So, tonight I delved into the data, but I soon ran into a data issue. There are people who authored posts in topic tagged with ethno-rebelpop-deutsch-interviews who do not appear in @Richard’s and @Djan’s “German gender” file. The latter has 41 entries, but I find 44 forum users in the dataset (one of them is Djan!). For your convenience, I have created a new version of the file which contains all the usernames, and put it here.
Hi Alberto. Djan and Sabine (Biene) were the interviewers. I only coded their questions if the subsequent answers didn’t make sense on their own (e.g. monosyllabic). The other ‘missing person’ was GERAnnette30b. I had overlooked her interview but have now coded it.
2 Likes
Thanks, @Richard! Here’s a first look at the data. Also ping @Nica and @Djan.
The German corpus is coded with 847 codes, which have their ancestries in 77 additional meta-codes. The corpus has 28,119 co-occurrence edges, derived from 2,311 annotations. The participants are 42 + 2 interviewers. 32 informants and one interviewers are female; the remaining 10 informants and single interviewer are male.
I created co-occurrence networks by gender based on this file. The gender difference is large. The following table shows the number of codes and co-occurrence edges that can be found in the annotations of interviews with females, males, and both genders.
| All co-occurrences | codes | edges |
|---|---|---|
| females only | 299 | 4769 |
| males only | 341 | 5903 |
| both | 284 | 354 |
| overlap coefficient | 0.48 | 0.06 |
A visualization of this situation can be seen below. This graph is already reduced: it shows the 970 edges representing co-occurrences with association depth d > 2, in either gender. Green edges are derived from interviews to female informants, orange edges from interviews to male informants. Green nodes represent in codes associated only to interviews to female informants, and orange nodes represent codes associated only to interviews to male informants. Gray nodes represent codes associated to interviews to informants of both genders.
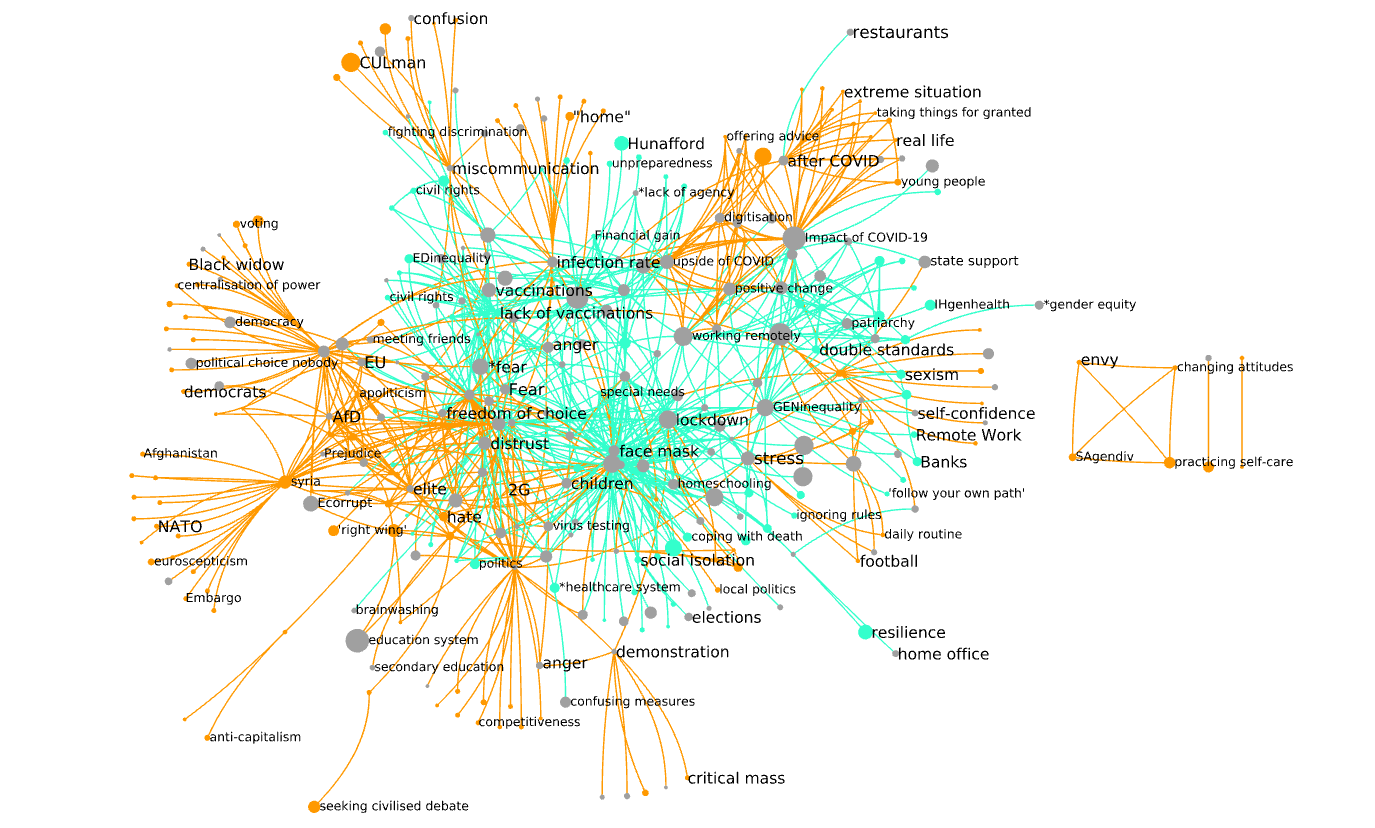
Below, you can see the deepest associations (d > 4) evoked by males (59 codes, 98 edges) and females (69 codes, 150 edges)
While now most nodes are gray, representing codes associated to both male and female interviews, that does not mean that the two genders share the deepest associations; a code is colored gray if it is used at least once to code an interview to a female informant, and once to code an interview to a male one. Indeed, there is little overlap also for the deepest associations.
| d > 4 | codes | edges |
|---|---|---|
| females only | 69 | 144 |
| males only | 59 | 92 |
| both | 14 | 6 |
| overlap coefficient | 0.24 | 0.07 |
Here is a list of shared codes
'Unvaccinated', 'Vaccinated', 'negative attitude', 'face mask', 'stress',
'working remotely', 'upside of COVID', 'Media', 'impact of COVID-19',
'social distancing', 'infection rate', 'employment', 'Impact of COVID-19',
'LAinsecurity'
And here one of shared edges
('face mask', 'social distancing'), ('Unvaccinated', 'Vaccinated'), ('LAinsecurity', 'stress'), ('upside of COVID', 'working remotely'), ('working remotely', 'Impact of COVID-19'), ('employment', 'Impact of COVID-19')
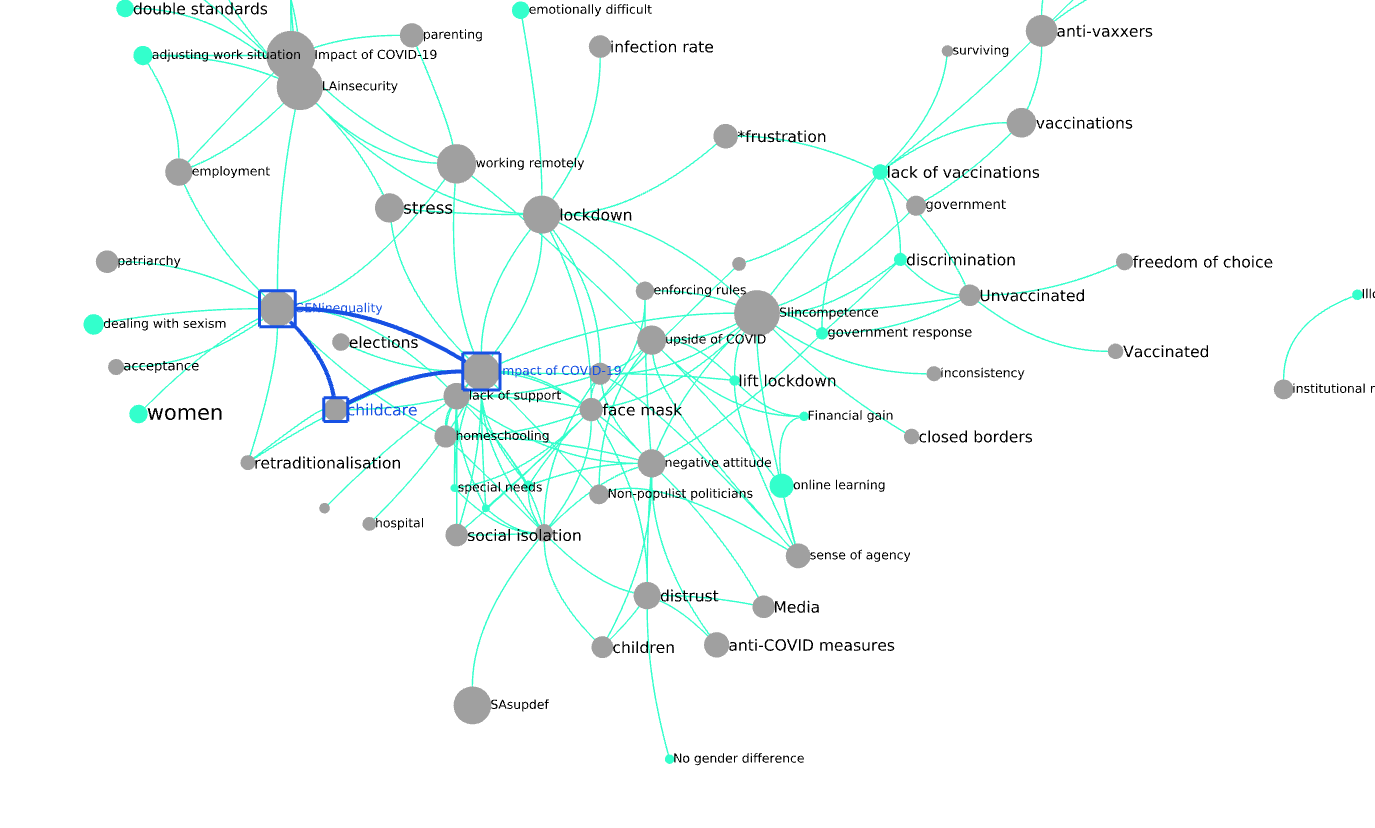
The very strongest edges (both in terms of depth and breadth) are highlighted. In the female graph, they form a triangle between GENinequality, impact of COVID19 and childcare:
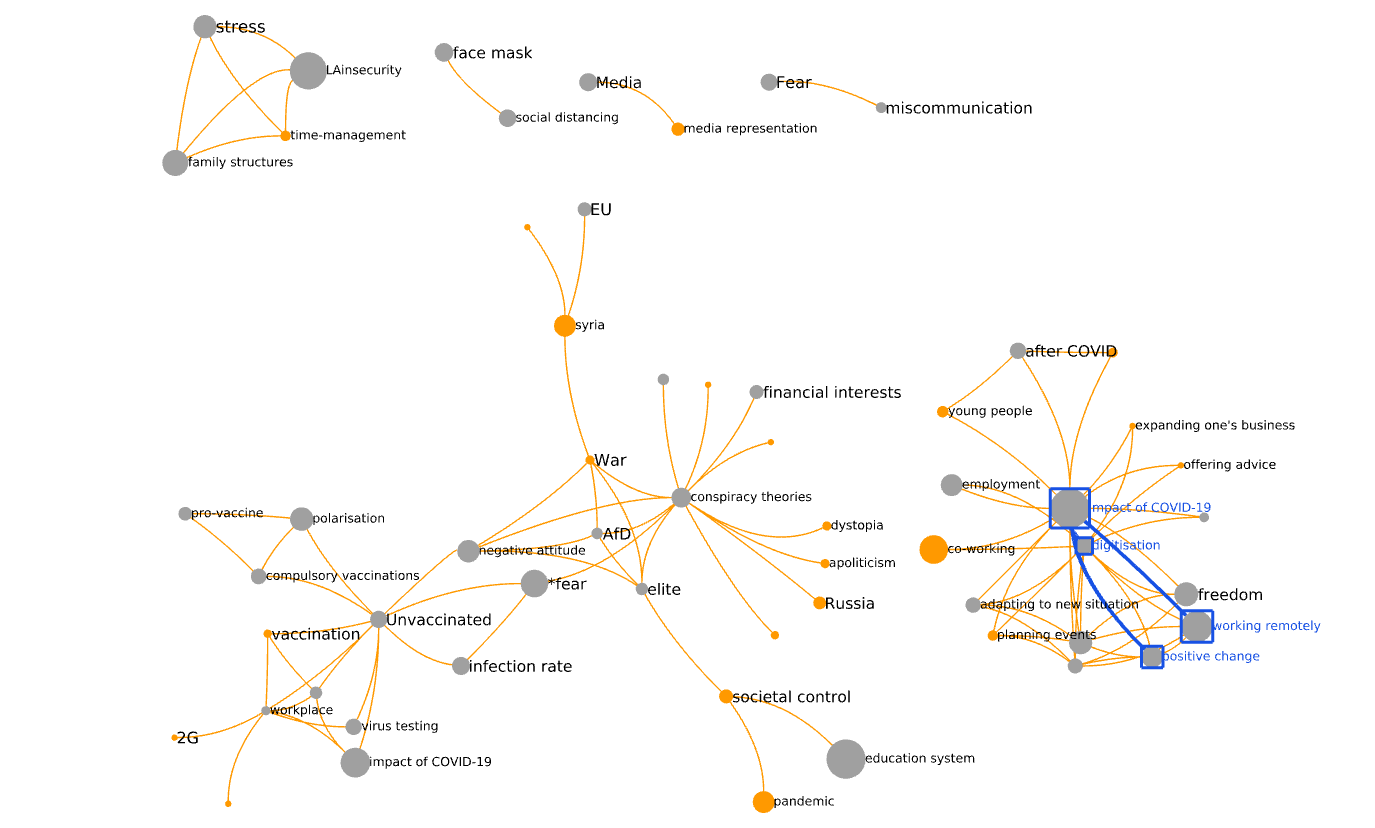
In the male graph, some of the highest-d edges have b=1. So, the choice of the strongest edges is more difficult. Provisionally, I chose the three strongest-d edges with b > 1. They form a star, connecting impact of COVID 19 to digitisation, working remotely and positive change.
1 Like
Thanks @alberto ! The difference is really interesting. So would this reflect the idea that the Covid-related labor practices modifications exacerbated the gendered division of labor inequality, with women having a more negative experience (maybe the burden becoming greater on them) and men having a more positive experience (advantages of working remotely without having their labor share increased)?
@Richard do you think this fits with the idea of re-traditionalization of gender roles that emerged as one of the most salient points from the German data?
2 Likes
Guys (especially @Richard and @Djan, but also @Jirka_Kocian), I still have a bit of mud in the data. It comes from two sources:
Problem 1: duplicate codes
Last week we saw this in impact of COVID-19, that since has been fixed. But there are others, for example responsibility and stress, and many others. I attach below a list of the 925 codes (!), including parent codes, used for this corpus. It’s in alphabetical order, so you should easily find the duplicates.
Problem 2: inaccurate labeling by language
In many codes, the English label was recorded in the database field of the label in another language, normally (in this corpus) German, but occasionally others. For example, vaccination: https://edgeryders.eu/annotator/codes/9853. The “tidy” way to record this code would be to click on “Edit”. Then, in the Edit screen, click on “Add” and do this:
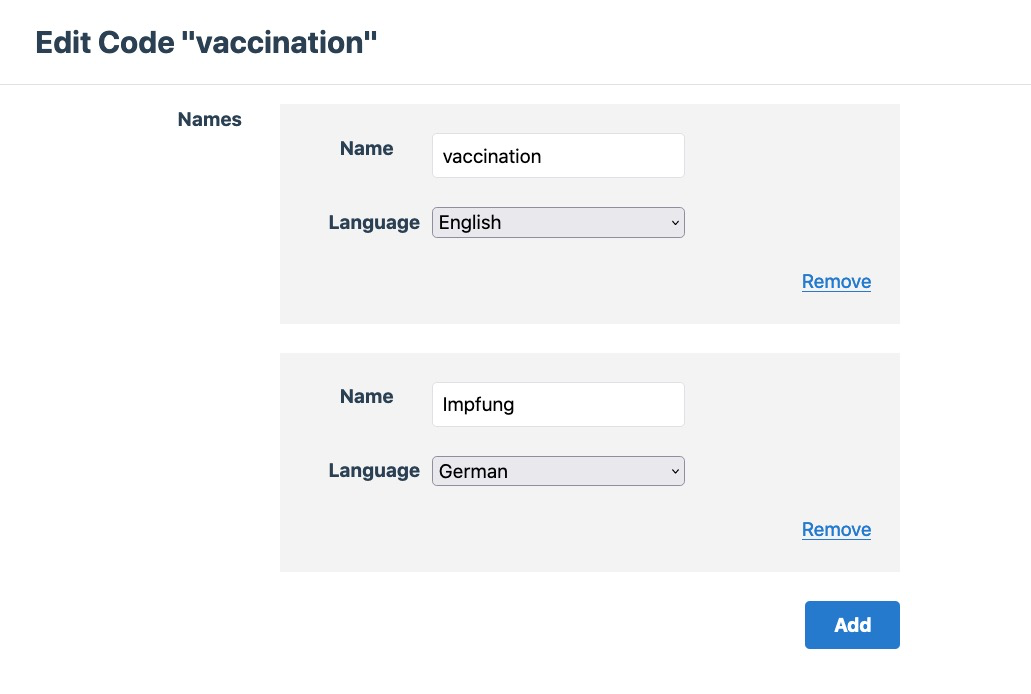
Of course, it is not necessary to record the German name for vaccination, as long as we are reasonably sure that there are no special connotations to the German word (presumably used by informants) that are missing from the English translation.
There are 206 codes with no English label, only a German label. Some of those labels are, correctly, German expressions (example: von dem Staat verlassen). I can easily make Tulip copy those labels into the field for English labels, but the problem remains in the database. This problem compounds that of duplicate codes, for example, there is a code vaccinations (label recorded as English) as well as vaccination (label recorded as German).
There are also 12 codes for which the label is recorded neither in English nor in German, but only in Czech. 11 of them have labels in English, though with some kind of superimposed tagging (example: DDeliteestrangement). The 12th is called pobyt v lázních.
Solutions
The solution to problem 1 is, unfortunately, manual merging of duplicate codes. Coders’ attention is the only way to make sure that the two codes being merged really encode the same semantics, and which one needs to be merged into which.
To help it, I created this spreadsheet. Preview:

The field “Name” was created by copying name_en where it exists, name_de otherwise, and name_cs when neither of the other two exist.
The link allows quick access to the back end.
Not sure about how to solve the labeling inconsistencies. @matthias, is it worth going by API call?
By this I mean:
for code in codes:
if code ['name_en'] is empty:
if code ['name_de'] is not empty:
code['name_en'] = code ['name_de']
If the German name is also empty, the script keeps looking until it finds a label it can use.
Words from code names are not necessarily found in texts by informants Code names also do not define a code – rather, the description does. The multi-lingual code labeling system is only meant to aid ethnographers who do not speak English, or do not speak it well. (Even then, they have to understand the code descriptions to apply codes correctly, and these descriptions are so far only available in English.)
In total, multi-lingual code names have probably not served us well, as they introduce complexity, making it harder to keep the database tidy.
Codes with only non-English names are allowed in the database, as that would be their initial state after being created by non-English-speaking ethnographers, and before being translated by their colleagues. For those cases, using these non-English names as fallback options when determining a code’s display name (as in your example code) would be a good approach. Open Ethnographer uses similar fallback mechanisms for determining display names in some cases.
But, an English code name in the field for a German code name is an inconsistency. Inconsistencies should be fixed in the database, not with Tulip code. We have the Translate View in Open Ethnographer to let ethnographers fix these inconsistencies efficiently, and also to add missing translations efficiently. (In the Open Ethnographer code list, use the “Discourse Tag” and “Creator” filters to select a suitable code subset, then choose “View: Translate” in the top right. With the Translate View, you always translate between English code names and code names in your preferred language; adapt your preferred language in your Open Ethnographer user preferences if needed.)
Speaking of inconsistencies, I saw some stuff that I’d rather not expect in Open Ethnographer data and that should probably be fixed:
-
Some topics, including from POPREBEL, are coded but are not assigned to any corpus via a Discourse tag (example).
-
There is a Discourse tag ethno-poprebel and another one ethno-rebelpop. What’s up with the latter? Similarly, there is both ethno-poprebel-german-interviews and ethno-rebelpop-deutsch-interviews and so on.
1 Like
Dear Alberto and Matthias
It was initially decided to code in the original language. I didn’t see the benefit of this but I did the coding in German, as requested. A decision was then made to do all the coding in English. I have made a start on translating the German codes into English and making sure that the English codes are in the correct ‘box’.
We’ll need to double-check with the other coders but my understanding is that tags beginning with ethno-poprebel can be ignored (certainly for German) and we are now only using ethno-rebelpop.
I’m taking a few days’ leave but will focus on this on Wednesday and seek to sort this out by the end of the week.
1 Like
Update:
I have now gone through all my codes for ethno-rebelpop and there should now not be any codes without an English label. Some codes have both an English and German label but, as discussed, we don’t need the German label for visualisation purposes.
I’ll now move on to the issue of duplication.
1 Like
PS:
I noticed that under the headings ‘PED’ and ‘PIH’ (Y categories?), there are some descriptions without codes. I don’t know how that is even possible.
Also, some Y and Z codes seem to have been merged into single labels:
adapting to a new situation Z Social and Political Processes – Category
positive change Z COVID-19 – Category
effects of COVID-19 Z Actions and Activities – Category
state supportZ Actions and Activities – Category
travelZ Institutions – Category
family structuresZ Problems - Category