Hello @rebelethno! I created a script that closed the nodes of a subgraph into a metanode. It then computes the properties of the metanode itself and of its incident edges based on the properties of the nodes that compose the metanode, and of their incident nodes.
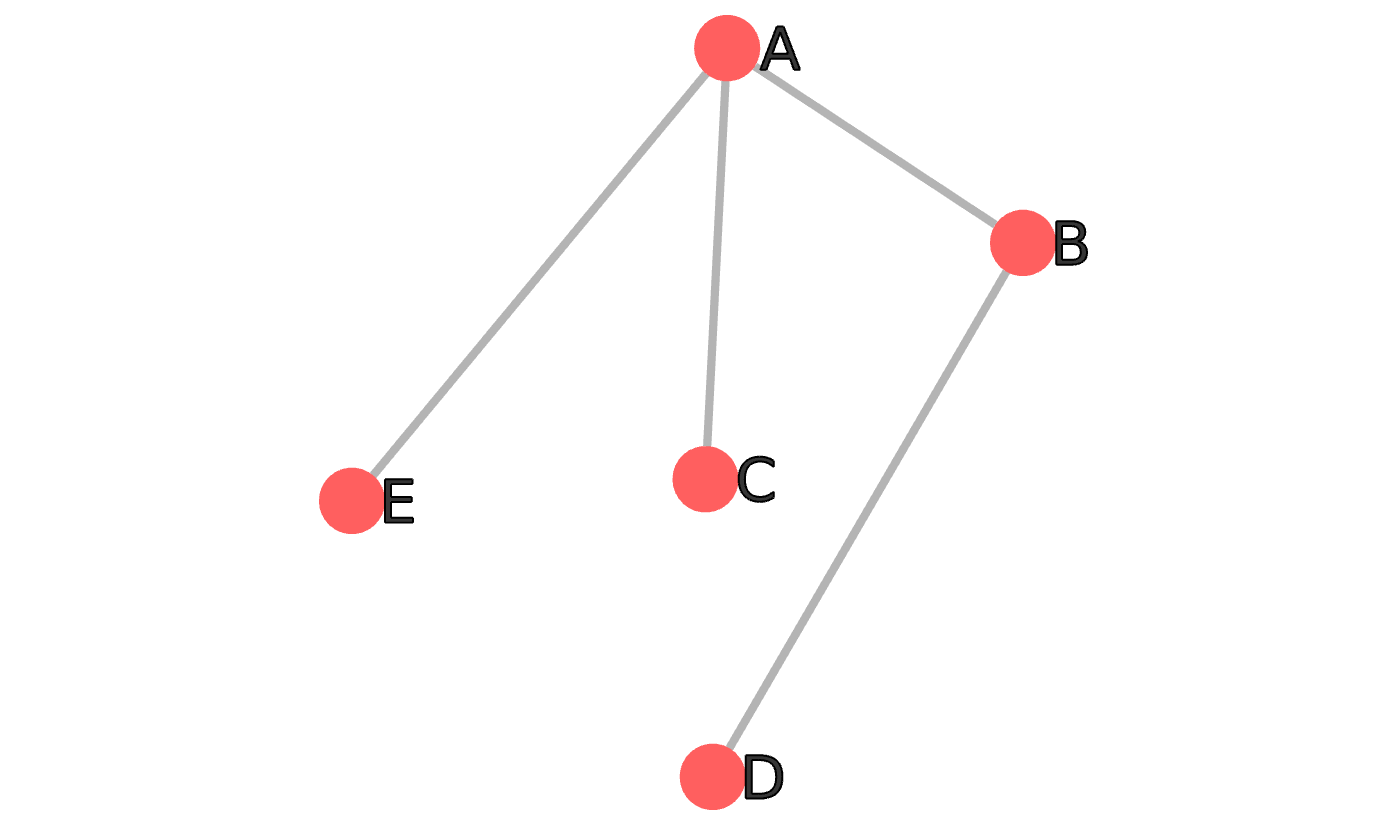
Recapping the main idea: suppose you have a graph with only five codes:
You decide that A and B are related, and you want to look at what the graph would look like if they were compacted into a unique node. You are looking for:
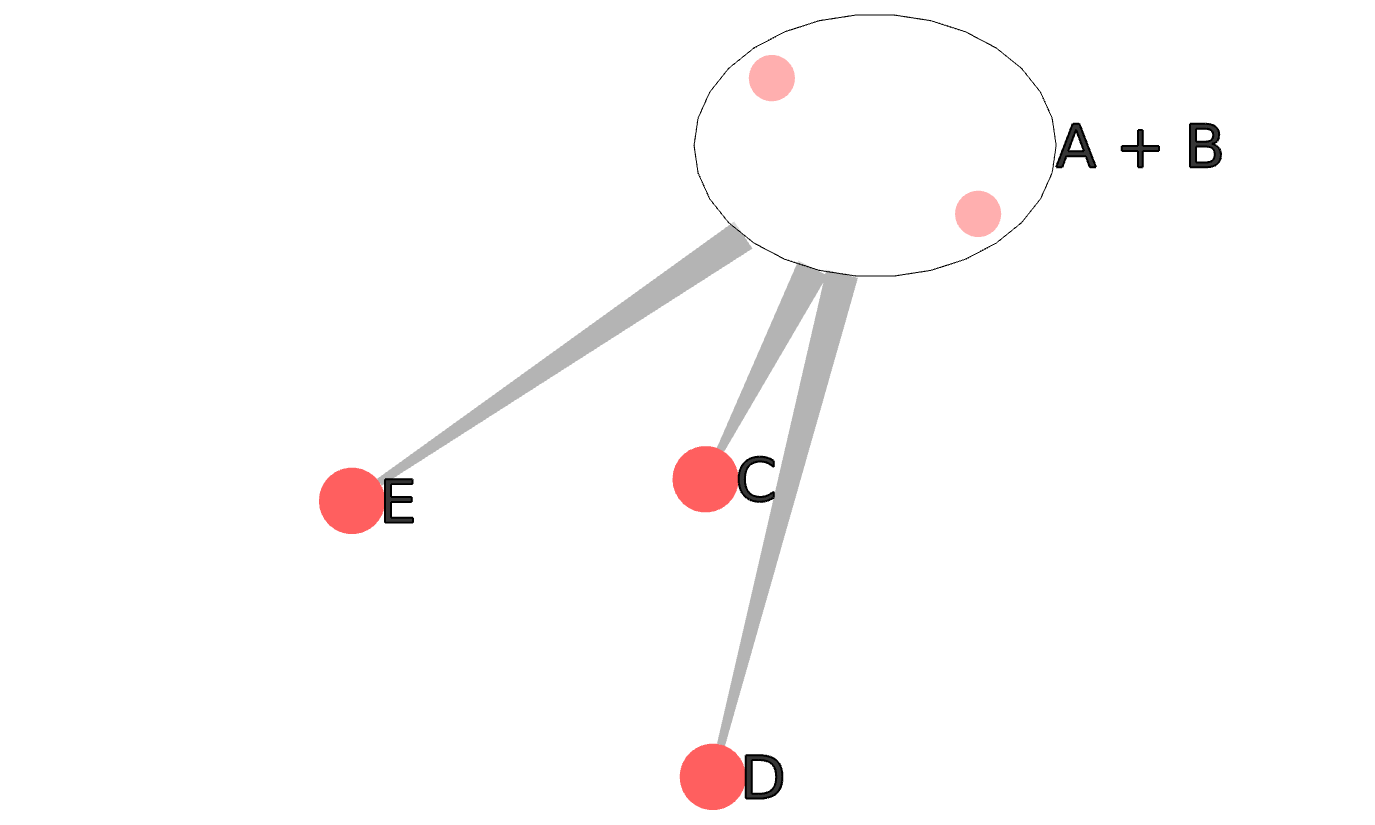
The new node A + B inherits the edges of all its component nodes. The edge connecting the two component nodes is gone, or rather entirely close into the metanode.
I made an experiment with the POPREBEL graph, k=006. I took 5 codes that speak of inequality somehow: inequality, big cities, (lack of) affordable housing, inadequate income and higher education. Here is the graph, where I selected them and all their incident edges (in orange):
Here is the same graph with one single metanode replacing the five nodes, also shown with its connecting edges:
@alberto WOW! I think it is exactly what we were looking for! Thank you. This way we can go back and forth between looking at and analyzing two “levels of aggregation” of information! And Alberto, so you know, I just extended our offer to a new Polish community “organizer” and ethnographer. We should be resuming activities soon.
My next step is to use the ancestry of codes to make the metanodes. But I worry that the levels of abstraction might be too different. Also, right now the hierarchy of codes in POPREBEL is 4 deep:
Ok, let’s use an example. If we fold all children codes into their respective parent codes, we end up with masculinity folding in its only child, toxic masculinity.
On the other hand, environmental problems has seven children: emissions, ecological activities, helping animals, human interventions (into the landscape), pollution, animal rights and climate change.
Of these, ecological activities has three children of its own: waste production reduction, reduce food waste and recycling.
Of these, reduce food waste has one child, foodsharing.
And of course, there are plenty of childless nodes. Let’s take one as an a example: free time.
So, how to reduce this graph? A formally clean solution is to do the following:
All nodes in tier 1 (those who have no parents) of the hierarchy are represented by a node of the same name in the reduced graph.
All tier-1 nodes that have children are represented by a metanode including themselves, their children, their children’s children and so on until there is progeny.
In our example, that leaves us with three nodes. One is simply free time, carrying over from the unreduced graph. The other two are actually metanodes: one called masculinity (folds in toxic masculinity), the other called environmental problems (folds in 7 children, 3 grandchildren and 1 grand-grandchild).
Would this work? It seems that folding toxic masculinity into masculinity is a smaller step than folding foodsharing into environmental problems, three levels up… but this is a call that only the coding team can make.
@alberto Many thanks. Very clear example. Beautifully exemplifies the problem that I now understand well, I think. Yes, we will discuss it at our next meeting. Perhaps it is not a problem, but it is worth our discussion. “Ontological density” (or something like that) is indeed different. And yes, I see that we need to go for further reductions. Ciao. J
This is absolutely great - it basically allows us to fully operationalize the visual environment as a code reviewing tool in a way, which is often causing brainfreeze when performed in a sheet or one dimensional linear code view:) The utility for the final analysis is without doubt.
@Jirka_Kocian, could you please explain? I know for you it’s just a waste of time (you understand it already), but the better I understand your way of thinking the more I can help.
BTW: this is a beautiful interdisciplinary exchange. Way to go, @rebelethno!
Oh no, explaining! As I see it - I originally generated around 50 codes in the healthcare that need reduction, where I see the this helps:
(I think we discussed limiting ourselves to three), our coding approach was taking it somehow from the middle and building the hierarchy both in an upward and downward direction (I generated the code medical personnel in the first-ever coded article, it immediately gained a child node medical career issues and a parent public healthcare system with the same article. That was great for representing a couple of related articles in the Czech forum, but might be too granular and disconnected from the other forums. In addition, I generated a healthcare quality node, within the same article, which was very closely related to the medical personnel but ontologically distinct. The simple solution was to create a parent node for both or making medical personnel child of healthcare quality to generate a “proximity relation” between them, but that exactly is what complicates the codebook. One should also take into account what is the purpose and avoid “coding for coding”, which I am guilty of sometimes:)
What we have been trying to do during the last months was to establish a common protocol for all the forums, carefully reviewing how we construct the code labels, nodes and parent-child relations. That was very prodcutive, however, in order to achieve so, we basically needed to learn to know the whole codebook around the whole POPREBEL “by heart” and have the code authors for consultation at hand. I think it was quite a challenging task since we did not have a tool for reviewing specific segments of the structure (codes/nodes + relations, but not necessarily having one node or forum segment as their center point) - and more importantly to easily compare these segments across the whole codebook. And sometimes, it just seems a bit difficult to get rid of codes in order to place them into a tighter hierarchy for the purpose of analysis.
In practice, now we can easily simultanesouly check how, for instance, the situation with medical personnel and healthcare quality (both up and down the node relations) looks in the Czech forum by creating a metanode, instead of taking the mental exercise of imagining it, or merging the codes and possibly losing ontologically valuable nodes and relations. Moreover, we can easily compare this with the analogical segments in the Polish codebook and easily consider re-labelling of some of the codes (merging) or changing the hierarchies without the necessity of scrolling through the linear list or finding them in a sheet.
@Wojt and I started working on the spreadsheet today in order to start addressing Alberto’s observation that we have now 4 levels (we suggest we should have no more than 3). If you go to the spreadsheet and tab “Corporations” you have “Alexa” as the 4th level. If this was not problematic enough, NONE of the seven annotations related to code “Alexa” is from POPREBEL! God knows how many other codes we have created or used that have NOTHING to do with our project. I know we have discussed it mant times before. Is there a solution? We are wasting a lot of time coding irrelevant stuff! Let’s talk about it soon. Have a great weekend. And now back to Man U vs Arsenal (so far 0:0).
@Jan and @Wojt, this does not have to be a problem, because in all graphs we are looking at, both in Graphryder and in my Tulip ad hoc visualization, you only see codes that are used in POPREBEL.
Load all the annotation related to those topics and posts.
Load all the codes used in those annotations.
With these, and these only, build the graphs.
So, some codes might exist both in POPREBEL and other projects; others might have children that are not used in POPREBEL at all. But that is irrelevant, because we only analyze annotations made on POPREBEL posts. Those codes that are never used in POPREBEL never appear in the graphs at all. I checked, and alexa is indeed not there.
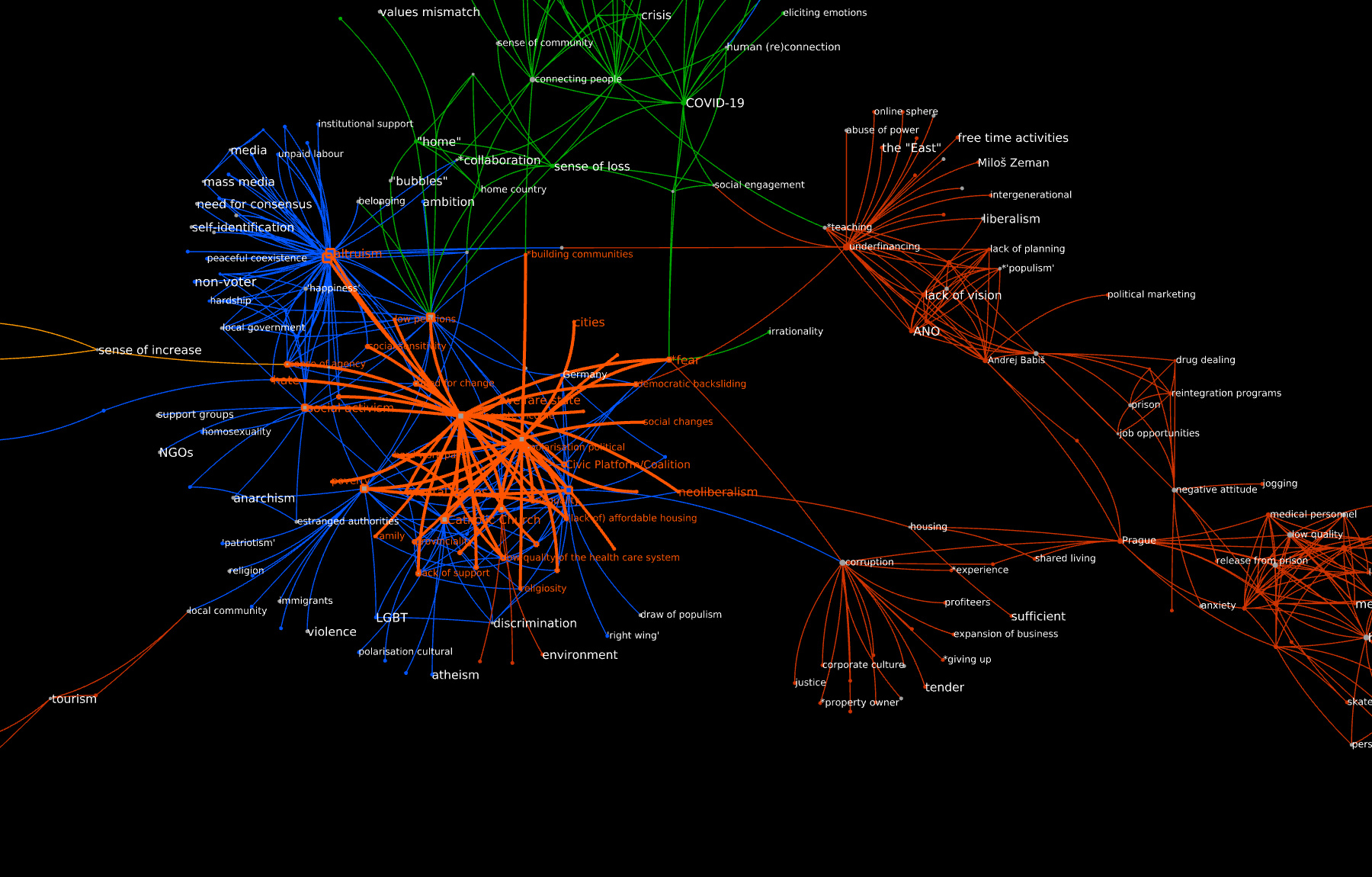
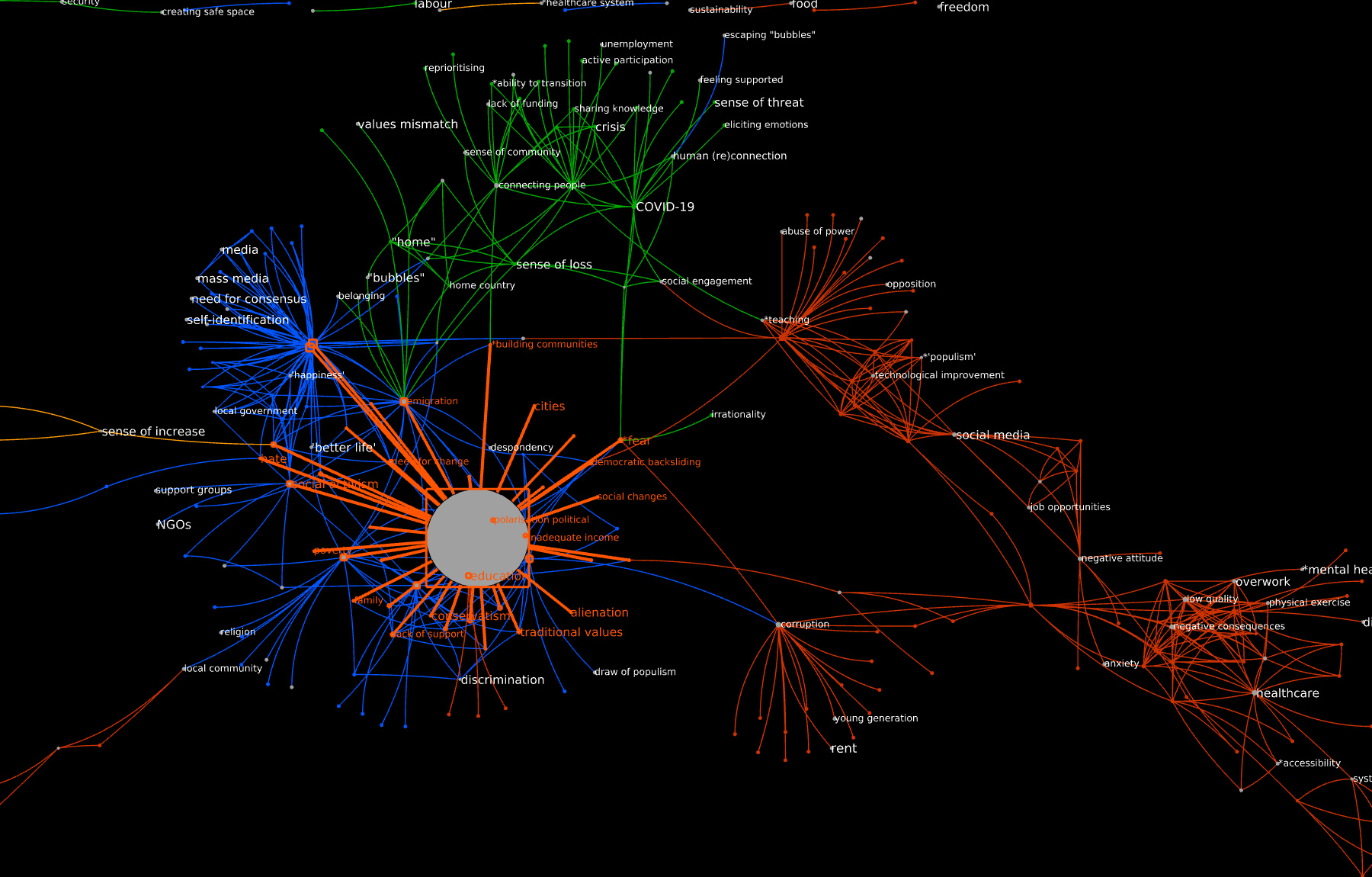

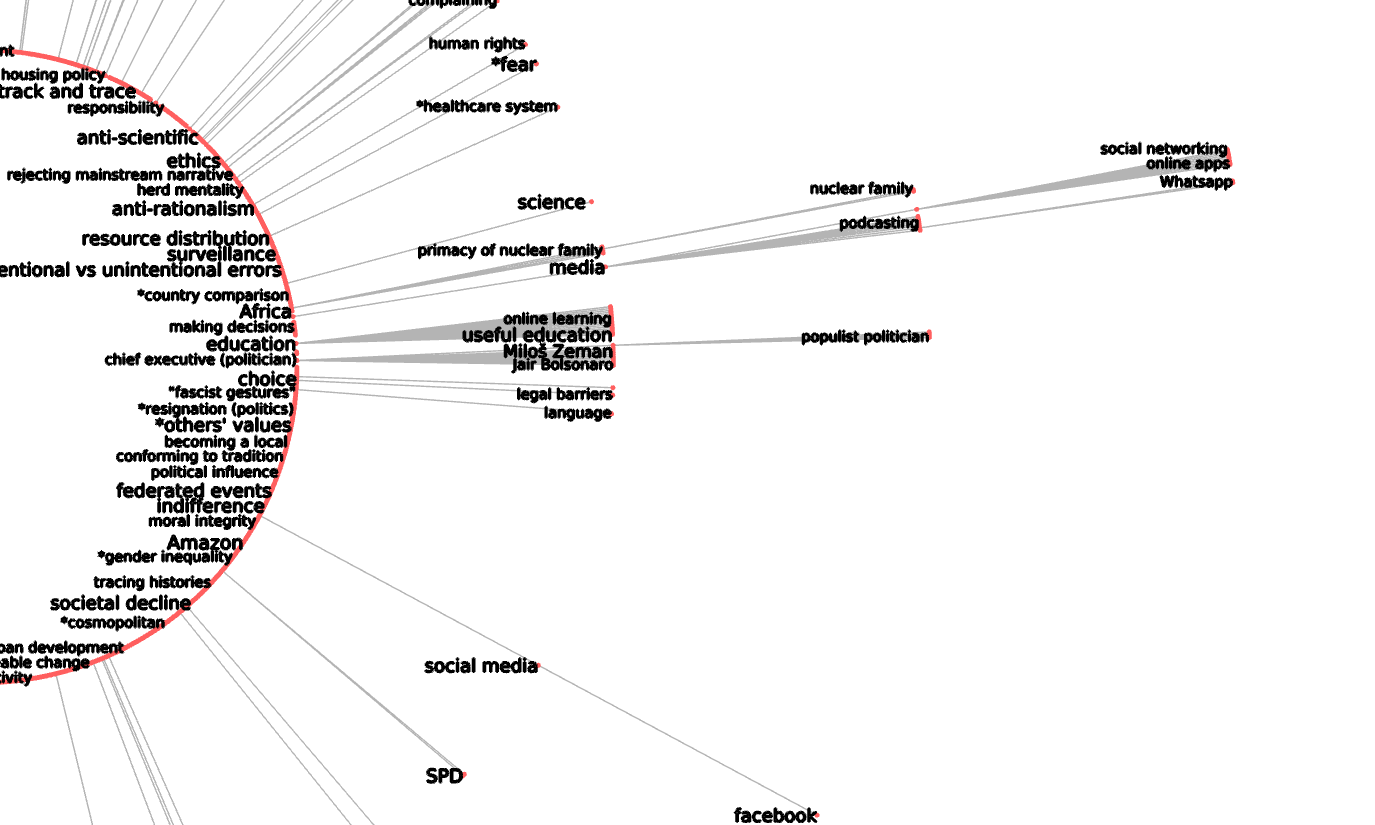
 As I see it - I originally generated around 50 codes in the healthcare that need reduction, where I see the this helps:
As I see it - I originally generated around 50 codes in the healthcare that need reduction, where I see the this helps: