Hello @rebelethno, we have an interesting decision to make.
It can happen that a code is used multiple times to code the same post (in multiple annotations, of course). This is perfectly fine, of course, but it does mean we must make a choice when building the codes co-occurrence graph.
Imagine we have a post with four annotations. One uses the code catholic church, and the other three all use the same code, tradition. When building the graph, we can do two things.
The first one to is consider that there are, just in this post, three co-occurrence edges between catholic church and tradition. The logic is to count an edge for each pair of codes in the post, and it does not matter if they are the same code. Then, we discard the edges between tradition and tradition: the codes co-occurrences network has no self-loops, because it is tautological to say that a concept (as represented by a code) is associated with itself. This leaves us with three edges between catholic church and tradition.
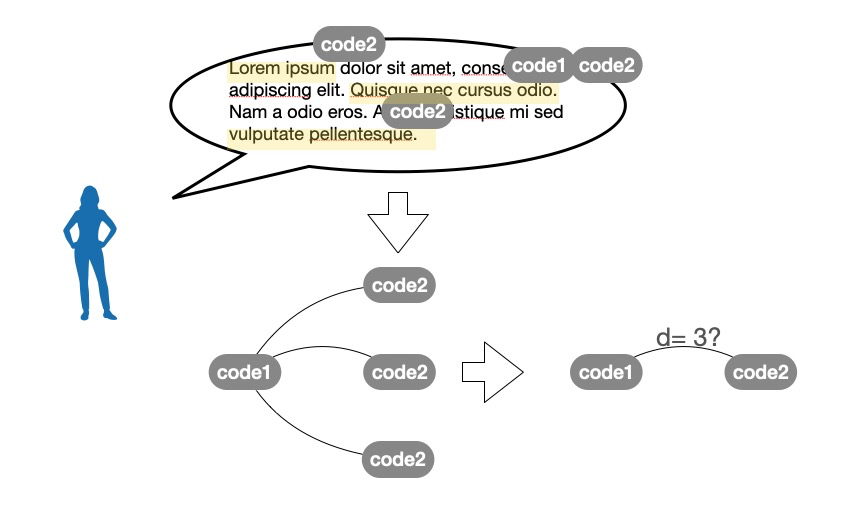
The second one is to consider that a post is a unit: the informant is expressing herself using a certain number of concepts, each encoded into a code. She may need to recall the same concept more than once as she writes (or speaks, if we are talking about a sub-unit of an interview), but that is just for the sake of the exposition. She does not mean to reiterate the importance of the repeated concept. In this case, the logic is to count an edge for each unique pair of codes used in the post. Our example post would have only one edge between catholic church and tradition .
Which one do you think is more appropriate?
This decision was made in today’s ethnographers’ meeting. We:
- interpret multiple occurrences of the same code in the same post as an intentional expression of the importance that code has for that informant in the context of the contribution. So, we indeed count all of its occurrences. In other words, we choose the first of my two solutions in the post above.
- keep in mind that multiple occurrences of the same codes in the same post give rise to a lot of co-occurrences, because the logic is multiplicative. If
catholic church occurs twice, and tradition three times, you get 2 x 3 = 6 co-occurrences of the two codes, just in that one post. Long posts with many multiple occurrences might end up being disproportionately influential in the network analysis. We need to be aware of the mathematical construction of our graphs.
- this problem is mitigated by keeping our units of content (posts, interview blocks) at more or less the same length.
Update on this. I wrote some code to compute the number of unique underlying contributions for each co-occurrence in the POPREBEL corpus (i.e. each edge in the co-occurrences graph. It turns out it is very highly correlated (~ 0.95) with the number of unique informants that have authored at least one contribution that was coded with both the codes in question:
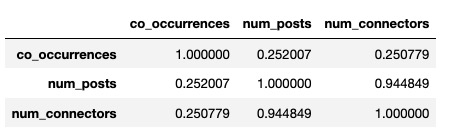
So, I do not think that it is worth it to keep track of both statistics. We do keep track of the “raw” number of co-occurrences (which we started to call association depth, denoted by d) and of the number of informants who have authored at least one contribution with each co-occurrence (which we started to call association breadth, denoted by b). These are positively but weakly correlated (~ 0.25), so they contain different information. They also are different in magnitude: at the time of writing, the maximum value for d in the POPREBEL corpus is 371, whereas the maximum value for b it is 13. The maximum value for unique number of contributions bearing that co-occurrence is 16, very close to b. However, high values are an exception: for both variables over 50% of the edges have value 1.