This is a list of things I propose to do on the draft paper before submission.
I created a new section 4.1, following up on the intuition that the number of codes needed to describe a conversation scales more slowly than the conversation itself. I also used this to teach myself some basic Pandas and how to use JuPyter with Anaconda. @markomanka had this really intriguing intuition of ethno coding as lossy compression, and that would deserve some comments, but I am out of my depth here. Maybe @melancon can do that instead.
Rip Amelia’s walkthrough off section 3.2 and move it to section 4 (section 3.2 could end at “0.711”). The first part of Amelia’s text, dealing with a filtered graph (maybe up to “doing work on the issues”), could move onto 4.2, replacing some of my own text there (“Consider for example the cluster…”. The second part, that zooms in, (“A colleague of this decision-maker”) could go into 4.3, again replacing my text. Assigned to @amelia.
The whole walkthrough needs a re-examination, because it is written in terms of the Graphryder software (“clicking on the edge, one sees…”) rather than in terms of SSNA as a method. @amelia
And of course we need to decide whether to update both the walkthrough and Figure 4 to the new data. I would say yes, I think the walkthrough would not change much. @amelia for the walkthrough, @alberto for the picture.
Section 3 needs updating with the most recent figures and network stats. This would be @jason_vallet.
A new section needs to be added (perhaps after 4.1; it would become the new 4.2). with Guy and Jason’s latest work. My biggest problem there is that this is becoming almost a paper in and of itself! I suggest a very short version of it, plus an appendix to illustrate the methods. Later we can even expand the appendix in a new paper. Assigned to @melancon.
Re-read everything. Make the necessary changes to the introduction and the conclusion. Assigned to everyone.
Taken, @markomanka. Authorship offered, obviously. It seems the path of least resistance; the idea is yours anyway, and whoever uses it needs to acknowledge you. Plus it’s great that we make an interdisciplinary paper with authors from 3 opencare partners.
I will deal with paragraph 4.1, then, and the conclusions (I guess?) …or should there be other references to the concept elsewhere in the manuscript that escaped my attention?
Marco, please note I checked my code, corrected several mistakes, collapsed the two figures into one to optimise the space, and revised the text accordingly.
Can I ask you how many words where produced in the last six months of opencare online conversation? In absolute number and in percentage as compared to the total?
Could I also ask you to include in the computation the codes that predate 2016 AND were used to code opencare? From the project point of view, the first time they were incepted in the coding of conversations is essentially the moment they were generated.
If we exclude them tout-court from the calculations, we bias our quantitative analysis of the dynamics of ethnographic coding…
The computation is based on the annotations authored by @amelia. If she re-used pre-existing codes (I doubt it) those are automatically included. Pre-opencare annotations on old content are not included.
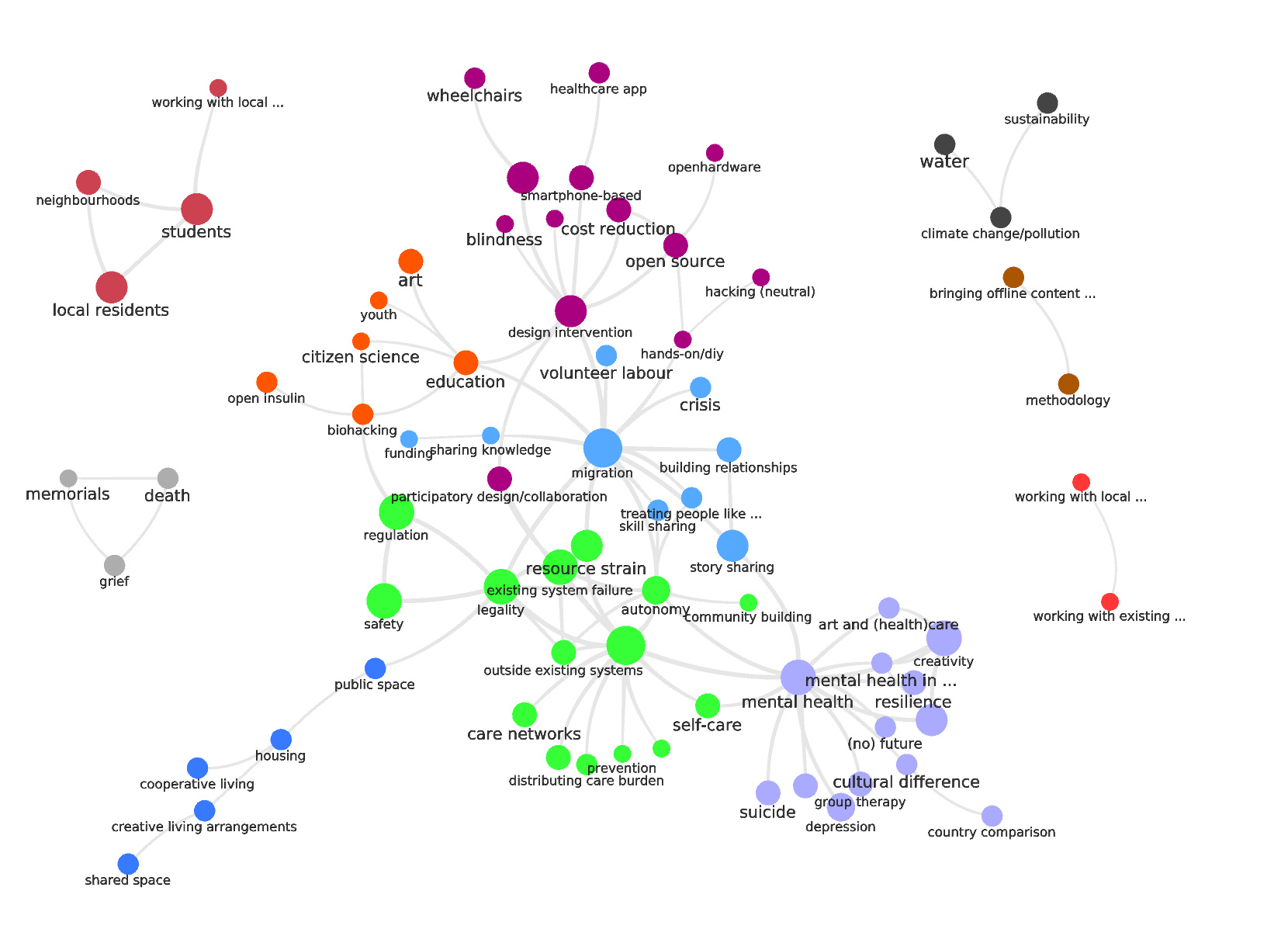
Here. See which one you like best. As always, color encodes communities of nodes. Do you know how to upload it onto Overleaf and include it into the LaTEX file?
Notice how the Golden Triangle legality - regulation - safety is, with all three levels of filtering, part of the core cluster with the mothership code community-based care. It means the partition in communities of the nodes is pretty solid (Louvain modularity = ~ 0.6).
Also note that I have manually zapped the accursed research question. I think we should zap it from the database, in fact…
OK, sounds good. I think it has probably been more annoying than useful to us ultimately. Maybe it would be good to grab all the text associated with it, then zap it, if possible.
I like the k>5 visualisation the best. I’ve edited the paper to make sure the walkthroughs makes sense with that visual. If it’s easy for you to do, it would be great if you could pop the image in — if not, let me know and I will sort it out.
I’m also happy with the k>4 one as well, since it shows more. Both walkthroughs can be seen on both, so either is fine. I just think the k>5 is clearer.