I am knee deep into the research work for opencare. I think I am learning new things on how to use collective intelligence in practice. This has far-reaching implications for my own work in Edgeryders, and beyond. Far beyond, in fact. If we crack collective intelligence, we gain access to a new source of cognition. Forget my own work; this has profound implications for the future of our species. If you think that’s radical, go read the work of cultural evolution scholars, like Boyd, Richerson or Henrich. They think homo sapiens has started a major transition: evolutionary forces are pulling us towards a larger, more integrated “collective brain”. We are en route to becoming to primates what ants are to flies.
Collective intelligence is an elusive concept. It appeals to intuition, but it is hard to define and harder to measure and model. And yet, model it we must if we are to go forward. The good news is: I think I see a possible way. What follows is just a back-of-the-envelope note, plotting a rough course for the next three years or so.
1. Data model: semantic social networks
I submit that the raw data of collective intelligence are in the form of semantic social networks. By this term I mean a way to represent human conversation. The representation is a social network, because it involves humans connected to each other by interactions. And it is semantic, because those interactions encode meaning.
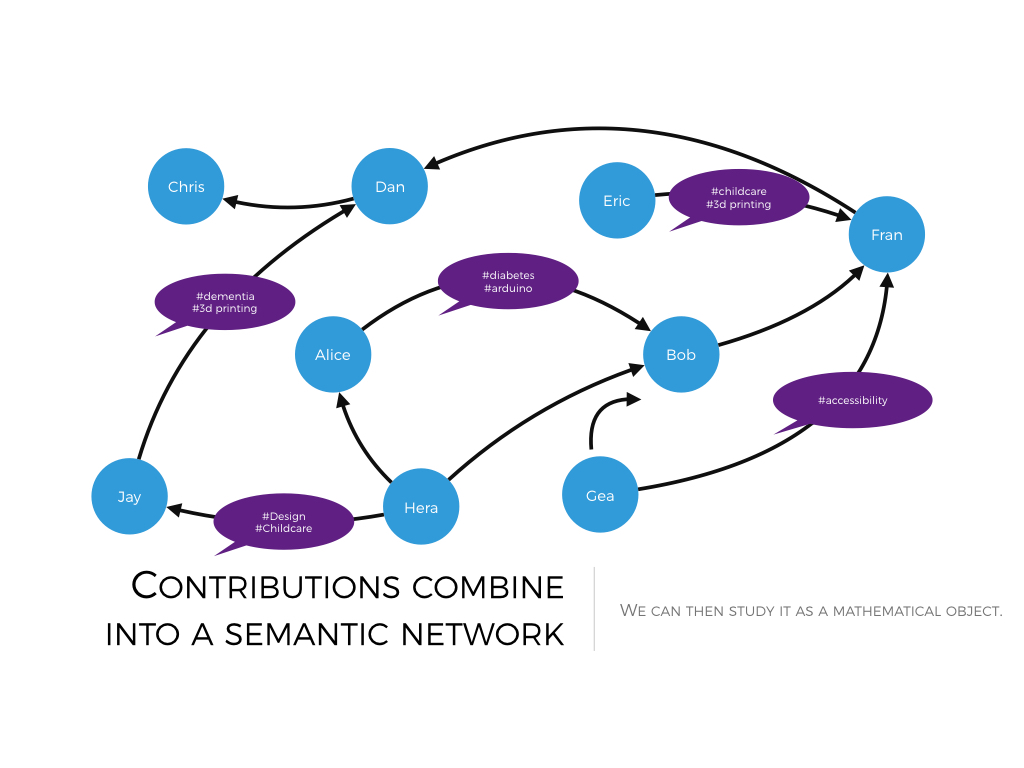
2. Network science: it's all in the links.
Collective intelligence is not additive: it’s interactional. We can only generate new insight when the information in my head comes into contact with the information in yours. So, what makes a collectivity more or less smart is the pattern of linking across its members. Network science is what allows a rigorous study of that linking, looking for the patterns of interaction which associate to the smartest behaviors.
3. Ethnography: harvesting smart outcomes
Suppose we accept that the hive mind can generate powerful insights and breakthroughs. How can we, individual human beings, lift them from the surrounding noise? Looking at what individual members of the community say and do would likely be fruitless. The problem is understanding how the group represents to itself the issue at hand; no individual you ask will be able to hold all the complexity in her head. We do have a discipline that specializes in this task: ethnography. Ethnographers are good at representing a collective point of view on something. Their skills are useful to understand just what the collective intelligence is saying.
4. "Shallow" text analytics: casting your net wider
Ethnography is like a surgical knife: super sharp and precise. But sometimes you what you need is a machete. As I write this, the opencare conversation consists of over 300,000 words, authored by 137 people. This is a very big study by ethnography standards, and these numbers are likely to double again. We are already pushing the envelope of what ethnographers can process.
So, the next step is giving them prosthetics. The natural tool is text analytics, a branch of data analysis centered on text-as-data. It comes in two flavors: shallow-and-robust and deep-and-ad-hoc. I like the shallow flavor best: it is intuitive and relatively easy to make into standard tools. When the time of your ethnographers is scarce and the raw data is abundant, you can use text analysis to find and discard contributions that are likely to be irrelevant or off topic.
5. Machine learning: weak AI for more cost-effective analysis
Beyond the simplest levels, text analytics uses a lot of machine learning techniques. It comes with the territory: human speech does not come easy to machines. At best, computers can evolve algorithms that mimic classification decisions made by skilled humans. A close cooperation between humans and machines just makes sense.
6. Agent-based modelling: understanding emergence by simulation
We do not yet have a strong intuition for how interacting individuals give rise to emergent collective intelligence. Agent-based models can help us build that intuition, as they have done in the past for other emergent phenomena. For example, Craig Reynolds’s Boids model explains flocking behaviour very well.
The above defines the “long game” research agenda for Edgeryders. And it’s already under way.
- I am knee-deep in network science since 2009. We run real-time social network analysis on Edgeryders with Edgesense. We have developed an event format called Masters of Networks to spread the culture beyond the usual network nerds like myself. All good.
- We collaborate with ethnographers since 2012. We have developed OpenEthnographer, our own tool to do in-database ethno coding I'd love to have a blanket agreement with an anthropology department: there is potential for groundbreaking methodological innovation in the discipline.
- We are working with the University of Bordeaux to build a dashboard for semantic social network analysis.
- I still need to learn a lot. I am studying agent-based modelling right now. Text analytics and machine learning are next, probably starting towards the end of 2016.
With that said, it’s early days. We are several breakthroughs short of a real mastery of collective intelligence. And without a lot of hard, thankless wrangling with the data, we will have no breakthrough at all. So… better get down to it. It is a super-interesting journey, and I am delighted and honored to be along for the ride. I look forward to making whatever modest contribution I can.
Photo credit: jbdodane on flickr.com CC-BY-NC