Hi @hugi, now battle testing the software.
Question here:
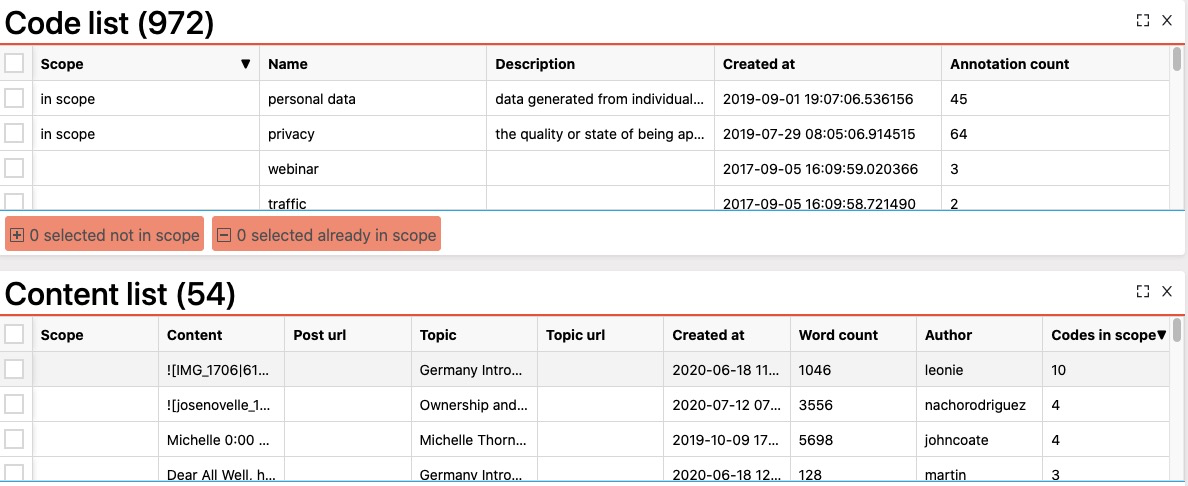
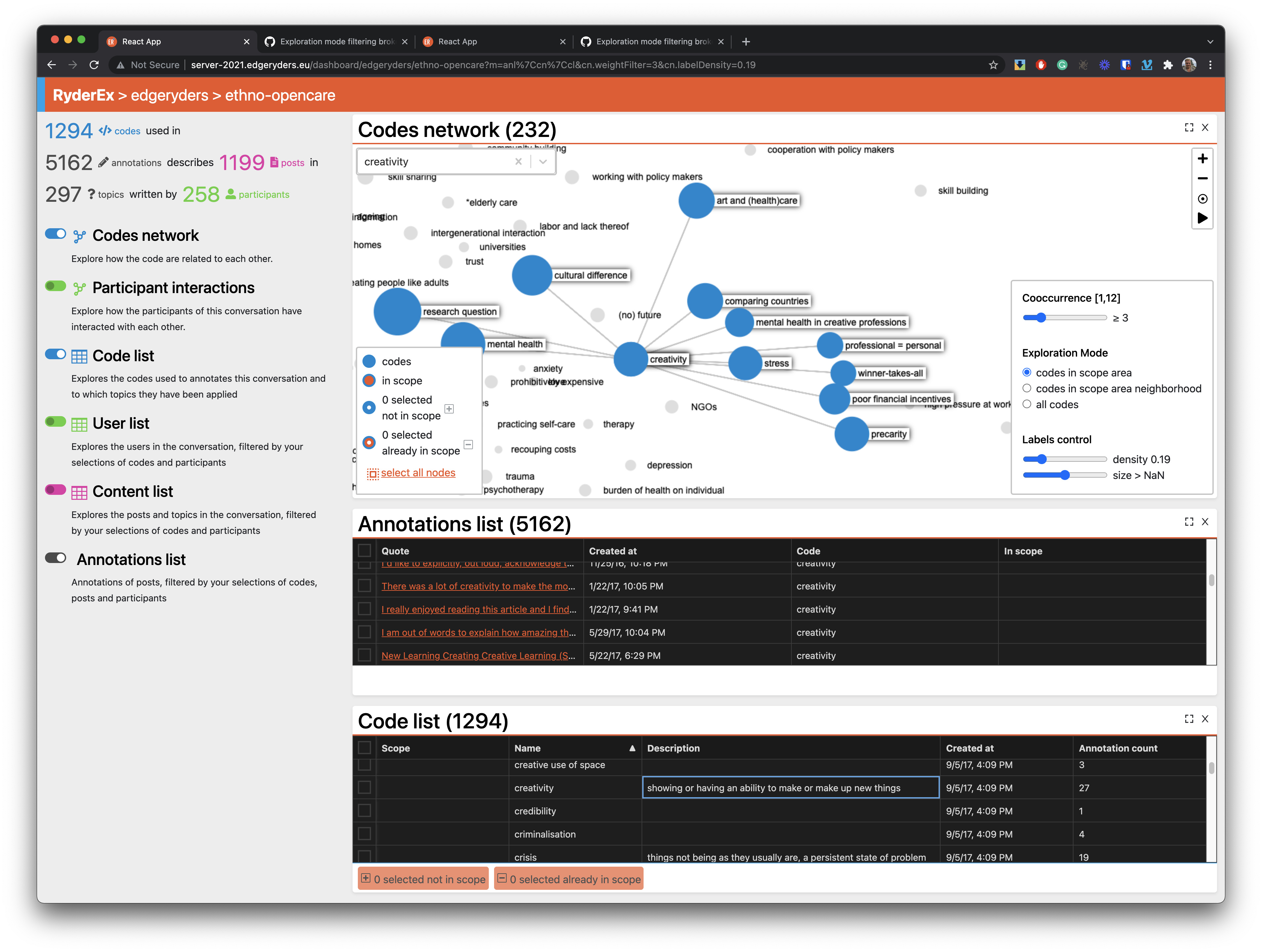
Towards the end of the video, you select a subset of codes and bring up the content (a list of posts) that contain those codes. Is the list:
- … the (set theory operator) union of all the posts that contain the codes, i.e. each post was coded with at least one of the codes in the scope?
- … the (set theory operator) intersection of all the posts that contain the codes, i.e. each posts was coded with all of the codes in the scope?
Based on the numbers, it must be union. I would like to make a case to either make it intersection, or support both union and intersection.
If Ryderex supported the intersection operator, we would have a workaround for the lack of the ability to click on an edge and see the content that generated this edge. Just:
- select the two codes connected by the edge you are interested in.
- put them in the scope
- bring up the content list. Done!

- if you want to go to the raw data (the text), click on the URLs (not yet supported as I am testing).