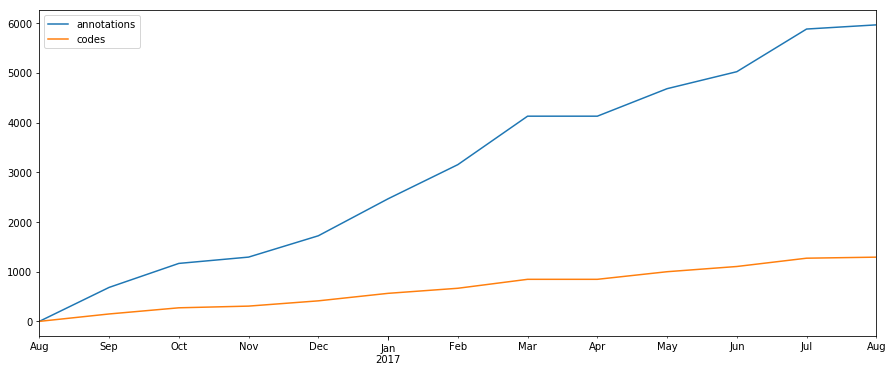
I have this hunch that conversations “converge”: the number of codes needed to describe a growing conversation tend to stabilise over time. The number of extra codes needed to code an extra contribution tends to zero.
I plotted the time series of annotations and codes in opencare:
@amelia, does this make sense with your experience?
The strange thing is that it seems there are no annotations after the end of August 2017. Is this even possible?
Makes sense to me! At the beginning there are a proliferation of codes (no
pre-existing ones). A first pass should be broad. As coding continues,
especially in a conversation like Open Care which is at least somewhat
topically focused, reuse of a selection of those codes happens. It reflects
both the tendency of conversations to converge topically (showing the
community’s engaged/extended interest in specific issues), and the fact
that over time more codes will have been generated so less new ones will be
necessary. Also, since I’ve been cleaning codes, on a second pass many
codes that mean the same thing will be merged into one.
It is not possible that the last annotations would be in August— hours of
coding have occurred since then…
@alberto what you are talking about is essentially a non-loseless compression. “Coding” would be the “dictionary” that is generated by the compression, so with reference to the literature produced on the topic by Lempel and Ziv, you can expect that:
you can estimate the complexity of conversations from the size of the dictionaries that are generated by the same operator when coding them both
you can decide on their noisiness, chaotic turbulence, or stability, based on how quick the convergence of each own’s dictionary size to a finite limit happens (in the case of pure noise, the limit would be infinite for a machine, and zero in the eyes of a human operator)
certain algebraic operators can be used to estimates the proximity of different conversations.
Please note that since ethnographic coding is non-loseless, the afore mentioned is true in approximation, but should not be possible to firmly demonstrate any of it (unless I am missing something).
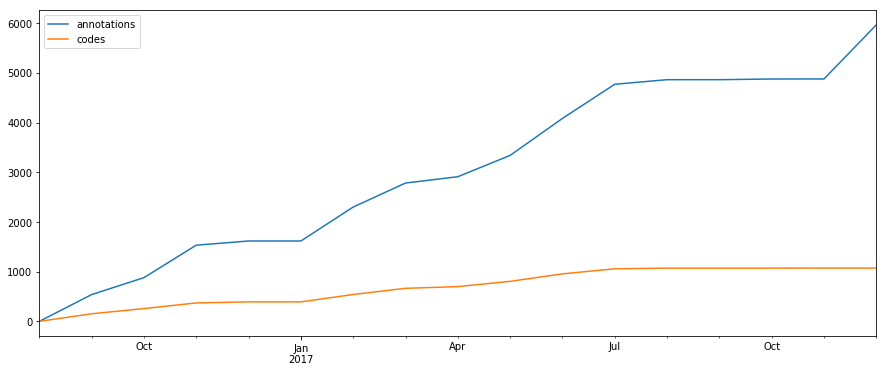
@amelia you are of course right… stupid mistake in a function. The real image has an even more marked trend toward flattening. The final five months of coding yielded 1,100+ annotations with only 2 extra codes.
@markomanka great assist! That is great thinking, as always.
I am pasting my text on the overleaf draft. I have also added the relevant bibliography, already formatted, to the .bib.
What I am not doing is amending the author list, for I don’t know where would you see me in that list (I noticed you are not using alphabetical order, so I would leave the choice to you).
Concerning the graph, I am a bit confused about the orange line though… could you share with me the equation you use to compute it?
In the article, the orange line is the number of average never-used-before codes paired with annotations (5-months rolling averages). Each annotation uses exactly one code. But some annotations re-use codes that already appeared in other annotations, whereas others use completely new ones.
The orange line is telling you that Amelia, as she coded the corpus, kept finding novelty: on average, she introduced one new ethno code every five annotations she made. The blue line is telling you that the contributions generated, on average, many more new codes initially, as the conversation explored the “opencare space”. As it moved towards the end of the project, the number of contributions per month (not shown in the graph) stayed quite high, but the number of new codes needed to describe them dwindled to almost zero.
OK, this is in line with my reflections concerning the convergence to a finite set of codes (which I claim, in a living system, should not happen)… I will add a reference to this line in the graph, now that I have understood it. Thank you for the explanation
Done… I hope you don’t mind I took completely over the subsection 4.1, which now extends from the last lines on page 5 to the first few on page 8. In facts, I have concentrated everything in this subsection, even some considerations that I recognise could go under the subsection 5.2. This has been an explicit choice, to maintain the reflection contained, without requesting the reader to move forth and back.
The text is nevertheless structured in such a way that I could easily copy-paste the relevant parts elsewhere, should you let me know that you prefer so.
I also finally added my name, just so that we do not forget (I would, most likely… it happened before, and nobody was happy sending an amendment to the editor later). I “claimed” the 3rd position, so I hope it will not disturb anyone (in medicine the meaningful positions tend to be 1st, 2nd, and last)… Anyone, change order to your heart’s desire, I don’t need this for my career, I am just glad to have my name where I contribute