Yes, of course, @alberto thank you for the time zone alert, I meant mine and @Jan’s morning. Yes the plan was for 14.00 (8 am our time) and there was no firm length specification – I would be available after (so, at 15.00 or 15.30 or 16.00 or later).
OK, I’ll log in at 15.30.
OK. See you at 14.30 UK time (I think!)
1 Like
Ok, guys. Sorry for being so silent during the meeting. After several hours of going through tutorials, forums, and trying different releases I finally managed to get Tulip to work on my machine. Sadly, it’s a non-python version, so for now, until I get a reply from Patrick, I won’t be able to author any new scripts. But, other than that, it’s working like a charm.
Hello @icqe22_authors, here’s an update from me.
1. Pre-processed Tulip files
I have made a folder with new versions of the four files. They include some pre-processing:
-
Edges now color-coded for the relevant measure (association depth, association breadth, redundancy for the Simmelian backbone). Edges are hidden in the highest core values file, which you are better off seeing as a list of nodes and analyzing from the spreadsheet view.
-
Nodes size-coded for annotations count
-
Catholic Churchcolored differently, and pre-selected. You can (and should) play around selecting different nodes and edges, but even when you deselect it,Catholic Churchwill maintain a different, bright color. Beware: when it is not selected it could be hidden by the algorithm.


2. Use Tulip 5.4 (at least on Mac)
The stuff that would not work for me in today’s meeting turns out to be an artifact of Tulip 5.6, the latest release (5.6.2 is the one you have, I was on 5.6.1). Today I re-installed 5.4, and now they work. If you have the same problem as I, do as I did. The following things I think are useful for the present analysis, and now work:
-
The ego network interactor. The interactors are a row of buttons at the top of the node-link diagram. Hover on them until you find
Highlight the node's neighborhood, then hover over any node to highlight its adjacent edges. -
The instant resizing/densifying of the labels. In the node-link diagram, click on the vertical tab
Scene, then experiment with theLabelsslideRs: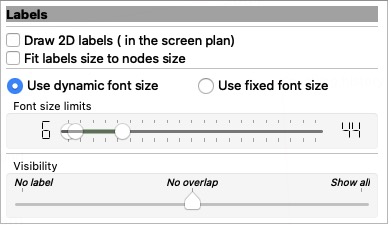
In the
Font size limitslider, what matters is the left circle, representing minimum size. Recommended value is 6, but that depends on your screen and preference.

3. Computation checked
I checked the association breadth graph, and even redid the math based on my own code, but I get the same results as Bruno. I have checked the vicinity of Catholic Church, abortion and Civic Platform Coalition, but I cannot see anything wrong.
4. Web dashboard
ONLY for association depth, there is an alternative to using Tulip, and I think it is superior, because it is made specifically for exploring graphs representing ethnographic corpora, whereas Tulip is a much more general framework for the computation and visualization of any graph. It’s Graphryder. It requires its own demo, unfortunately, and I am reluctant to put any more stuff on your plate. However, if you do want to push on with it, here you will find some short videos where @hugi explains its main features and concepts.
Also note that Graphryder implements association depth ina slightly different way than that explained in the paper.
2 Likes
Google Doc to work on the draft: ICQE 2022 POPREBEL Paper Ethnographic Input - Google Docs
Let’s put all our thoughts in here so we can further our work on the paper!
1 Like
Hello fellow authors! I made a copy of the document as it was earlier today (and shared the copy with all of you to preserve all the notes and comments), and then “cleaned up” the document we have been working on collectively so that it’s mostly the draft of the section. What I drafted is in blue – it’s the sections on the four reductions. @Maniamana – the beginning of your section remains in green above for you to complete. @Jan – please read through what I drafted and weigh in/edit as you see fit, and please also see the specific note I left for you, asking for the references you had mentioned about public opinion in Poland.
After we are happy with this draft, what will remain is one last (short? probably short) paragraph – a coda – but I figure we can write that last, once everything is already in Overleaf.
@alberto – I added copy/pasted bibtex references in comments on the draft (either stand-alone comments or in responses to yours).
2 Likes
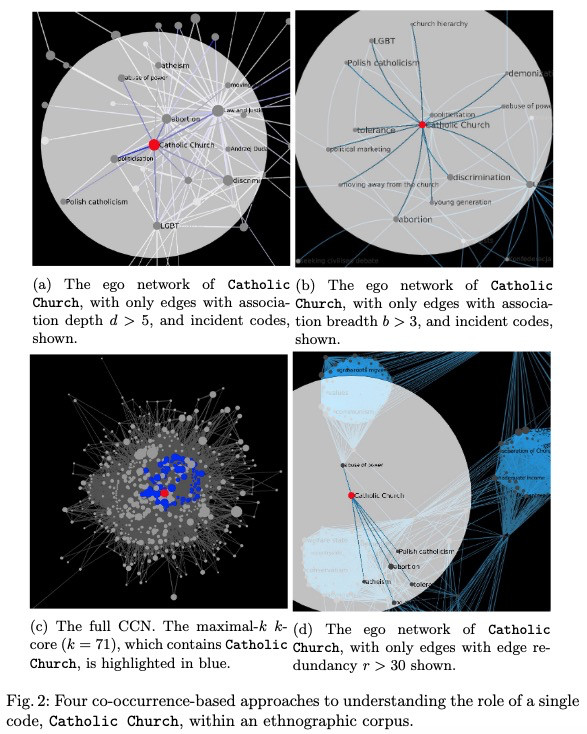
Meanwhile, I created the figure. It is already visible in the Overleaf project. I also put the figures in the paper submission’s GDrive folder; and updated the Tulip files (in the same folder) so that you can explore them interactively if needed.
1 Like
Ah they look so pretty!!
1 Like
(and very clear)
One is glad to be of service ![]()
1 Like
@Maniamana are you sure there are 17 interviews? I see 33 topics: https://edgeryders.eu/tag/ethno-icqe2022
Important: the submission deadline has been moved to May 30th
@icqe22_authors, a first full draft is now visible and editable on Overleaf at this link. Looking good. We even have some space to spare!
My main comment is this: I missed some more explicit information as to how we processed the data. For example, which level of the respective reduction parameters we chose, how we chose them etc. I have tentatively added this information interspersed in section 6.
Next up: please, all read the whole paper and use the comments functionality to add your comments. I already put in some of my own – please read (especially @Nica) and resolve as appropriate. Please do not comment using colors or similar, let’s try to keep the LaTex code clean.
Given that the submission deadline was moved, we can probably take a full week to do that, and then have another meeting to reflect together. This would lead to a final rewriting. Alternatively, if you prefer, we can also continue with the original plan and submit ahead of the deadline.
1 Like
I think that on the day you fed Tulip the data from the system there were 12 or 13 fully coded interviews. There are currently around 17 interviews on the platform and probably those 33 topics or more in the W Polsce category.
Hmm. So there are two problems here:
We are going to need an exact number here. Also ping @Maniamana.
I just re-run the numbers, but no: the results are very similar. 2152 annotations, leading to 600 codes (in the paper: 613) connected by 16,370 edges (in the paper: 16,474). The maximum values of d and b are also the same. No way the number of coded interviews from then to now went up 50%.
No, I am not harvesting by category, but by tag. 33 topics are tagged ethno-icqe2022, regardless of category. If some topics outside the corpus were assigned that tag, would the ethnographers please un-tag them, and I will re-run the numbers.
Please refrain from coding these 33 topics until we are done…
@Maniamana , @Wojt, I started working on the data export. This led me to take a closer look at the raw data, and now I am confused. Look at this topic:
https://edgeryders.eu/t/poprebel-polska-interviews/15518
Does it not duplicate some data that are already somewhere else? I grabbed a random piece of text, run a search on Edgeryders, and found that, indeed, that random piece of text also appeared in a different topic: see here.
To make matters worse, it looks like the same interview was coded twice, in very different ways. Compare:
There are two problems here. The first, obvious, is that we have double counting. The second is that it surprises me to see just how differently the same material has been coded in the two versions.
To solve the first issue, I am afraid, we need to eliminate the duplicates and re-do the analysis work.
The second issue is potentially even more serious, because coding needs to be reasonably reliable across the team. If it is not, our analysis is based on constantly shifting ground.
My hunch is that three topics duplicate transcriptions stored elsewhere, and need to be eliminated from the data:
- https://edgeryders.eu/t/poprebel-polska-interviews/15518
- https://edgeryders.eu/t/poprebel-polska-interviews-2/16778
- https://edgeryders.eu/t/poprebel-polska-interviews-3/16779
Could you guys jump shortly back on the ethnographer’s call to help me out here?
Hi Alberto, I did take part in coding on the platform, but I reckon maybe it’s a case of test coding? I think it could also be coding based on the old codebook.
Transcriptions are not stored anywhere else outside of the the Polska Interviews sections.
Additionally each interview has three topics assigned to it, not sure whether it is a relevant information, bc I have very little idea on what’s happening other than what I mention above 
https://edgeryders.eu/t/poprebel-polska-interviews/15518/16 that’s the old tread when the idea was to put interviews together in one tread, and having each interview as a single post, but we changed that - I guess the solutions is to remove the ICQE tag from the data set, I guess @wojt marked it by mistake. Also this bunch was certainly coded before the final-ish version of the codebook was developed.
1 Like