Ok, guys, thank for the great work, and let’s get the paper started.
Step 1: figure out the journal, which will give us a format, page limit etc. Needs to be open access. There is a Journal of Computational Social Science, but not sure it is a good fit (only person I know in the editorial board: Stefan Thurmer, who used to be a collaborator of David Lane).
Ethnography’s Kitchen’: a ‘how-to’ section featuring critical reflections on the practice of fieldwork designed to foster reflexivity in ethnography so as to clarify and bolster the standards of the craft.
I don’t know anyone in the editorial board, but that’s no surprise. Also, not sure it is OA.
I think Ethnography’s Kitchen sounds perfect! The Commission is happy with Green OA, which our article can be as long as we deposit the pre-formatted version in an open depository.
This would normally be acceptable in SAGE journals (source), subject to the specific journal’s policy. I can find none for Ethnography. You can go OA Gold for 3,000 USD (source), which I would not do because I morally object to the business model of academic journals.
Hello,
The ethography journal is ranked Q1 in the journal ranking we use (Ethnography). So that is fine for us.
The aims and scope of the journal seem fine too.
Ok, ethnography looks like it is a strong candidate. The length limit is 9,000 words, including everything. The Field Methods article, for which we suffered badly from too tight a page limit, is 3,803, including the bibliography but not captions (@bpinaud, can you check that I am correct? This is my source).
I have set up an Overleaf project, using the SAGE Template. There are two things to check on the file, before we dive in: could LaTex wizard @bpinaud please do the checks?
The references style is set to Harvard, which is correct for Ethnography. But the template uses bibliography items in the main. I would prefer to re-use the bibliography file from our previous work, while preserving the Harvard style. Is there a way to do it, Bruno? Notice that TextCount does not support biblatex.
I set up the file for word count. This will now make Overleaf’s word count utility include in the grand total the bibliography, but not the captions. I am not sure that we can get the utility to also include the captions. Is there a way to do it, Bruno? If not, should we use the command-line textcount tool? Or what? Documentation here.
Here is the edit link:
I am also breaking this topic up. The part of the thread about the new paper goes into a new topic.
Just to add my two cents. I feel the How-to section of the Ethnography journal would fit the spirit of our contribution and audience we are targeting.
OA yes, but with a significant fee of 3000$US … Not sure who among us can cover this … (certainly not me).
I do not feel our paper fits ANS, not technically dense enough – unless we can bring in more meat, but at the price of diluting the message we wish to send the Ethnography community.
create an outline on the Overleaf, with a breakdown into sections.
sections are then assigned to individuals or smaller groups (for example: Jan, Richard and Amelia on the rationale for network reduction in a way that does not break the accountability of the ethnographic research project. Guy and Bruno on the computation. Me, everywhere )
during the summer we write drafts
after the summer, we hammer them into a final version, commit to Zenodo and submit.
Hello friends, I would be happy to resume this work if you are up for it. Here’s a high-level overview of the paper as I see it.
We introduce the methodological challenges connected to mixed qual-quant methods
We explain our method in general, and the role played by network reduction in it. This implies introducing the codes co-occurrence network (CCN).
We explain the two main methods of reducing the CCN: based on association depth d(e) and based on association breadth b(e). See the Overleaf draft (not yet formatted for Ethnography).
We compare the two methods. I was thinking of doing this in three steps.
First, take the dataset(s) and compute the reduced network(s) for d(e) >= 2, … , d(e) > = n. Do the same with b(e).
For each i = {2, …, n}, j= {2, …, n}, compute the Jaccard index of the two reduced networks induced, respectively, by d(e) >= i and b(e) >= j*.
At this point, put the Jaccard coefficient (as suggested by @bpinaud) into an i x j matrix. This makes a sort of heat map, where you can see how the Jaccard varies as i and j change.
We introduce two more reduction methods: one based on k-core decomposition, the other on Simmelian backbone. These two methods are “topology oriented”: the most important edges in the network are found based on its topological characteristics, rather than on the characteristics of the individual edges. These can be kind of tricky, however, because we have two choices: either we treat edges in the CCN as unweighted when computing k-cores and Simmelian backbone, or we have to select one of the previous two values as the edge weights. If we go for the weighted edge solution, there is also a mathematical problem: possible values of k in the k-cores have a much larger span than d(e) and b(e). I do not have an intuition for the range of the Simmelian backbone’s reduction parameter.
Assuming these problems can be solved, we need a systematic way to compare these four methods. The simplest one might be to stay with our combination of Jaccard coefficients and heat maps. The representation I have in mind is a symmetric (or triangular, to avoid repetition) matrix with the four reduction methods on both the rows and the columns. Each cell contains a heat map as described in item 3 above. Of course, on the diagonal the heat maps will be degenerate (the Jaccard coefficient of a reduced matrix with itself is always 1), and we can ignore them. This leaves six meaningful comparisons.
If the problems related to the range of the reduction parameters are not solvable, then we need a different strategy to compare reduction methods to one another.
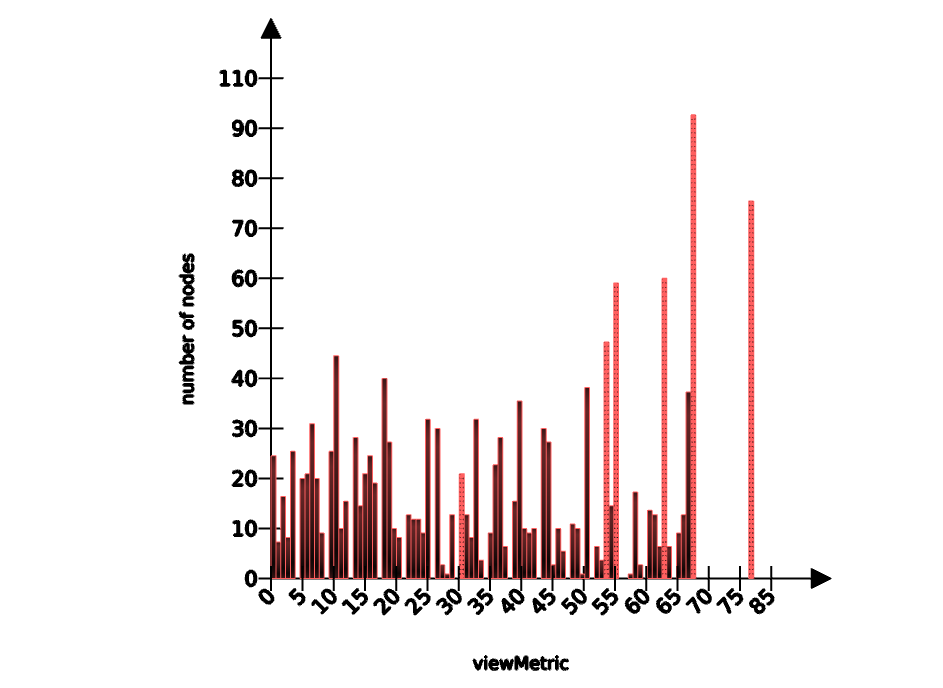
Follow-up on k-core decomposition: I tried it considering edges as unweighted, and the maximum value of k is 112 for NGI FORWARD, 82 in POPREBEL. The distribution of nodes by highest-k k-core is interesting. This is POPREBEL:
Taking only the very highest-cohesive subgraph (k=82) leaves about 75 nodes. At the other hand of the spectrum, starting with k=0 and increasing its value is not a very good strategy to reduce the graph, each increase in k only eliminates 8-25 nodes.
Today @Richard, @bpinaud and I got together for a quick overview of where we are with this paper. Some work has been done in:
Interpreting two of the reduction techniques: counting co-occurrences, which we are now calling association depth, and counting the informants who have made each co-occurrence, which we are now calling association breadth. Recall we are interpreting edges in the codes co-occurrence network as associations. This is here.
Computing Jaccard indices among the two (spoiler: they are low).
We appear to need three things:
Team netsci (Bruno, @melancon and myself) needs to do more work on network reduction via two more reduction techniques, which have not been mentioned in the IC2S2 presentation: based on k-cores and based on Simmelian backbone. For k-cores, Tulip has a solid plugin and I can do some exploration myself. For Simmelian backbone, Guy has written a plugin but Bruno wants to check the code.
Also team netsci to hammer out a “good” size of the reduced network. This boils down to a list of criteria (eg. number of nodes, number of edges, density…) based on the netviz literature. Guy is the master here, and we expect him to lead this part.
team anthro/socio (@Jan, @amelia – after her PhD delivery is in the bag – and Richard himself) is expected to lead on related works and conclusions. For related works, remember that the main thrust of the paper – after Jan’s contribution to the IC2S2 presentation – is “facing the epistemological crisis” in qualitative research, as fast methodological innovation risks putting the accountability of research in jeopardy. For conclusions, we need to make an extra effort to interpret and explain the choice of a reduction technique to an audience of ethnographers. For example, if you choose a method where “important” edges are those that reflect agreement between a larger number of individuals, what are the consequences of this choice for the interpretive work that the analyst needs to to on the reduced network? What are the pitfalls?
Richard suggested that the work of team anthro-socio could be facilitated by seeing some computational results first. Bruno and I and Guy (though we have not yet spoken to Guy) will try to prepare a mini-presentation to the co-authors to be delivered on October 14th at 16.30 Brussels time.
We should aim for submission, and upload on Zenodo, by December 10th.
Many thanks. Richard just briefed me. We will wait for Amelia and will start thinking about our contribution next week. Yes, seeing some results would be very useful, so we can start “spinning” interpretations. I have downloaded the paper from Overtleaf and will study it this week. I am really looking forward to our work together and finishing this product for publication. 16:30 (my 10:30) October 14th in my calendar and it works. Ciao.
 )
)