I’ve now both watched your videos, done some research to further understand the underlying tech and done some thinking around this @leobard. Thank you for putting in the time and care to make these videos. There was quite a lot to unpack there for me, so I’ll go through it step by step.
Sharing data between systems is the way to go
Ok, you, @eb4890, @krav and others have convinced me, the “one graph database” idea is not a good one. It’s not necessary and will just make cause more trouble than it’s worth. Thanks for talking me out of it.
I’m also throughly convinced that we’re going to share data between the different systems. Now what?
A short summary of Leobards proposal
Since it’s a lot to unpack in the videos, I’m going to make a very concise summary so that people can follow the conversation without watching all of the material (you should though, it’s a great primer into linked data). So, @leobard, correct me if I’ve got something wrong or missed something important. Even better, just change it yourself, since this post is a wiki.
Points on RDF
-
Different systems solve different challenges, and to develop quickly and efficiently they should be built with whatever stack of technologies that fits the job and is familiar to the developers.
-
Rather than different systems sharing a database, they should make data available to each other through shared standards.
-
RDF is a tried, tested and open standard which Leobard recommends us to implement. In practice, this would mean that each application had an exporter which converted data from whatever database it uses to serialized RDF and makes it available at an endpoint.
-
One benefit of using RDF is that there are a lot of standard schemas available to use on Schema.org which makes it easier for other developers to plug their systems into ours.
-
Each resource (dream, person, event, membership, etc) is uniquely identified with URI, which in this case is a URL, for example http://dreams.theborderland.se/dreams/437 is the URI of that dream. We could then choose fitting resource type for a Dream from Schema.org, for example CreativeWork. We would use the schema properties when possible and our own custom properties when necessary.
-
By sending serialized RDF data between applications, we could for example create a new thread on Talk for each Dream created on Dreams and list all posts in that thread on Dreams, as long as both those systems implement RDF exporters and listen to the each others endpoints.
-
If Particip.io and it’s projects would join the RDF and Linked Data community we would find kindred spirits with a very similar ethic and ambition to ours, and make some very interesting friends and allies.
Points on authentication
-
Leobard recommends OpenID for single sign-on.
-
Tim Berners-Lees Solid implements both OpenID and RDF but is still in early stages.
Points on architecture
-
A graph database is usually not a great choice for your primary data storage, but is fantastic for indexing and getting an overview of how systems fit together.
-
A visualisation app built on a graph database could easily pull all the standardised exported RDF data from the different applications and keep an updated graph of how things fit together.
My take on it and how it fits with our current momentum
In general, I love this way of thinking, and I’m convinced by the arguments. Like I mentioned above, this has made me back away from the single database idea and made me realize it’s better to opt for sharing data between applications.
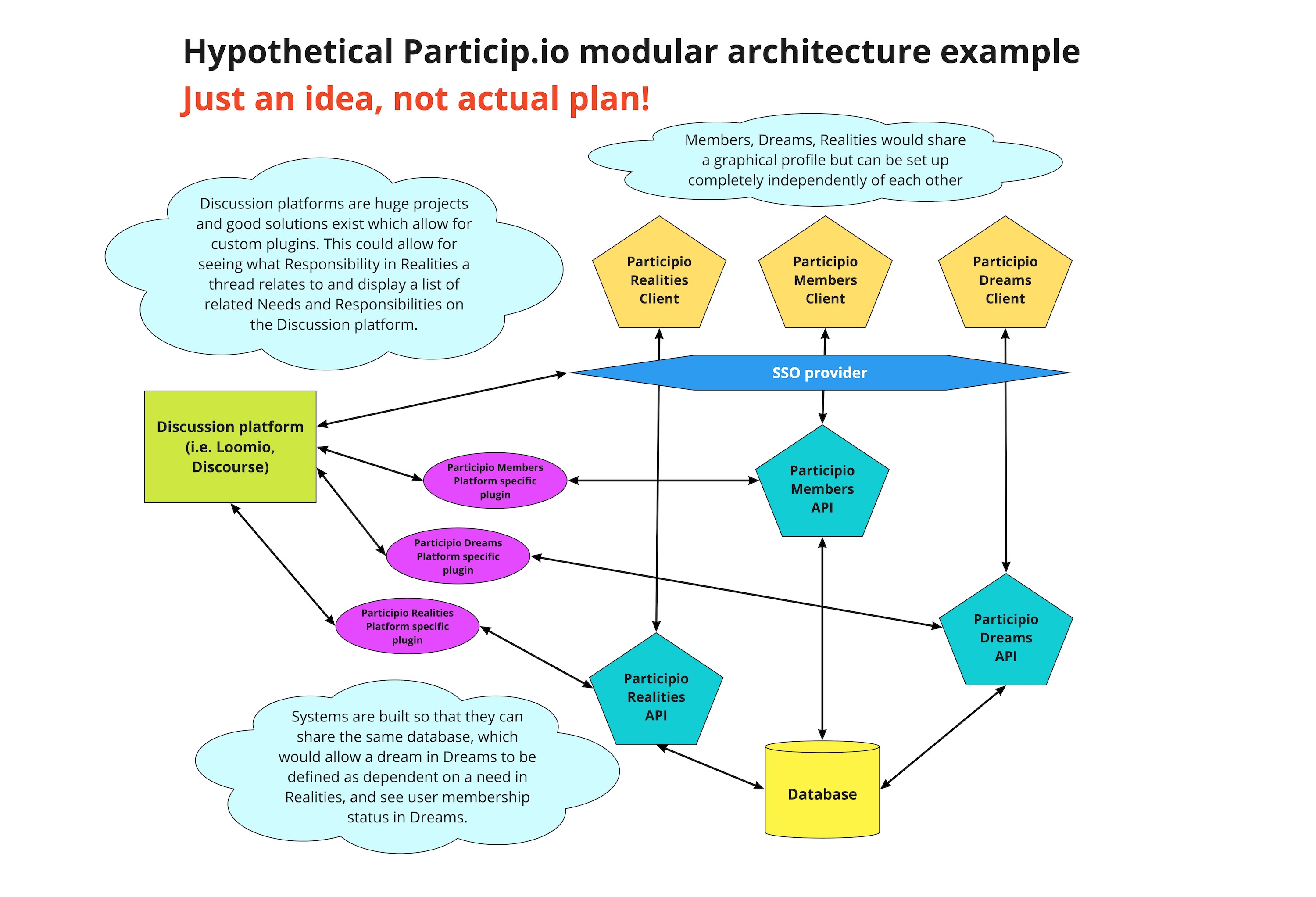
However, we also need to move with our current momentum. We currently have two applications within the Particip.io umbrella that we’ve invested time and money in.
Dreams
Dreams is now almost three years old, and has seen substantial development. It’s built on Ruby on Rails, and while it does not have any APIs currently, implementing an RDF exporter and have it listen to other endpoints would not be a lot of work if we’d decide on a good strategy.
Realities
Realities is a new system that will be at the core of how we make sense of the Borderland in 2019. We’re close to finalizing the first development cycle as @erikfrisk will deliver the first MVP in the coming weeks. It’s already deployed on a staging server for testing.
Realities is a javascript single page app built on Node, GraphQL, Apollo and React with Neo4j as a database. In this case, we’re indeed using a graph database as the primary data, but only because Realities is not really much else than an application to edit and view the graph that describes how the needs, responsibilities and roles in an organisation are structured and depend on each other.
React was chosen because it’s the front end framework with the biggest momentum today, and it’s also what most of the developers were familiar with. GraphQL was chosen because it’s become an increasingly popular replacement for REST APIs with React developers. GraphQL works well with graphs and it has seen some use with Neo4j as it’s database.
Neo4j was chosen mainly because it was the graph database with which I was most familiar at the time, and it’s a system that’s easy to prototype models in.
All of the technologies chosen are open source. Apollo, React and GraphQL fall under the MIT license and Neo4j falls under the GPL3 license.
GraphQL vs RDF?
In your video you described how Facebook and other walled gardens greatly decreased interest in RDF. Ironically, once Facebook grew as huge as it is, it needed to find good ways to share data within it’s walled garden and built GraphQL, which it has now released it’s patent for. Interestingly, some of the RDF terminology is used by GraphQL, which recieves JSON schema templates to request data and then returns data in the same format as the request itself. You can see these in action in the Realities code. I’m not sure if you’re familiar with GraphQL, but essentially Queries are only requesting data while Mutations are making changes.
Watching your videos made me realise that it would probably be pretty easy to implement a GraphQL endpoint in Dreams too. There is a highly maintained GraphQL library for Ruby on Rails which we could use to relatively easily interface Dreams and Realities! That’s a pretty interesting idea since @questioneer who is joining us for the development week in Medenine in November is a Rails developer with GraphQL experience.
As for having a graph database collect all relevant data, the Realities graph database could simply double as an index for all data from Talk, Dreams and other systems, and we could build views to show and filter that data as we keep developing Realities to also show Dreams connected to Needs and Responsibilities. As long as all new applications we build also implement GraphQL, this would be reasonably straight forward.
But what about RDF, Solid and the linked data community?
Damn it. Right. I really agree with you that it would be cool to plug into that world. How does RDF and GraphQL overlap? Is it two technologies solving a similar problem? Does one complement the other? Is there any sense in using RDF together with GraphQL? I don’t understand enough what an architecture using RDF looks like in practice compared to our Realities stack. Maybe based on the information and thinking above, you have some ideas @leobard?
This is a really interesting conversation, and I’m enjoying it. I’m going to tag @matthias because I have a little bit of a suspicion that we would also find this enjoyable. This is also relevant to some recent conversations I’ve had with @kristofer and also with @brooks.