You can also sort on the fly by user and post date.
@Noemi this might appeal to you and @johncoate too. Drupal keeps track of who has seen what, so the number of new comments will always refer to each one of us (as long as we keep logging in with the same identity).
It would be great to also be able to filter by uncoded posts (so, show any post that has no coding at all). As more and more posts get coded, clicking through to find ones I haven’t done gets more time-consuming (since each page takes time to load). Thank you!
Also, I mentioned this at the beginning of our conversation re:Open Ethnographer, but it really would be so helpful to isolate my codes from Inga’s / what came before. It makes for a lot of noise when I am trying to find the right codes while coding. Thanks!
If we can’t isolate completely, a colour coded system or any way of visually identifying the difference would be great.
For example-- I keep accidentally selecting misspelled versions of the code I want because they are visually similar, and I don’t feel comfortable deleting the misspelled one because it does not belong to me/I don’t want to get rid of the data associated with it in case it is needed.
Sorry, @Amelia , nothing I can do. Here’s a quick assessment. Calling on @Matthias for his opinion, too.
Only uncoded content
The database has all the information you want, but I cannot get it out via Views. We need a MySQL query like: “give me all the nodes as already filtered in opencare explorer, for which there exists at least one annotation where the field entity_id is equal to the node ID”.
I think this might be solvable by adding a new relationship type. I am trying to do so here, but not sure how to “finish” it.
Only my tags or color-coding
Taxonomy terms do not appear to have an “author” field – or at least not one that I can access through Views, though I remember Matthias saying that actually taxonomy terms do have an author ID somewhere.
There may be a way to list only uncoded content in a view by using Alberto’s relation type and row aggregation (similar case). However that is quite some complexity for the views system to handle. A more elegant way would be to extens Open Ethnographer to add a “Content: Annotation count” pseudo-field that can be selected in views. Similar to how “Content: Comments count” is available for comments. Then you can filter the view to show only rows with “Content: Annotation count == 0”, means, only uncoded content.
Of course the question is who’s gonna implement this (0.5 - 5 hours … no better idea about the effort yet). Did Dan accept the OpenEthnographer extension job?
“Only my tags” or color coding
As Alberto said, terms (=codes) do not store this information yet. There is a module that provides it, but it has a messy implementation (own database term_author table rather than using the Drupal Field API). So I think the best way to add this an entity reference field to taxonomy terms, like this:
field name: field_term_author (or similar)
target type: user
widget type: select list
token for default value: [site:current-user:uid]
This field will then also be available in views ( @Alberto , do you want to try to add it to OpenCare Explorer?). Restricting the list of terms provided by OpenEthnographer will need some coding though. Let me know if that is needed, and (hopefully) if it can wait to be included as part of the OpenEthnographer expansion project.
I’m wondering what happens when posts get updated---- I am getting some deja vu when coding ‘new’ posts, and am slightly worried that a user updating a post might cause some annotations to go away. On a related note, I’m getting posts popping up in the OC explorer that are marked as “new” when they are already coded----any idea why? Different from the “x new comment” posts, they are marked as though they are entirely new, but they are all coded.
Also, I know we are strapped for resources in this area, but now that I’m heading into a second pass, I could really use a way of visualizing all of my codes (VERY ideally without Inga’s) so it is straightforward to move them into hierarchies and merge/fork/delete/rename them. Think of the priority at this stage as a categorization and editing of existing codes rather than doing new coding, and then we can imagine ways of making that more straightforward. I’ve just sent a WP to @Alberto which details the process— I think even though new stories are being generated (that I am still coding) it makes sense to put energy into refining and categorizing (so stages 2 and 3 of the ethnographic coding process).
An interface to drag, drop, and rename (like @melancon suggested very early on in this process) would be ideal. I know that it is technically possible to rename codes as it stands (and I’ve been doing it when a needed change is immediately obvious) but it is very difficult to visualize all the codes (or even multiple codes) at once to see what needs to be edited.
And as always, it would be extremely helpful to be able to only see uncoded posts in the oc explorer especially now that the majority are coded now.
“Updated” means “edited”. It is unusual for posts to be edited long after publishing; something that has happened is that some posts have been re-assigned from one group to another. In this case, they show up as “edited”, but the content is unchanged, and so are annotations and codes.
Posts showing up as “new” that are not new… I have no explanation for that. “New” is relative to the user, so it is totally normal that this happens if you log in from multiple users. But it should not happen from the same user.
Visualizing all your codes, without Inga’s, can be done by filtering by those tat have been last updated during the course of Opencare. I made a page here. But it works very poorly: all codes seem to have “0” as a parent ID. The legendary research question code does not appear, though it definitely features in OpenCare and does have a parent term. However, I created a test code nested under “abuse” and it appeared (now I deleted it). @Jason_Vallet can probably build you a list from the Neo4j database.
As for making a list of not-yet-coded material: Drupal is unwieldy, and making you a web page with that is beyond my abilities. Your man is @Jason_Vallet , and the right way to do it is to run a simple query to the Neo4j database supporting GraphRyder.
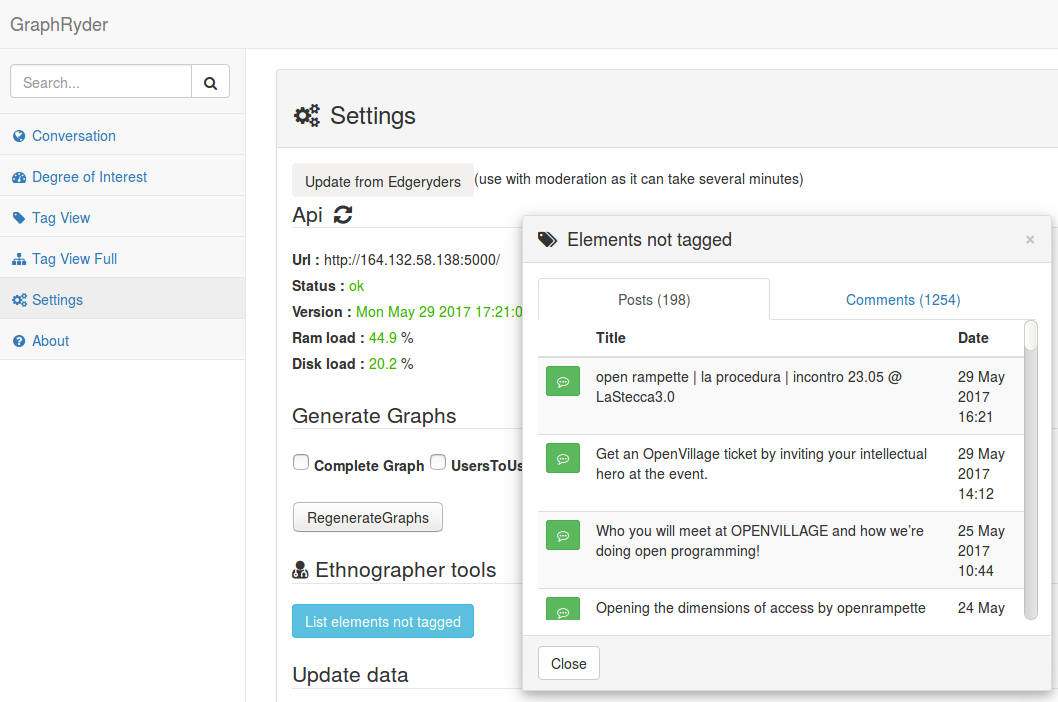
@Alberto@Amelia I have added two new buttons on the settings page to help you find out which content is not yet tagged. The first one, labelled “Update from Edgeryders” and allowing to force the update of the database, has been hidden for a long time to avoid problems which may arise with multiple update commands. This should be fixed now so the button is available until we set up an automatic update system to update the DB every day (something using CRON is in discussion).
The second one in light blue opens a list of all the posts and comments without annotation sorted from the most recent. You can explore each content as usual and get the link to the original page from ER. Once a content have been annotated, you can update the database to check that the elements are no longer shown in the lists (you will need to close the panel and open it again, the list does not refresh alone).
The database update may take some time (around 2 minutes usually) and is quite labour intensive for the server, effectively slowing all the other operations, so please try to avoid updating after each modification.
I can not really help with the whole management of tags as the modifications on our DB will not be sent to ER. However, I can provide a list of all the tags ordered according to your specifications if it can assist you for the task and help you track problematic tags. You can also use the “Degree of Interest” view with the “Neighbours” display and the search tool to find duplicates/spelling alternatives (e.g., accessibility, accesibility, accessibilty).