Hello @Jan, @Richard and all @poprebel -s, happy 2021!
We start the year with two small bits of good news:
First: our (partial, provisional) POPREBEL open dataset, published March 11 2020, has already totalled over 1,000 downloads. That’s really good going! There seems to be interest for ethnographic datasets out there (in fairness they are very rare).
And second: the POPREBEL corpus has meanwhile cleared the bar of the 2,000 posts. We are now at 2,142, authored by 316 participants. The corpus is overall 444K words (The Lord of the Rings: 455K). The interaction network has 794 unique direct interactions, and looks like this:
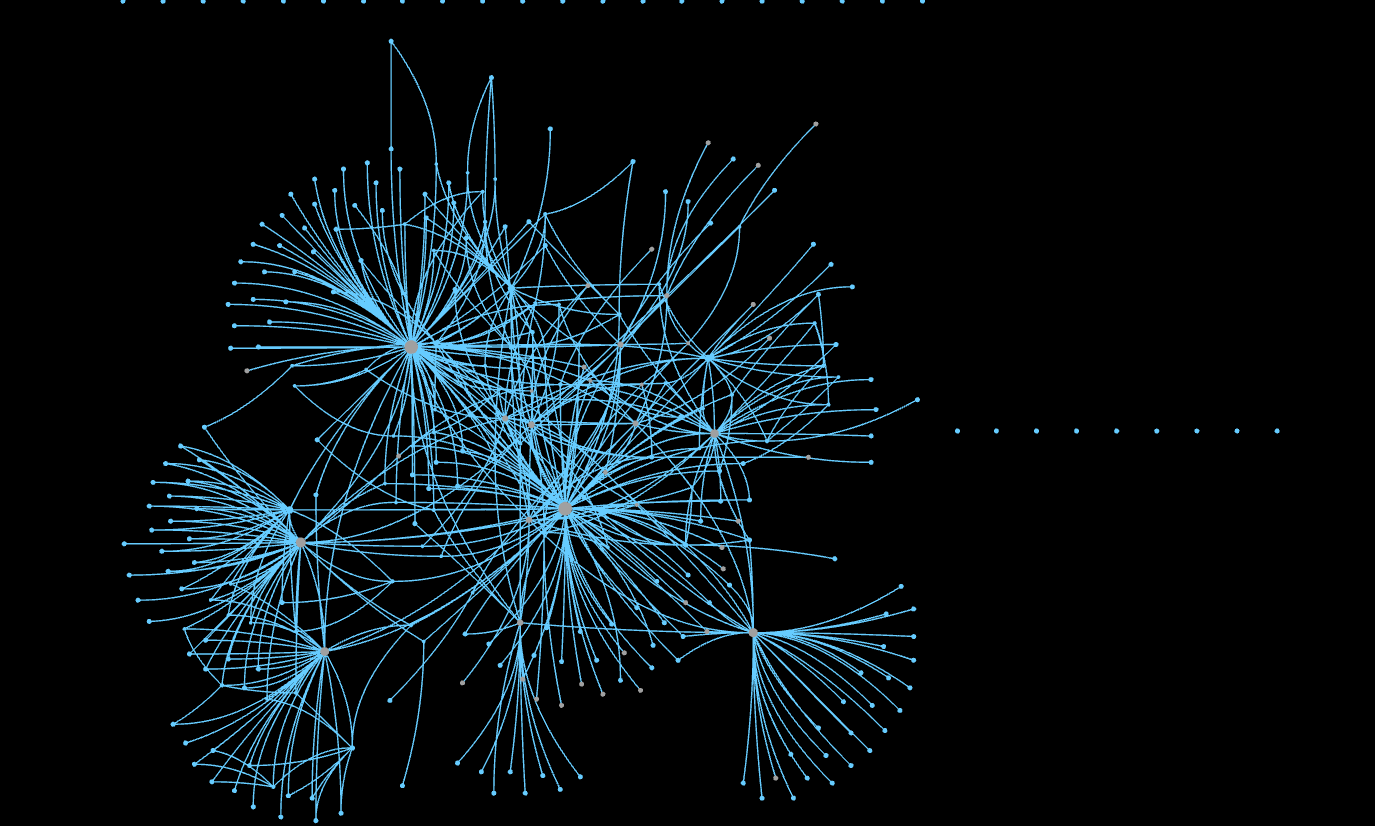
The corpus has 4,813 annotations, associating the content to 1,236 codes. The resulting semantic network is very dense, with over 50K co-occurrences, and 34K unique edges, even after stacking.
Good work, everyone!