Here is the group. The question is now how we structure the process of using it for research purposes. We could:
- tweak the APIs so that @Amelia is served its content as coding material, using OpenEthnographer. This would automatically trigger harvesting of the coded content into GraphRyder (do you confirm, @Jason_Vallet ?) Very easy. Disadvantage: there is no automatic way to extricate this coded material from other coded material, it all goes into the same SSN.
- deploy some other method that would lead us to having not just one, but more SSN (on more than one instance of GraphRyder).
We will have the same problem with the group collaborating on OpenVillage. The main choice here is how separate we want the data from “collaboration in action” case studies like Open Insulin to be from the main data corpus.
Thoughts, @melancon | @Federico_Monaco | @Amelia | @Noemi ?
1 Like
bimodal hypothesis
Hi there,
my two pennies:
is there a way to develop it in a bimodal way? with data:
a) present research: harvested by OpenEthnographer;
b) new methods to be deployed: but at the same time keep it some place else independent and useful to deploy some more methods…what about dealing with it as open source software, so that every contribution can be represented and weighted according to product version (open Insulin 1.0, 2.0, etc…)?
Is it possible to keep tracking of the data just of the OpenInsulin by a tool meant for online open production? Otherwise i’m afraid it is needed tagging by hand of the events about it…
That would make possibile -if i have understood right- to solve the problems and have new options, for instance to work with conceptual models of predictivity and exploration.
…
I’m sorry, @Federico_Monaco , I don’t understand. 
Re:
I try in a simpler way:
would it be feasible to have on one hand the usual processing of data from tags and on a other side to analyse only the Openinsulin dataset as if it were, for instance, the process of a open source software? I follow the hypothesis of collective intelligence searching for possible material output of it.
Model vs. coding
I think I get it a bit now. Coding is coding. With OpenEthnographer you can highlight a snippet of text, then assign a code to it. That’s it. You can do this with some kind of model in your head. For example, with open source software development in mind as a template for understanding the process you are looking at. But this has no bearing on the software. It will still be coding: highlight, then assign a code.
So, we have three choices:
- We don't care to perform any coding in the Open Insulin group, or
- We code the Open Insulin group, but we do not want those coded data to be part of the main study.
- We code the Open Insulin group, and we do want those coded data to be part of the main study.
1 Like
How about usign a specific group ID for each?
I think this one is more in @Matthias’ area of expertise, so he should correct me if I am wrong.
Right now, all Opencare discussions belong to group 5954. If different group IDs are used in the threads on OpenInsulin and OpenVillage, we become able to distinguish the posts. We then only have to create different views to fetch this content exclusively if need be. Or if we want to add these discussions to Opencare, we only have to adapt our current OC views to include those groups in the data to export.
Mentions
Small bug in mentions, not annyoing enough to fix: it only works if there is a space at the end of the username. So, this does not work: @Matthias. This neither: @Matthias! But this does: @Matthias . Matt, can you read the commen above this?
One piece of content, multiple groups
The idea to differentiate by group ID seems good to me. With one addition: you can assign content to multiple groups. So if you assign OpenInsulin content always to both its own and the main OpenCare group, it would automatically be included into the main research, while also allowing separate analysis in just the OpenInsulin group with other Views and tools.
The multi-group assignment mechanism has some limitations / bugs in Drupal, but these do not concern queries created via Views (as far as I remember). Only when using tokens, and / or URL based tests, one is limited to testing the membership of content in its main group (which means, in the first one assigned to it in the form field).
(And yes @Alberto , there are still some ways for @ mentions to not work. Needs some tricky JavaScript debugging at some point of time  We already have a heavily modified version of the Drupal @ mentions module, plus our own auto-suggest module, and at some point I decided that it’s enough of that for the moment … I have not forgotten about it though.)
We already have a heavily modified version of the Drupal @ mentions module, plus our own auto-suggest module, and at some point I decided that it’s enough of that for the moment … I have not forgotten about it though.)
1 Like
Done!
So, here is what happened.
- I changed the Views feeding our APIs to include two new groups: OpenInsulin and OpenVillage Coordination.
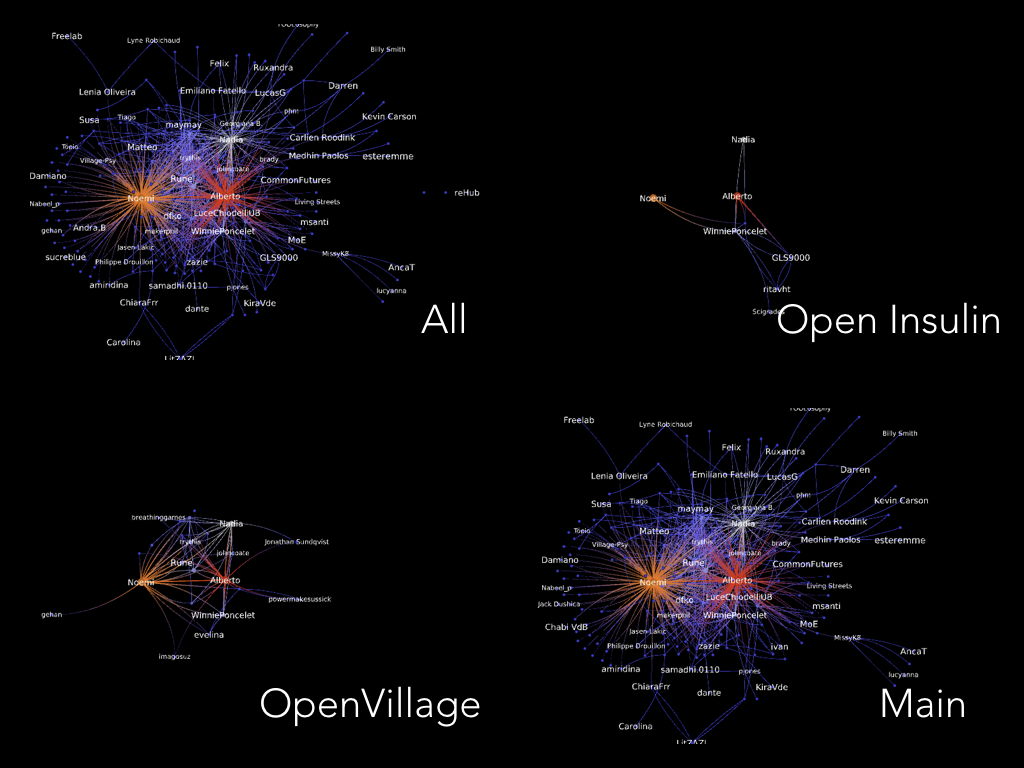
- API calls already return the group ID. Group IDs are as follows: 5964 for Op3ncare Community, 6917 for OpenVillage Coordination, 7766 for Open Insulin. If we are to build a separate "layer" of the network for this second phase of the project, it can be done by keeping track of what groups posts and comments were posted in in the GraphRyder code. I did a quick test with my social network visualization Tulip code: turns out that different people are active/central in different conversations (pic below).
- Numbers have gone up (important for @Amelia , in charge of the ethno coding). At the time of writing, we are looking at 239 unique informants (formerly 230); 420 posts (formerly 370); and 1987 comments (formerly 1778). We are now quite close to 500K words.