So I just finished the software design for Open Ethnographer. It’s the basic architecture, still allowing features to be added and removed while the requirements become clearer.
But you can already get an idea of what Open Ethnographer will be like. It will be based on eComma, which is great find: an open source “commentary machine” module for Drupal, just recently released. This is how eComma looks right now:
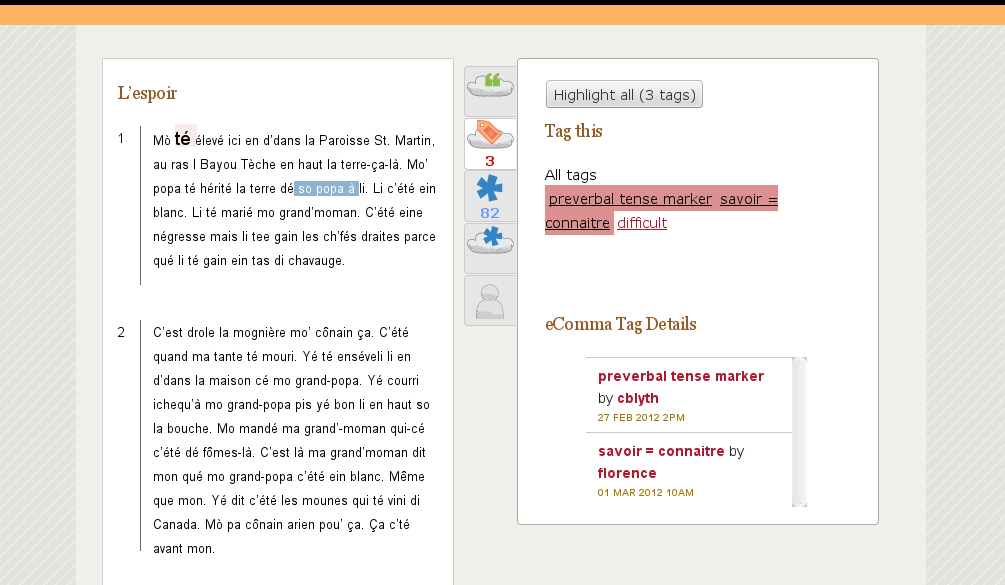
And here’s the rest of the sneak preview – no screencasts, sorry, you have to invest some imagination:
- Look through the eComma mini-manual (section "User Manual").
- Then try the eComma live demo yourself. Tagging does not work there as you have no login, but that does not matter as we'll do it a bit differently anyway:
- Try out the Annotator live demo to see how tagging will work. Just select some text and click the button that appears. Tag selection and some other stuff will be differently though, so:
- Finally, read through the implementation tasks to get an idea of how we will extend the eComma software to be also a code manager and coder for open ethnography. By making it both, we will share the maintenance effort with the eComma developers. Beauty of open source!

Did you get the idea? Do you have feedback or criticism for the basic architecture and feature set? (It’s really just about the basics for now, details are better handled on the go.)