We are Edgeryders, an Estonia-incorporated SME with a Brussels office. We live in symbiosis with a 4,000+ global online community with roots in hacker culture. That lead us to build up considerable expertise in harvesting collective intelligence.
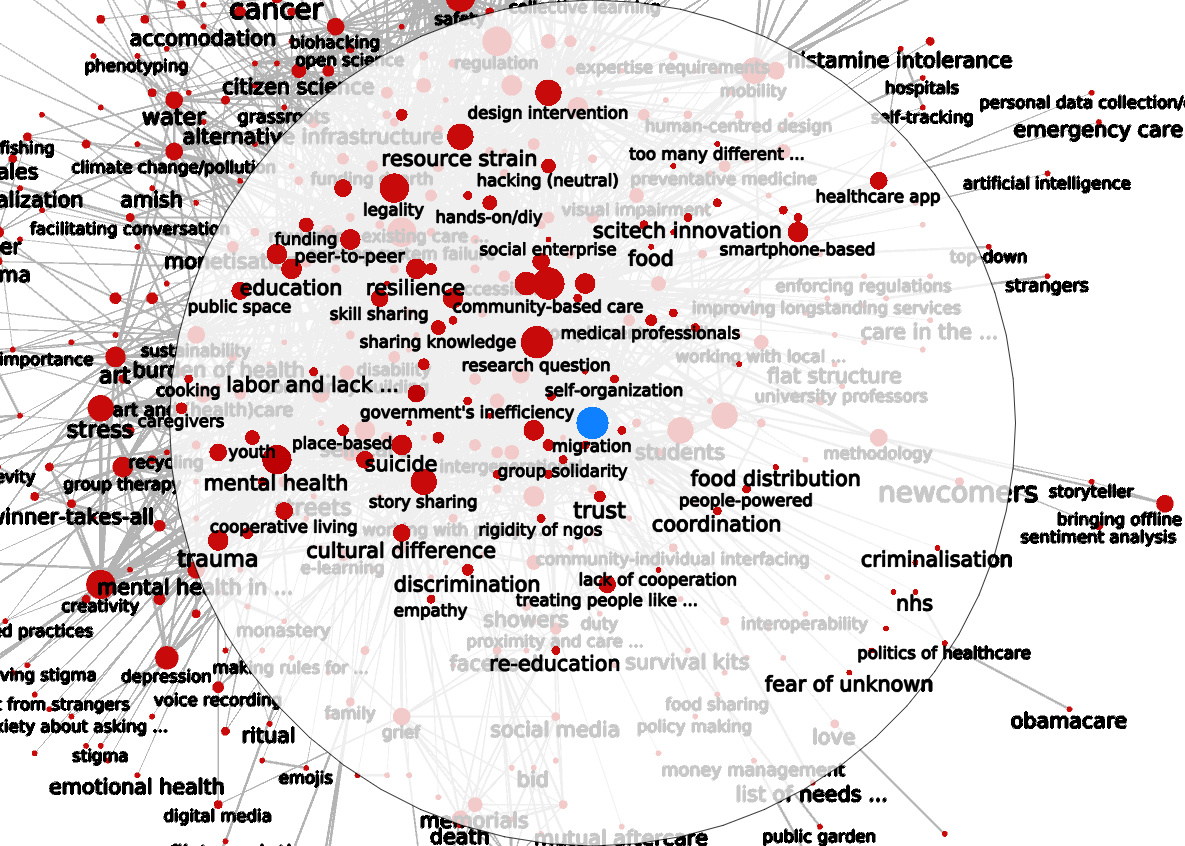
We do this through a novel method called Semantic Social Network Analysis (SSNA). The main idea is to foster an online conversation; perform ethnographic coding on it. Then, we build a network of ethnographic codes that surface in the conversation. By associating codes, participants in the conversation connect them to each other. This process induces a semantic social network, which we can then study with quantitative techniques. You can think of it as a collective mental map of the problem at hand. We have developed software to navigate this map, and filter it to produce high-level “big pictures”. With it, human researchers can make sense of very large graphs, with thousands of contributions and ethnographic codes.
This method is a good fit for Horizon 2020 projects. Many calls reward proposals who ensure citizen participation and/or diverse stakeholder involvement. We can provide those, at scale. Ethnography is great at hearing the individual voices in a crowd; and SSNA can handle very large ethnographic exercises.
A natural application of SSNA to Horizon 2020 is Coordination and Support Actions. These actions work by bringing together communities working on one issue. The resulting interaction produces written traces, and we can encode them into a semantic social network. This produces quantitative indicators on the conversation the action is meant to support.
We would love to join high-quality Horizon 2020 partnerships, and bring them SSNA. We are hard working, deadline-hitting people. Happy to write our own work package. If this sounds interesting to you, get in touch with Anique Yael Vered, Research Coordinator.
More information:
- An interactive example visualization. It describes an ethnographic corpus about community-provided services for health and social care. It includes about 4,000 contributions (about one million words, mostly in English) authored by 336 informants all over Europe. Ethnography journals normally consider a study publishable when it has 6-20 informants.
- A paper describing our method.
- A short video on SSNA.
- About Edgeryders.
3 Likes
Hi Alberto and Anique, this sounds really interesting for the Teal for Teal community, a community around reinventing organisations. We are also closely related to Enlivening Edge. At this moment we are starting to build a Platform and in doing so we are working together with EyeOnText to allow for Natural Language Processing in the core of the Platform enabling learning though discovery. … Could we explore this further please? Carolina from EyeOnText will mail you Anique. Thank you, Stefan Groenendal
1 Like
Wonderful to hear of your interest @sgroenendal. I’m somewhat familiar with Laloux’s work in Reinventing Organisations and of course am open to exploring further… Looking forward to hearing from Carolina and we can talk more.
Hello Stefan @sgroenendal. Happy to discuss, of course.
I looked into NLP a year ago. My provisional conclusion: at our scale, shallow NLP is robust but of limited usefulness (probability of “house” conditional to “brick” coming first). And deep NLP is unworkable, because it requires datasets of several orders of magnitude larger than the ones we can reasonably produce. In Masters of Network 6 we tried out a very simple machine learning algorithm for topic extraction on the opencare corpus. To even get the model to run, we had to use a technique called bootstrap. This meant resampling the same corpus 100 times.
Lesson learned: for doing machine learning on text analysis by brute force, you need a lot of text. At that point in time the opencare corpus had about 2,500 posts, with about 600K words. It took a year and a lot of money to get it together. And for ML to work, we would have needed at least 250K posts with 60 million words! The whole of Edgeryders at this time (after 6+ years) is a bit less than 40K posts, maybe 9 million words? It’s interesting, but our of our league.
I would have thought by now it might be possible to achieve something with smaller samples, but I guess not. Back at SF Gate we had news from several feeds and wires and we automatically categorized and “slugged” the stories using NLP and ML, but in order for it to work accurately we had to have it analyze several years worth of news stories first. That was a lot of data, similar to what you describe above, and it did work but it needed that big load of data.
Hi@anique thank you. I was away the whole weekend and Carolina has the flu but she’s recovering. Great you are open for exploration. Will get back asap.
Hi @alberto great you are open to discuss it. I just had a brief chat with Caro (she’s recovering from a flu) and it would be good to discuss your view, EyeOnText view by Caro and what we want as Teal for Teal Platform (that’s a work name by the way). In short on the Platform we want to combine AI and CI (collective intelligence).
These views differ substantially looking at it quickly so there is opportunity in it  Will get back to you asap.
Will get back to you asap.