@nadia, we need a new logo for the next generation of Graphryder. Do you want to design one?  Or work with someone to do it?
Or work with someone to do it?
sure. Round or square or other?
Preferably a vector graphic on a transparent background that is simple enough to be recognizable even when it’s only 50x50 px but still looks good at 300x300 px.
I’m thinking that we want three variants:
- Text only
- Logo only
- Logo + text
Sort of like the Blivande logos have three variants.
Text only
![]()
Logo only

Logo + text

ok when do you need it by?
1 Like
No rush. A month?
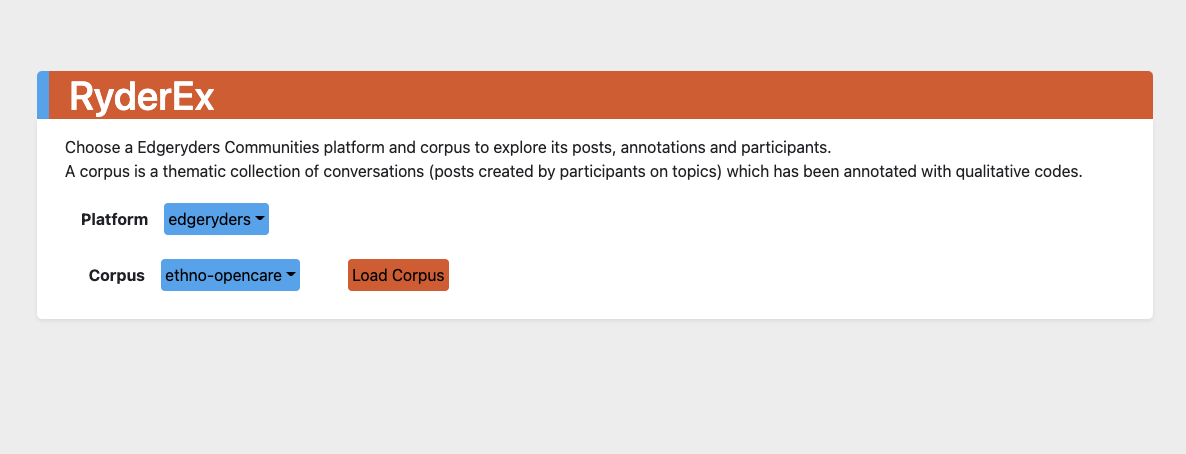

We are still ironing out some bugs, but the first experimental version of RyderEx is just about ready to test. This is how far we have been able to get on the current budget. Explaining what RyderEx does is easier if I show it, so I have recorded a series of videos of me running through a demo.
Search, scoping, and participant interaction graph
… And one more thing (state saved in URL)
Play with the OpenCare graph here (loading it for the first time can be quite slow, we are working on that)
Things RyderEx does not do yet:
- Ego network views
- Edge click to explore content related to specific co-occurrence edge
- Hide all nodes that are not contributing to scope in a given graph
Planned improvements:
- Language improvements (mistranslations, grammar, etc)
- More beautiful UI
- More intuitive labels control
Known bugs:
- Links to platform content and user profiles missing
Things RyderEx will probably never do:
- Curved edges. We have gotten used to the nice curved edges of Graphryder, but it turns out that those are very inefficient to draw when calculating a graph on the fly, so the new version of Sigma does not support them.
2 Likes
Wooow!!! Can’t wait to sink my teeth into it. Thanks, great work!
I am in Italy: not much time and so-so Internet at my mother’s place. Might have to wait until next week, but I’m really happy. 
1 Like
So, I re-watched all the videos, and played around a bit with the demo installation. Solid work, really. I especially like the search function (finally!) and the possibility to add entities to the scope via lists. Also that feature that allows to save the state in the URL, though we will need good documentation to explain what defines “the state”.
We do not necessarily need that in the same form. If you can make an interactor which selects the neighbors of a given node (your “poor man’s ego network”), then those could be put into a scope, and sorting the codes list by scope would put the ego network on the top.
Yes, this would be nice.
1 Like
Hi @hugi, now battle testing the software.
Question here:
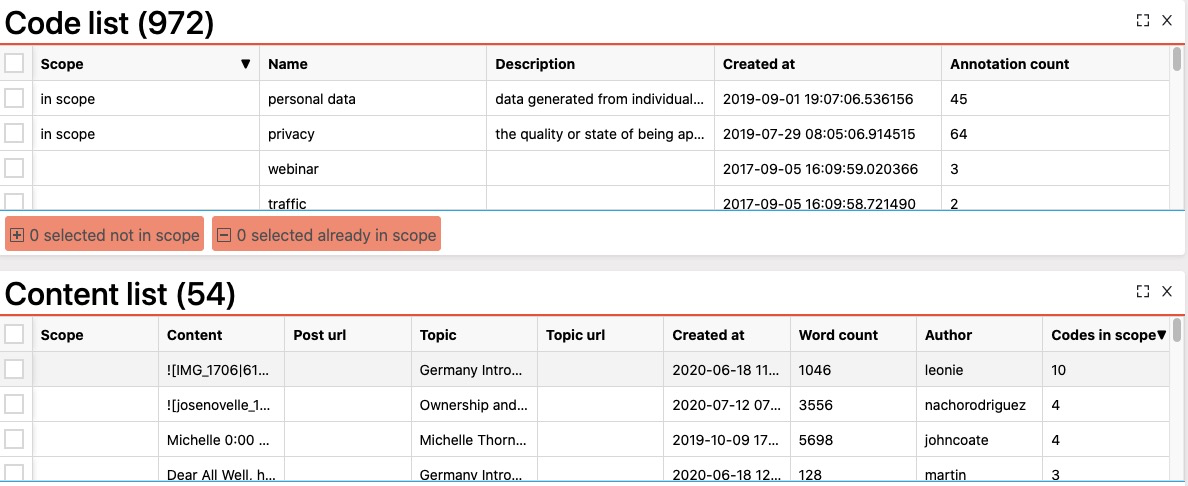
Towards the end of the video, you select a subset of codes and bring up the content (a list of posts) that contain those codes. Is the list:
- … the (set theory operator) union of all the posts that contain the codes, i.e. each post was coded with at least one of the codes in the scope?
- … the (set theory operator) intersection of all the posts that contain the codes, i.e. each posts was coded with all of the codes in the scope?
Based on the numbers, it must be union. I would like to make a case to either make it intersection, or support both union and intersection.
If Ryderex supported the intersection operator, we would have a workaround for the lack of the ability to click on an edge and see the content that generated this edge. Just:
- select the two codes connected by the edge you are interested in.
- put them in the scope
- bring up the content list. Done!

- if you want to go to the raw data (the text), click on the URLs (not yet supported as I am testing).
OK, I discovered a workaround: bring up the content list, then order by “codes in scope”.
But here there seems to be a bug, because I have only two codes in my scope, but some posts have more than two codes in scope. Is this double counting? My state URL is here.
1 Like
And one more thing. How does it update? Right now data explorer finds 5,894 annotations in the NGI corpus, while RyderEx sees 4,111.
1 Like
And yet one more. It seems to me that RyderEx counts multiple occurrences of the same code in the same post only once. This is not necessarily a mistake, but we have had a methodological discussion on that with the POPREBEL ethnographers and agreed to count one occurrence of a code in a post each time that code appears in that post. With long posts and an aggressive coding style (like the one in POPREBEL) this drives the number of co-occurrences way up, because it scales with the square of the number of times the code appears in that post: 3 occurrences of code1 plus 3 occurrences of code2 in the same post mean 3 x 3 = 9 co-occurrences of code1 and code2 just in that post. In POPREBEL, RyderEx reads a maximum of 16 co-occurrences in the codes co-occurrence network (and I have my doubt on that number as well, but it looks to be computed as “one and only one co-occurrence edge per post, no matter how many times the two codes occur in the post”). In my Tulip graph, the maximum number is 371.
Yes, indeed. Switching to intersection is easy, but allowing for both is a lot harder. I can switch it over to intersection, I just need to map out where in the code this is controlled.
Noted, I will fix this too.
I will look into this.
I realize I miscommunicated a bit at the retreat - the demo version doesn’t update, because it’s not running on the live Discourse database, but on a static backup. But it is built to update every night once it’s installed in the right place. We need to install it on the main Edgeryders server for it to update, and I am preparing instructions for how to do this and will consult with @matthias.
Indeed, and up to now I wasn’t aware that this had changed - that’s how the old GR worked.
This is indeed the case.
This is a bit of an issue. Here’s why:
In other projects, ethnographers may have worked under the assumption that if an annotation is used once in a post, using it again has no consequence for the topography of the SSNA graph. Because of this assumption, they may very well have been inconsistent in their annotation methodology - sometimes using the same code many times in the same post, while at other times only using each code once per post even when a concept appears multiple times. Personally, when coding BBU, I was not consistent in my methodology in this regard.
Is the Field Methods paper explicit about how multiple co-occurrences within a single post should be counted?
If it will vary between corpora how to count codes in single posts, it is possible to introduce a config setting which toggles this explicitly for some set of corpora tags, but it introduces some additional complexity. I would have to look into the code more closely.
This complicates things from a UX perspective, at least for the slider - it becomes very hard to use with 300+ ticks. No big deal though, we can always use the input box instead.
No, it is a new problem that manifested itself once a very dedicated group of a half dozen ethnographers went to work on a corpus like God intended, which is happening now in POPREBEL. This will be in the next paper (in preparation, to be submitted to Ethnography), and of course in our neglected White Paper.
Coding styles will vary, though we can and will make the consequences of adopting different styles explicit. The right place to do that is the White Paper.
The paper in preparation emphasizes two ways to count co-occurrences:
b, at least in the POPREBEL corpus, is so strongly correlated with the unique number of posts that it is not worth it to keep track of both measures. I will compute the same measures for OpenCare and NGI, and get back to you.
Bottom line is, if we do support two measures of link strength rather than one, d and b are probably the ones to go by.
1 Like
@hugi, I checked: intuition confirmed. This is OpenCare, with 0.94 correlation:
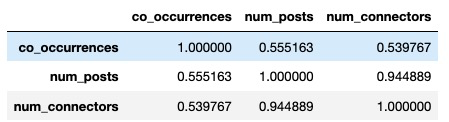
And this is NGI, which is more 0.96.

So, yes, d and b are the important measures.
1 Like
RyderEx is down right now while I am fixing some stuff, aim to have it back online tomorrow.
1 Like
I have now updated RyderEx to only use the intersection operator.
I fixed this, see the same state on our own deployment.
We still need to dig down into this, there might still be some differences.
Good to know for the future, let’s look at possible implementing this down the line.
1 Like
This is now fixed, more or less. RyderEx now sees 5,867 annotations in the NGI corpus Still a very slight difference, but I think it might have to do with RyderEx not counting two instances of the same code as two annotations.
I have made a few other fixes:
- Node diameter has been reduced to make graphs more legible
- Number of columns in tables has been reduced by making titles of topics and usernames into links
- Annotation list now includes the code of each annotation, and an indicator of it the code of the annotation is in the scope
- Annotation quote now links directly to source post on platform