to be made after each day.
Morning intro
Masters of Networks is a series of events organised by Edgeryders and according to @alberto, it is essentially about playing with data and networks. Participants get the time and space to do interdisciplinary work which everyone wants, but it is not easy to do. So Masters of Networks is open to researchers and enthusiasts, irrespective of their level of knowledge and the tools that they use in their analysis work.
Networks, for @melancon, elancon is about ’connecting dots’. People talk to each other. They are comprised of:
- People, or contributors
- What is being said, or content
- Nodes: a node is an attribution of meaning that has emerged from the qualitative coding and research done by ethnographers.
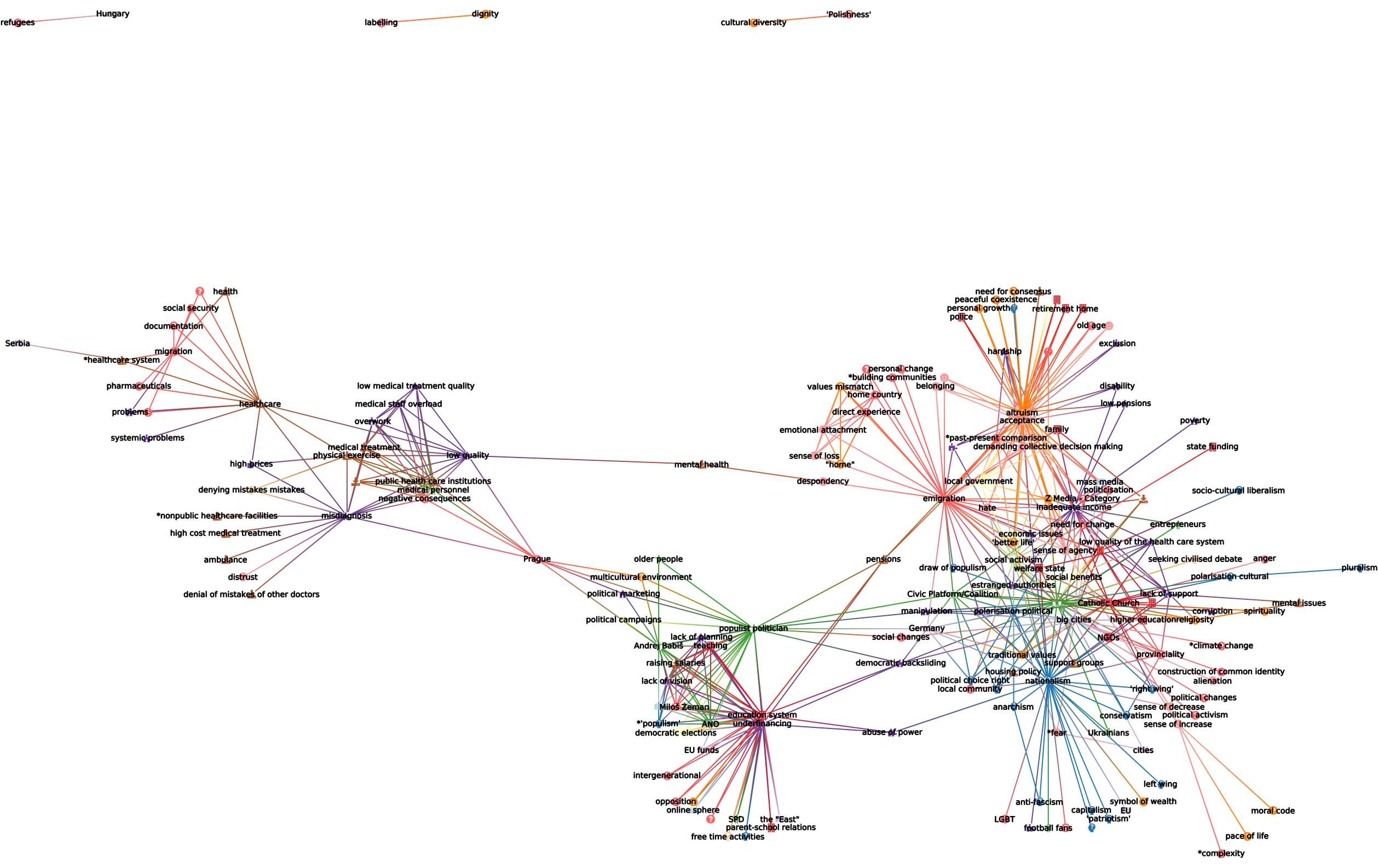
Day 1: POPREBEL Challenge
We are a roomful of (digital) anthropologists and data model experts: @Djan, @Maniamana, @jitka.kralova, @amelia, @Jirka_Kocian, @SZdenek, and respectively @bpinaud and @Hugi.

Above: the POPREBEL community; green = Serbia; blue = Poland; red = Czechia
How do we use SSNA to interact with different kinds of network visualisations?
How can we visualise the data usefully?
Ideas the team had for explorations:
-
What populist themes are shared or unique to each country? How useful can visualisations be to compare the data across countries? Visualisation is a communication means - if you have the question, visualisations help you to answer it. Sometimes a visualisation can show researchers who have coded separate data that they have the same themes coming up.
-
Discourse analysis and patterns - drawing from digital spaces. Djan is looking at Telegram chat events - i.e. when a conspiracy theorist (Atila Hildmann) posted a lot of messages and in the analysis you can see what are the patterns of that discursive model of conspiracy myths.
-
Can we visualise different code categories? Grouping codes into particular categories like ‘emotion codes’ versus ‘people codes’? It means we would designate codes based on particular categories (Amelia). Also: we have a lot of codes not right away connected to populism, emotional or ideological elements. If we can see how they connect to other topics more close to populism that would be interesting (Zdenek).
-
In a timeline: can we see what are the new POPREBEL topics that emerged in the last months? (Jitka)
-
What other possibilities exist to enhance the overview? Could we render code categories, node interrelations, colors per country in different ways? (Jirka)
What the team converged on:
We started from the Babel visualization model demonstrated by @Hugi. Different codes categories could be visualised in the graph: codes for Characters were highlighted and could be visualized alongside codes related to the story plots (Babel is a fiction writing project). For POPREBEL, this would translate into:
Given that for example the Catholic Church appears in different countries, then Institutions could become a distinct category, and all of the specific institutions would then be lifted from the graph through different coloring.
Similarly, we could color code Emotions and the subsequent emotions codes to understand how they relate to each other and other categories. Example:

All the top level categories that Amelia and Jan are working on:
-
Values and Beliefs
-
Ideologies
-
Emotions
-
Institutions
-
Actions and Activities
-
People and Identities
-
Movements and Events
-
Places
-
Problems
-
Social and Political Processes
-
Resource Needs
-
COVID-19 (can be changed/distributed)
Djan: one thing i noticed is a multilayered understanding of “Freedom”. Freedom to do something despite lockdown measures vs Freedom from being harmed from those deciding to ignore lockdown measures. How are these laden concepts dealt with visually?
Amelia: this is a code review question, it’s not really about dealing with those visually as much as it is making sure the codes are good/specific enough to capture the concept
Day 2:
Morning explorations with Amelia, Dzenek, Jiri, Noemi:
- When we group codes into categories like Problems, could they support and illustrate key insights about the research? For example what Jan calls the ‘cardboard state’? For example, looking at ‘corruption’ as a problem and seeing what codes it co-occurs with, in other categories, would be very interesting!
- Which codes are not being included in the categories ? Where should they belong? This is the case for ‘voting’ → which could now belong to something like ‘Political processes’.
- The timestamp is interesting before it allows to distinguish the ethnographers’ analysis, how it evolved, and also to distinguish between the different datasets!
- Jirka has been working with Tulip in another study of 80 000 interviews on anti-semitism (?), with semi-automated coding. We’d like to plan an introduction presentation of the methodology they used!
Day 3
Afternoon presentations: see the results in the comments below!
The timeframe is important for POPREBEL - we want to see the difference between pure conversational data and newer methods and datasets that 4 country ethnographers, who came in in early 2021, have adopted.
The chronological dimension is linked to the date of posting, not code appearance.
Noemi: do we need to compare the different datasets? According to Amelia: not so important, but what you can see is how certain codes over time become connected a lot with a whole new set of codes, which shed light on very important connections.
Somewhat more technical documentation for these days can be accessed here: