Graphryder import script exports data from a Discourse & OpenEthnographer postgresql database and builds a Neo4j graph database from that data.
Graphryder Neo4j database is the data layer of Graphryder.
Graphryder GraphQL API and dashboard are deployed together in a Docker container and are how the end user interacts with the network graphs.
It looks like the first part is the one that is glitching. I imagine this is yet another consequence of the major update that Matthias and Daniel did to Discourse a while back, which entailed moving the platform to a new and more modern server.
The documentation is here and the Github repo is here. Somebody that understands the update made to the Discourse installation should be able to alter the code so that it works again. It could also be something super simple, like the cron job that automatically imports the script got stuck: for people who know how to use the command line, section 2.6 of the documentation explain where to find that script.
The bad news is this: my Python scripts also no longer work. They hit into a problem I have not seen before, that seems pretty low level:
>>> responses = requests.Session()
>>> responses.headers.update({"Api-Key": API_key})
>>> call = 'https://edgeryders.eu/annotator/projects/55/codes.json'
>>> response = responses.get(call).json()
Traceback (most recent call last):
File "/Users/albertocottica/Library/Python/3.9/lib/python/site-packages/urllib3/connectionpool.py", line 688, in urlopen
conn = self._get_conn(timeout=pool_timeout)
File "/Users/albertocottica/Library/Python/3.9/lib/python/site-packages/urllib3/connectionpool.py", line 280, in _get_conn
return conn or self._new_conn()
File "/Users/albertocottica/Library/Python/3.9/lib/python/site-packages/urllib3/connectionpool.py", line 979, in _new_conn
raise SSLError(
urllib3.exceptions.SSLError: Can't connect to HTTPS URL because the SSL module is not available.
SSL is a (legacy) encryption-based Internet protocol (see). I will ask for help to @bpinaud, again! Bruno, can you help me here? I’ll be in touch separately.
The good news is that the APIs work when queried via browser. If you are Open-Ethnographer enabled, you can put a query in the browser’s bar and get a JSON. For example, this works for me:
@daniel, could you please look into the server and try restarting the cron job that imports data into GraphRyder’s database? The instructions are in section 2.6 of this manual.
Maybe Bruno can get me unstuck on the Python script. This won’t restart Graphryder, but it will allow to build Tulip graphs from Edgeryders’s APIs.
Thank you @alberto ! Do either you or @pykoe have a sense of how long this will take to fix or get a workaround? We obviously did not calculate for this development in figuring out our timeline to completion.
hello Alberto, I used the same Python code to retrieve codes for project 55 (treasure) and encountered no problem ( from z_discourse_API_functions.py def fetch_codes_from_project(projectID): ). I’m using python 3.11
Hey @pykoe! I wrote the import script that @alberto is referring to above. I’m not very active anymore, but I do try to check my notifications once in a while out of old habit.
I just signed into the Edgeryders server and triggered the import script manually. Even though the script ran without errors, the issue remains. When I run the script it clears the Neo4j database and reloads the data from Discourse and Open Ethnographer directly from the database with SQL queries - see an example here of how topics are loaded.
I suspect @alberto is right and that something changed on Discourse, since the last annotations I see are from just before Discourse was updated. Strangely, the upgrade has not broken the import script, but it doesn’t import anything that was created after the upgrade. Whatever has changed seems to only affect content that was created after the update indicating that the the database still has the legacy data structure available for older content.
Unfortunately I have my hands full at the moment, so I have little time to help out with this, apart from making myself available to answer questions about the script. How comfortable are you with making PRs to the import script @pykoe?
Pretty sure Alberto is right here. I already have a suspicion what went wrong. Should be pretty straight-forward but requires server admin rights, so I will fix it myself.
Don’t worry @hugi, I’ll care for this one. Thanks for testing the import script manually already, it helps to know where to look for the fault. I think I just have to update the remote access connection to use the correct (= new server’s) PostgreSQL database …
ETA late this evening. Should be pretty straight-forward. Will tell here when done.
My version of Tulip (5.7.0) uses Python 3.9.16. @bpinaud this should work, no? Or do I need to bind Tulip to Python 3.11 (which I currently have no idea how to do)?
Sorry, you cannot update the python version bundled with Tulip. You are stuck with 3.9 with Tulip 5.7.0. It should be surprising that an upgrade of Python is needed unless you are using new stuff of Python 3.10 or 3.11.
Tulip 5.7.3 is bundled with a newer Python version (not sure if it is 3.10 or 3.11). You will have to install this distribution somewhere and redo the trick with pip --user to be able to install pyhon libraries.
Ok, I will first test using plain Python 3.9 (from IDLE, outside of Tulip). If it works, we know it is not “new Python stuff”, and something went wrong with my Tulip
The original issue that prevented Graphryder from updating is fixed now. It loads its data from the new, current Edgeryders server (at Infomaniak) now.
The bad news: creating graphs from this data works for all projects except Treasure, for which it will show “0 codes, 0 annotations, 0 topics” (see). Haven’t seen this issue before. And there were no error messages during the Graphryder import script run. So I will have to debug this today … any hints to possible causes or quick checks where things are failing would be appreciated (@hugi …) since I am not really accustomed to this software …
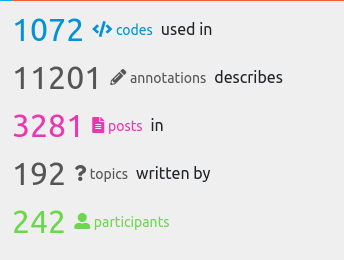
Good news finally: Graphryder is up to date again, and can be used to explore the ethnography of the TREASURE project. Current stats for this project in Graphryder are now what @pykoe expects:
The issue was, at least in part, due to weird caching done inside Graphryder. It was showing its graphs even after I deleted all content of the Neo4J database, and even after I stopped the Neo4J service altogether. All while Graphryder’s config.json had “reload_from_database”: true`.
At the moment, Treasure is the only project I have loaded into Graphryder. It should update its data overnight from Discourse, but due to the caching issue I cannot guarantee that right now. If it does not work and you need renewed data, let me know and I will update it.
Also, I will work to bring back the other projects into Graphryder, but only at night from 0:00. So at that time, there might be some downtimes or malfunction of Graphryder, but at all other times, it should work for your purposes.