THIS WIKI IS NOW INTEGRATED INTO the Open Ethnographer Manual. Please make any changes there, not here.

Big Picture
–
When we are coding, we need to think about the rigour of the coding system so that others can easily understand and use our codes and the data structure we are producing in the SSNA. This means:
- creating codes that carry meaning, are salient and are essence-capturing when viewed on their own
- defining everything in enough detail and documenting why you chose to use a specific code
- creating consistent and clear categories so that other ethnographers can easily navigate a large codebook
- thinking about how someone who has never read any of the underlying data would read and understand the code if they saw it
- thinking about what meaning the code will carry when it co-occurs with other codes in a visual network
Coding Conventions
–
Spelling and Formatting
Use British spelling for English-language codes.
Use lowercase letters (unless capitalised letter has semantic meaning, as in a proper noun).
Use accented letters as normal in all languages.
Avoid compound codes
Because the SSNA detects co-occurrences, it is important that each code carries one meaning, that can then be linked to others.
For example, code homosexuality and discrimination rather than homosexuality and discrimination or homosexuality:discrimination.
As @alberto aptly puts it:
Specificity vs Generality
If the code does not carry any real meaning on its own (e.g. approaches ), it is too general.
If the code is too granular to ever be reused (e.g. hyperactive mosquitos ) then it is likely too specific.
Sometimes this requires creative thinking. If you’re trying to capture the idea that informants are expressing that Romania is more awesome than Poland, the code Romania is more awesome than Poland is likely not going to co-occur in many places (though @noemi might disagree ![]() ) . However, we could use the code
) . However, we could use the code country comparison and co-code it with Romania and Poland (or Romania-Poland if we really felt strongly that we didn’t want to lose that specific country comparison as tied to the country comparison code, though see why we should hesitate to do this in the compound codes section above. We could always go back and copy the code Romania-Poland if we found it was too specific, assigning one instance of all the annotations to Romania and the other to Poland , so no harm done as long as we keep that more broadly useful country comparison there.)
How many codes to assign?
It is much easier to merge (and copy) codes than it is to fork them. As a result, aim for greater granularity and merge into a more general concept if you find upon review that the granularity is too small.
If we code everything discrimination and realise that we wish we’d coded homophobia and racism and sexism differently, we have to go back and re-read and recode all the annotations assigned to discrimination . If instead we code the other three and decide they are too granular, merging them all into the code discrimination is easy. If we decide homophobia is occurring on its own broadly enough but the other two are too granular, we can always merge racism and sexism into discrimination but leave homophobia alone. If we want all of the instances of homophobia to also be co-coded with the higher-level code discrimination , we can easily copy the code homophobia and merge that second instance into discrimination so that all its annotations are also coded with the code discrimination. This is what we use hierarchies for in the backend, to more easily keep track of such concepts, as I will return to in the next section.
Code 'that which goes without saying
Part of our job as interpretive analysts is to use our sociocultural understandings and our training to read between the lines. If community members are talking about two concepts explicitly (say remote working and e-learning ) if Covid-19 is the context from which this conversation emerges, and the community members are clearly assuming that shared context in their conversations without stating it explicitly, be sure to code it.
Culture is often termed ‘that which goes without saying’, and part of our job as ethnographers is to explicitly say it. This is especially important in the context of populism, where family values traditionalism and housing policy might be used to speak about something like homophobia in subtext.
Code only what has meaning
Back to ethnography as an interpretive method. One way not to overproliferate codes is to make sure that a code is only applied if the community member uses the concept meaningfully.
For example, if an event takes place in the United States, but the activities that happened at the event are not meaningfully connected to the fact that the event took place in the United States, in your interpretive assessment, do not apply that code. If, however, the fact that a certain activity happened in Prague (a major city) rather than a rural area, apply the code Prague . Use SSNA thinking here: a co-occurrence network around cities might differ substantially to one around a rural area (certain ideas might be more widely held and repeated in the capital city than in a rural town, for example), which we would want to capture in the SSNA. Code with intention and interpretively.
As another example, a community member might mention that they are 50 years old. You would only apply the code age if age was a meaningful frame used by the community member – if the story was about growing older and life changing, for example. But if the fact is incidental and they go on to talk about monster truck racing , do not apply the code age .
Three Tiered Invivo System
If a code is descriptive (your term for what informants are describing, or a word that is used in ordinary parlance to refer to the thing you are referring to), use unmarked text. Example: sustainability or mental health
If a code is invivo (a directly quoted word or phrase that your informants used that is unique, interesting, or salient as a concept, or does not necessarily fit the ‘normal’ use of that word) use double quotation marks. Example: "witch" , "the East", "punk"
If a code is in-between (a conceptual category used by informants that you are aggregating into a term yourself and/or that does not fit the dictionary or academic use of that term), use single quotes. Example: 'communism' or 'patriotism'
Reason:
Hierarchies
Hierarchies do not appear in the SSNA itself, but we use them to enhance our ethnographic practice. Here are some ground rules.
Every code in a hierarchy must make sense on its own. Discrimination could be the parent of homophobia or sexism , but creating a code like approaches and nesting it under discrimination is a no-go.
You can create null codes to organise codes in the backend, which will not affect the SSNA. For example, we created the code geographical location (with no annotations assigned to it, by using the “new code” function in the backend) to nest locations like Prague.
Wait to assign hierarchies / parent-child relations in the backend until we do this together in calls where we analyse the SSNA visualisation alongside this practice, since our hierarchical relationships affect each other. Instead, create categories in your own codebook. We will then discuss them and apply them in the backend together.
Use hierarchies to toggle specificity and generality.
Let’s return to an example we used above. If we want all of the instances of homophobia to also be co-coded with the higher-level code discrimination , we can easily copy the code homophobia and merge that second instance into discrimination so that all its annotations are also coded with the code discrimination. We might do this if we decide that discrimination as a code by itself would co-occur meaningfully with other codes in the SSNA.
However, we don’t want this to happen automatically, because excessively higher-level codes can end up dominating the graph too much, and may not carry enough meaning on their own to be represented (like geographical location, which is a useful organising category but not a very useful SSNA category). We use hierarchies in the backend for different purposes, and not all are worth representing in the SSNA.
Codebook Structure
The codebook should have three tabs.
Tab 1
A list of the codes, ordered linearly (in the order that you coded them) with definitions. It is important to have this linear order so that when other ethnographers come to do code review, they can pick up where they left off and easily see new codes.
A minimum viable codebook entry includes:
- Column 1: Code name in source language
- Column 2: Code name in English
- Column 3: Definition of the code
Additional information can be added:
- Column 4: Links to related codes (in own codebook or in other ethnographers’ codebooks, to suggest merging in future)
- Using google sheets comment function: Memos about the code (questions for other ethnographers, notes to self)
Tab 2
Same as the above, but organised alphabetically for clarity.
Tab 3
A list of categories and/or hierarchies that organises the codebook. Important for 2 reasons:
- So that other ethnographers can easily find similar codes in your codebook to ones in theirs, to suggest merging or to use your code to apply to their dataset.
- So that when we come together to create hierarchies in the backend every month, the task is more streamlined.
Document Everything
Define your codes immediately.
Define every code. I mean everything. Even if it seems self-evident. See above on saying “what goes without saying”. This applies to our own frames as well – what seems self-evident to one of us will not be self-evident to another one of us.
Assign both English and source language translations in the backend, so the codes are connected.
If you’re not sure about a term or code, note it down and explain why so that others can help you hone it / you can return and refine it
Create categories in your own codebook as often as possible to help you structure and streamline your codes. I recommend creating these as you code, or at least frequently, to avoid having to do this in a big batch. Doing so makes you less likely to assign different codes to the same concept and have to merge later, since you can see your existing codes more clearly.
Interacting with Other Ethnographers’ Codebooks
Review other ethnographers’ codebooks at minimum monthly.
Check if:
- the code name accurately expresses the definition (is everything in the definition captured by the term used? Is there a more salient or accurate term for what the ethnographer is trying to express in the definition?)
- the code is too general to carry meaning on its own
- the code should be broken up into two separate codes
- the definition/concept is already expressed by another code used in the codebook
- the ethnographer has asked any questions that you can answer
- the hierarchies and categories they use in Tab 2 make sense
Leave comments attached to particular cells using the comment function on Google Sheets (right click or “add comment”), so that the ethnographer receives a notification when comments have been made
Note any related codes you have in the “related codes” tab and make a hyperlink to the cell in your own codebook where the related code is.
Merging codes. If you think your code means the same thing as someone else’s (or close enough that you should seek to align them), make a note of it in the related codes tab. Once you discuss the merge with the other ethnographer, merge the codes. Hyperlink the merged code in English to indicate that it is shared across codebooks (on Tab 1 Column 2). Remember to check with the other ethnographer if you want to change the code or its definition.
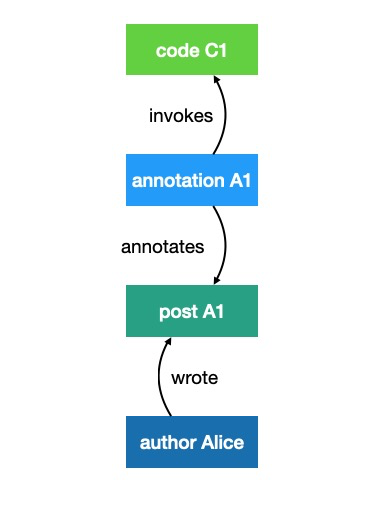
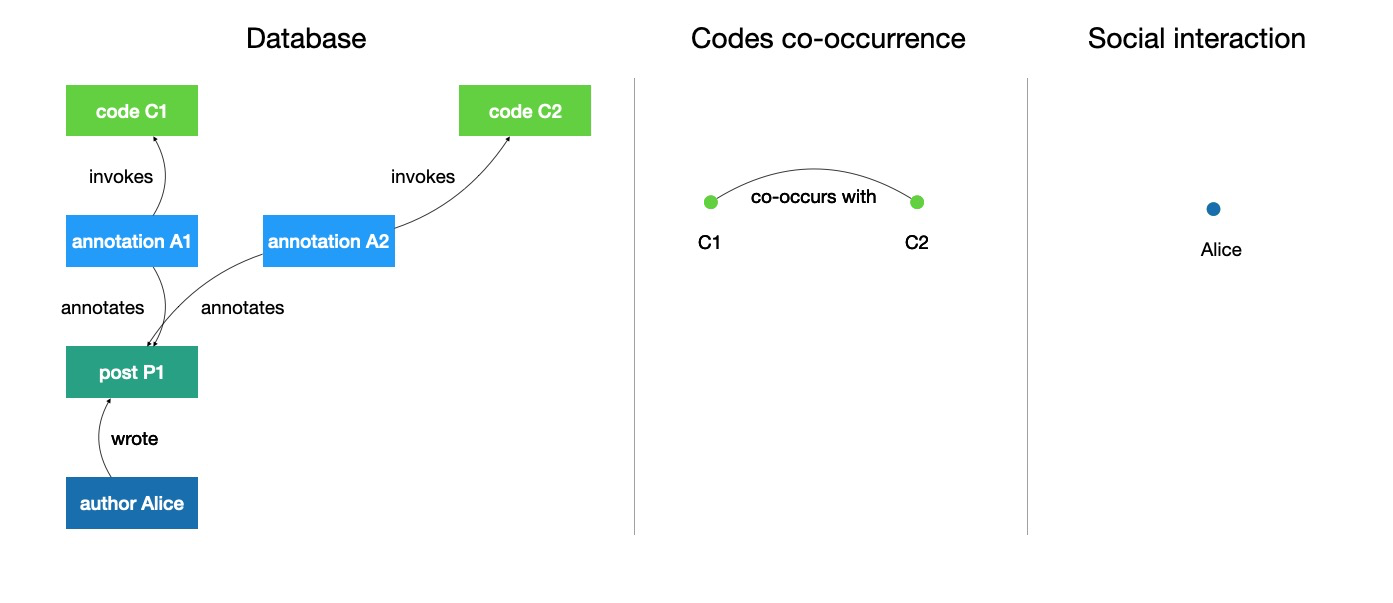
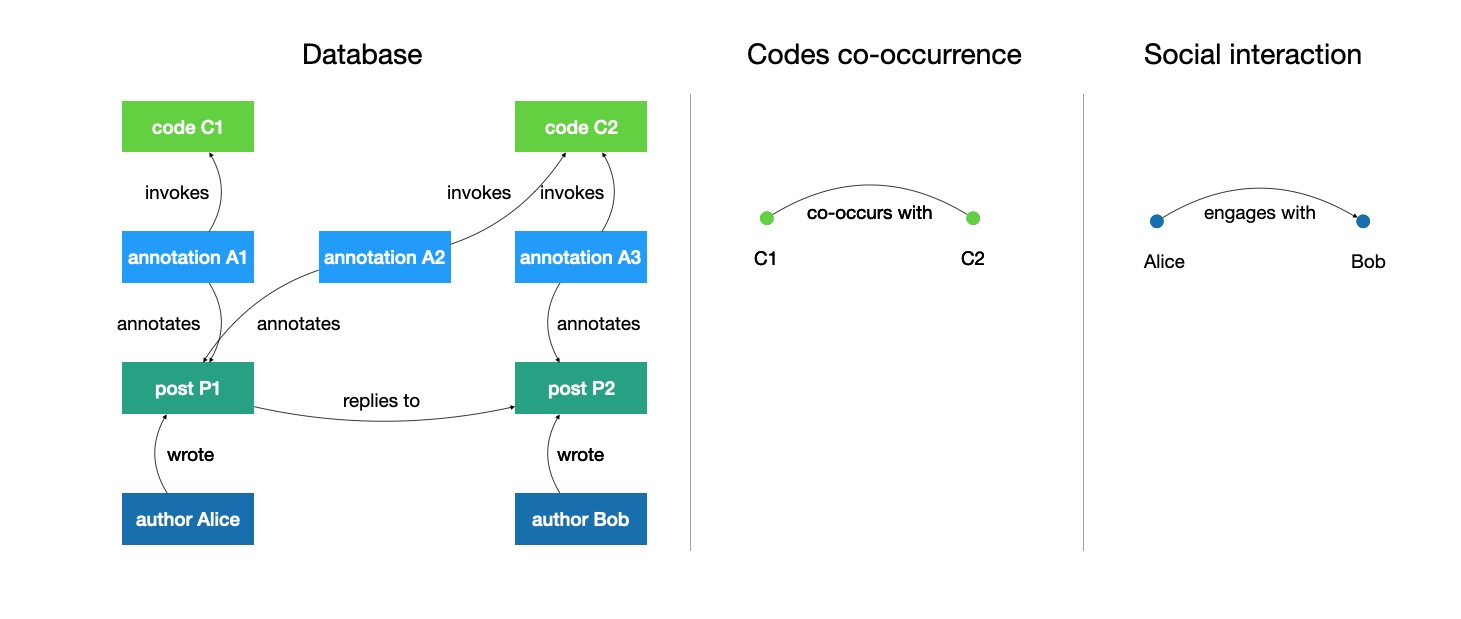


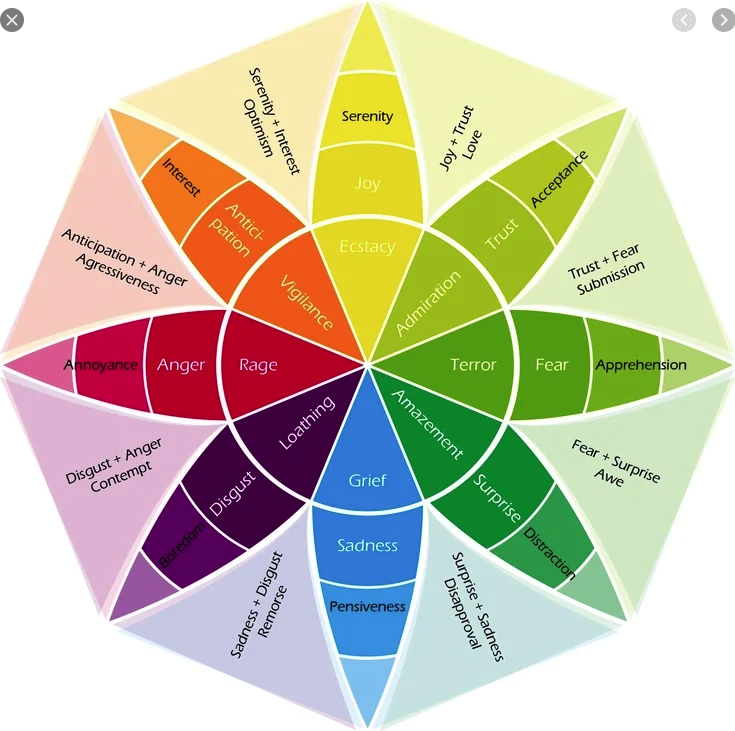
 You need the biological anthropology (and linguistic anthropology) to understand the sociocultural anthropology properly!
You need the biological anthropology (and linguistic anthropology) to understand the sociocultural anthropology properly!