Why not stick it into Wellbeing as a subcategory? This is easy to set up. If you want it can be done in 5.
1 Like
If it won’t create confusion, why not! It fits well theoretically, we can move it if we think it doesn’t work.
yep.
So go ahead and fill out the text for the “about” topic in there.
I just think it’s a real shame sinking resources into two separate implementations of essentially the same thing. I could project manage further development of a Vue and Node implementation. However, my time is short until August so it depends on the urgency.
I don’t agree that Vue is complicated though. It follows the same paradigm of most current web development. That it’s relatively simple is exactly why Owen could build the IoH site very quickly, with quite a lot of bells and whistles. I’m just worried that an implementation on a less modern stack won’t feel as modern and snappy as it should for this use case.
1 Like
Hmmm, then it’s not a match unfortunately ![]() According to @natalia_skoczylas the site will have to be ready by 2019-08-15 and would then go into two weeks of test operation and live on 2019-09-01.
According to @natalia_skoczylas the site will have to be ready by 2019-08-15 and would then go into two weeks of test operation and live on 2019-09-01.
Yes I know, and I agree. At the same time I’m scared of using the wrong tool for a job (… been there, done that … the Drupal based site was a disaster from 2012 to 2017).
Now I’m not going to tell people what technology to choose for their Edgeryders software projects. There would be some efficiencies to gain, but I’m too anarchist to accept people doing that to me, so I won’t do it either. The principle is instead that everyone who chooses a technology makes a best judgment after looking at both the problem and our existing software landscape, then choosing something that fits in best.
So when I did that when tasked with the NGI platform / façade website, my considerations were as follows:
-
Open source. That’s obvious. For the NGI platform, this was even in the grant agreement. It also affected the choice of template in the end (plain vanilla Bootstrap), eliminating commercial templates based on Bootstrap but under proprietary licences.
-
Hostable on the Edgeryders server. We have a “one server for everything” approach and all software used for Edgeryders projects should be on that server. Except software we use as SaaS of course.
Software that is distributed as Docker images etc. is not an immediate fit. (Discourse itself also comes as a Docker image in the most usual form, but we figured out how to install it on an existing Linux server.)
-
Language choice. Our software landscape is mainly Ruby (because Discourse) and Python (Graphryder, Alberto’s scripts, Dynalist Companion etc.). Reasonable exceptions are ok, as long as the language is common and / or simple enough to allow DIY maintenance of the software.
Another aspect of language choice is if it fits into the targeted open source software ecosystem. Because it’s a waste of resources to develop a good open source software that is then used only inside the organization because it somehow does not fit for the audience. So for a software that interacts with Discourse, Ruby would be an obvious choice, as it makes it easy to work with for people who know their way around developing with Discourse already.
-
Tool for the job. The job is to serve a relatively simple website without end user features to enter data / create content. The website should be updated frequently though, with new data from Discourse.
-
Keeping it simple. The right tool for a job is typically the simplest one that is intended for such a job, while being extendable enough for expectable future jobs of a different kind. But software that tries to be so extendable that it is “ready to do everything” is often not a good tool for any job. That was the mistake we made by choosing Drupal: wanting a system that can be extended by power users without programming lead to choosing a hyper-complex software that came apart at its seams, with thousands of unfixed bugs that are never fixed because people are just overwhelmed by them. And because it tried to be everything at the same time, it made even the simplest tasks like templating complicated.
I’m not against a software “because it’s complicated”, but when it is “too complex for the job at hand”. Discourse itself uses React internally, quite similar in architecture to what Vue.js does. We’re happy with it there, because (1) it’s useful there, and (2) it is used to its full potential inside Discourse. It comes with its challenges (like the shadow DOM when debugging), but these we accept as it plays out all of its advantages as well.
Now for the case of Vue.js: I had to install two different package managers, then it installed 600+ packages, then it compiled 300+ things, then it started a server process. We need a static website, without interdependent UI elements / widgets. There does not have to be a server process. There do not have to be 600+ packages of anything. For this type and size of problem, Vue.js is overkill by about one order of magnitude.
-
Maintainability. Ease of maintenance by others in the organization is another concern. As in, “do not create software that depends on yourself”. We have fared well so far with a strong DIY approach, which means: we need to be able to maintain our own tech infrastructure based on documentation and in-house skills.
-
Security considerations. For practical reasons and because we don’t handle sensitive data, this is not that much of a concern. But it’s good to stay away from things like: WordPress and a lot of plugins, many of them no longer maintained. And if there is a choice, static websites are great from this perspective due to the minimal attack surface.
-
I don’t care about trends. I do something when I understand its benefits for the situation at hand, not because everyone else does it. Worked well so far, so I apply it to software as well.
So that’s how I decided back then, and thinking about it again, I stand by that. Again, this is not to tell others what tech to choose when. As always it’s “Use your best judgment, and I’ll trust that you do.” But I think it’s still useful to have an exchange about these matters, as we could happen to learn from each other how to decide these things.
I think we should approach this dual implementation as an experiment: just as in the many redundant open source projects, it will only emerge over time which was the right decision. It may even happen that each system finds a different niche and they keep coexisting. We’ll see.
5 Likes
Regarding the timeline, we can move it two weeks - if testing starts on the 1st or even 7th of September, it will be enough time.
Coming back to you soon with the flow.
1 Like
Could this be a manual?
Actually, yes. We’ll have to keep it more open than a normal manual so that others can document different approaches as well – because this is a fuzzy topic. But for a start this would do, yes.
OK, “principles for developing Edgeryders software projects then”. There is a fundamental tradeoff between “quick and cheap, but duct-taped” and “deeply integrated but difficult”. Where you go depends on what you are building: for a top-of-stack, non-mature product like Graphryder it is not so bad if it’s brittle, because even its concept has a limited shelf life.
I would want to have a say on iterating this before it becomes a manual. There are quite a lot of areas in which @matthias and I operate under different paradigms.
This will become a bit lengthy, and also runs the risk of hijacking this thread from its original purpose. Perhaps we should fork it? I will split this post into two – one addressing the more general points on how we do things and the other on the subject of microsites with Discourse as their CMS in particular.
On this point, we agree completely.
Currently, the following Edgeryders software and sites are hosted outside of that server:
- Graphryder OpenCare API Database (run by Bordeaux guys)
- Graphryder MENA API, database & dashboard (hosted on same Digital Ocean droplet)
- Participio API serving Culture Squad and Internet of Humans minisites (hosted on other Digital Ocean droplet)
- Realities (an Edgeryders project through Participio)
And more will come. Unless we mature Graphryder to handle multiple datasets on the same database, we need a separate server for each instance, since Neo4j Community edition can only run one database at a time. This means one server for POPREBEL Graphryder and another for NGI Graphryder.
Furthermore, if we ever start selling Graphryder, we will want to streamline its deployment with something like a docker image. Same goes for Realities, which I would also like to develop further. And I have another 20k in the Participio budget earmarked for some new experimental software for participatory culture, yet to be determined.
We don’t want to bloat the mission-critical server we use for Discourse with all kinds of environments, databases, and packages. But we also don’t want to let one set of technology dictate what other technology can be deployed in Edgeryders.
Deploying small virtual servers on-demand makes a lot of sense and a lot of freedom. Indeed, we’ve never had to even disagree about this since I’ve just gone ahead and done it without having to ask permission. That’s much more in the spirit of Edgeryders, a lot more than “one server for all Edgeryders projects” in my opinion.
What we should have though is documentation of where our software is deployed, who has root access to a given server or VPS, and who has been given limited SSH access.
This is true for backend, but not really front end. Our front end (Discourse client, GraphRyder dashboard, Culture Squad minisite, Owens minisites) are mainly JavaScript.
This is only true for back-end. And I would not at all be opposed to replacing the very minimal JavaScript API that powers the Culture Squad and Internet of Humans minisites with something built in Ruby or Python. But for the front end, it would be more consistent with Discourse to use JavaScript.
Welcome to front-end javascript world ![]() . However, you don’t need to run a server process to serve a Vue.js website. It can be completely pre-built. For example, both the Culture Squad and Internet of Humans sites are pre-built single-site web apps that don’t need any server process apart from a normal web server. You don’t even have to compile them on the server. You can simply build locally and push the dist folder. Or you can make your life easy and use something like surge.sh or netlify.com and have your site magically deploy a build every time you push changes to git.
. However, you don’t need to run a server process to serve a Vue.js website. It can be completely pre-built. For example, both the Culture Squad and Internet of Humans sites are pre-built single-site web apps that don’t need any server process apart from a normal web server. You don’t even have to compile them on the server. You can simply build locally and push the dist folder. Or you can make your life easy and use something like surge.sh or netlify.com and have your site magically deploy a build every time you push changes to git.
This is true. But having one paradigm to rule them all does not make this easier. For example, I would argue that when it comes to web development, our network of Node JavaScript developers is pretty strong (@luca_mearelli, @erikfrisk, @gustavlrsn, @owen and to some extent myself though I’m more of an API and database guy).
Yes, I agree. But you can still create content from a static website as long as that website has an API to talk to. And with modern JavaScript, a single-site static website can feel like it’s not static at all.
Since the content is loaded directly from discourse to the browser client of the minisite user or from a lightweight cache of the content on Discourse, you don’t need to keep rebuilding the site with cron to get new content.
Ok, so now onto the specific implementation details of what @natalia_skoczylas is asking for.
Based on my interpretation of the scope, I’m not sure that this is the full scope. This is what I gather from the thread:
From what I gather, this is the scope:
- Give people a fast way to engage directly with a particular open question through posting content on a minisite without having to go to Discourse and register an account.
- They go through a consent funnel on the minisite and their post ends up on the platform.
- Make it easy for people to register on the platform after they have posted on the minisite, by sending them an email with instructions.
- If they register, they claim the content they provided through the minisite as their own.
- Preferably the possibility to display and explore content from the platform in new ways, like by implementing a graph representation of the conversation.
- A priority is that the site should be more visually appealing and “sexy” than Discourse.
Based on how I understand the scope I think it would be important that the front end site can:
- Post content to Discourse through interfacing with a custom API.
- Be able to interactively filter through and read posts from Discourse.
- Show interactive graphical representations of content, for example like the tag exploration graph on the IoH site.
And the custom API and backend, as I understand it, should:
- Post content written on the minisite to Discourse, probably to as a bot account to a new thread in a hidden workspace.
- Send an email to the person who posted from the minisite, guiding them to register an account
- If an account is created, change ownership of the post made through the minisite to belong to the new account and move it to the main conversation.
Since all of these actions are possible from the front ent client, which is just calling he Discourse API, it should be equally possible to do by our custom API that is called by the minisite.
My five cents is that a modern JavaScript framework like Vue.js fits hand in glove to do the front end and that a Ruby or Python server would be well suited for the back end.
If we were to write a backend API, we could also have it do caching of JSON responses from Discourse and thus replace the current Participio.api that is serving Culture Squad and Internet of Humans, we would have a pretty powerful beginning on our own Edgeryders API to extend Discourse to other front end applications.
Maybe at this point would be good to have wireframes and visualisatation from @natalia_skoczylas so we are sure everyone is on the same page @matthias @hugi
3 Likes
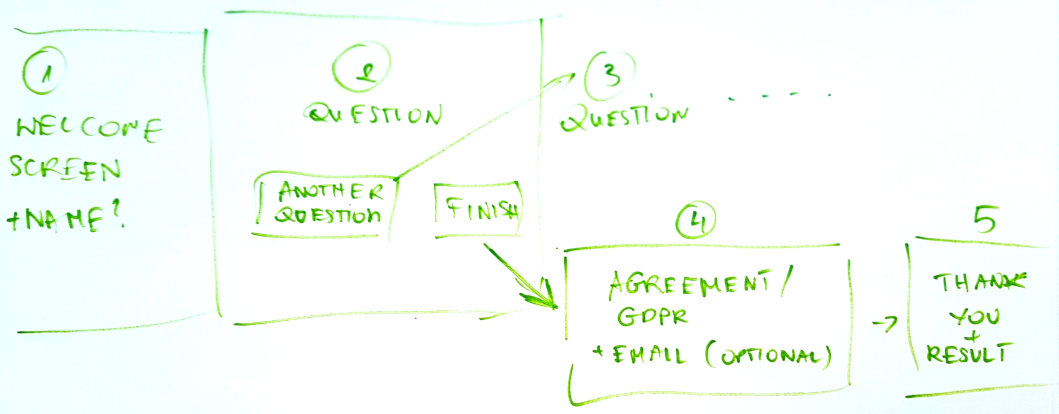
Here is a picture of how the flow will look like @hugi @matthias - it will be narrated, and it will be weaved in an exhibition space that will be a game, so answering the questions is a key part of the experience. We can change the flow,
But i think it makes sense in this order. We will later determine if questions will be a mox of closed and open ones, once we have ironed out the questionnaire itself (i am now at the biennale meeting and things are moving quite a lot as we speak with curators and mentors).
One more thing regarding quantities, the museum is visited by 7000 people during biennale, 30.000 in total. I am now also trying to have the interface included in other parts of the exhibition and the tool might be used by the curators for some qork they will then publish in the official catalogue. I think these are quite promising numbers @Alberto @nadia
We will start working on the design next week and then also on data visualisation options.
Please let me know if this is sufficient?
By this, do you mean that some questions might be multiple choice and others might be free text? This sounds like a questionnaire again.
By the back and forth with @alberto above over if it’s a questionnaire or not, I deduced that it wasn’t a questionnaire. If it is indeed a questionnaire with multiple questions, then agree with Alberto in that storing that data on the platform will create a lot of problems for you compared to if you use software built for that purpose. For example, you probably want to look at “answers to question 5 by everyone who answered YES to question 2”. This sort of functionality is built into any survey tool worth its salt and would be very tedious and clunky to somehow build into Discourse.
Ok, then we will stick to open questions, makes sense.
One more thing - would it be possible to have different final windows depending on keywords used in the questionnaire?
It doesn’t completely solve the problem. For example, you will struggle a bit to see all answers to questions number 4 or count the number of times question 2 went unanswered. On the other hand, this is basic survey software stuff.
What solves the problem then? It cannot be multiple steps situation? The idea is to gamify the experience and narrate the interaction in order to encourage more people to tell us more about the questions we want to research, hence the shape
Sure, it can be. But it really depends on exactly what you want, which is why @nadia asked for wireframes. Or a bullet point list of everything that it’s important that the software does. Without enough data going in on what you expect it to do - including how people interact with it, how you want to be able to analyze the data (perhaps you don’t need to dig into the data in the ways I mentioned).
If standard survey analysis functionality is important, we are much better off with off the shelf survey solutions. I personally think a paid subscription to TypeForm and some design work would do the trick. You can even trigger a custom designed email with a a step by step guide for how to sign up on the platform. Typeform also has an API and supports webhooks, so technically you might be able to build an integration to send data straight to Discourse.
If I was a consultant and you were the client, this is when we’d sit down to write some “user stories” before we make any rash decisions on technical choices or start designing. My time is a bit short today and tomorrow but I might be able to help you before the Borderland. But you might want to get started yourself.
Basically, make a bullet point list of statements that start with:
- As a X I can/want to X.
For example:
- As a user, I want don’t want to spend more than 5 minutes on this survey
- As a user, I want the graphics to be smooth and the experience to be fun
- As a user, I want to see how many questions I have left
- As a user, I want to be able to opt out of getting emails after I finish the survey
And
- As a researcher, I need the ethics funnel to be watertight and approved
- As a researcher, I want to be able to see only the answers to a specific question
And
- As an admin of the platform, I want to be able to quickly update any question myself if there are mistakes
Once we have this, it becomes much easier to make a decision on how to do this. Right now we are speculating way too much.