The mighty @melancon , @Jason_Vallet and I are at Hacking Health Bordeaux, working away with a fantastic team of generous hackers. Yesterday we re-exported the data, including @Amelia 's annotations (careful! only a very partial coding so far), and Guy built a rough visualization of the whole people-to-content-to-codes network:

Zooming in, you see:
Beautiful… but overwhelming.
So here is what happens.
- Jason is already quite advanced in building a navigation interface. The idea is this: you start from a graph representation, and then you follow the various links, from ethno code to people and their content. For example: start with a code you are interested in, say "refugees", and see other codes it might be connected to, for example "France". Click on the edge between "refugees" and "France" to find content that is coded with both codes, like @Alex_Levene 's beautiful posts on The Jungle.
- The problem we are facing is how to filter this mass of information so that the (human) analyst is not sidetracked into relatively unimportant things (unless she wants to be). So we have to come up at filtering techniques.
- We decided the right place to start is the code-to-code graph. But that is also overwhelming: even this early in the study, Amelia identified 460 tags, connected by 5,116 co-occurrence edges. And back to the question above: how to filter it?
Below you can see our first shot. The scatterplot shows co-occurrences of ethno codes. On the x-axis, we have the number of co-occurrences (edge force); on the y-axis, we have the number of different users who authored contributions that host that co-occurrence.
Example. Suppose the co-occurrence of “refugees” and “France” has x = 5 and y = 3. This means that in opencare there are 5 posts or comments, authored by 3 different users, that have both the “refugees” and the “France” tags.
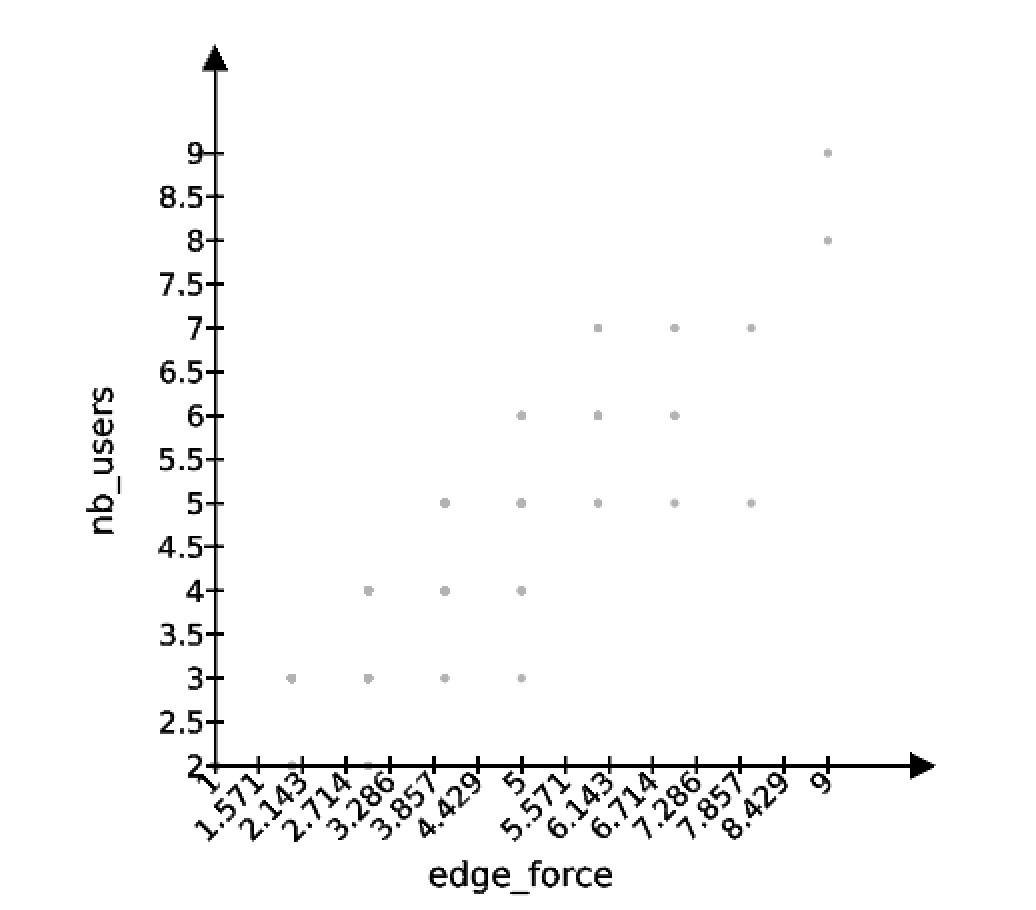
We used the scatterplot to reduce the code-code graph, selecting only the codes that co-occur at least twice, by at least two different users. This is now much more readable: 180 codes, with 678 edges. We plotted it below:
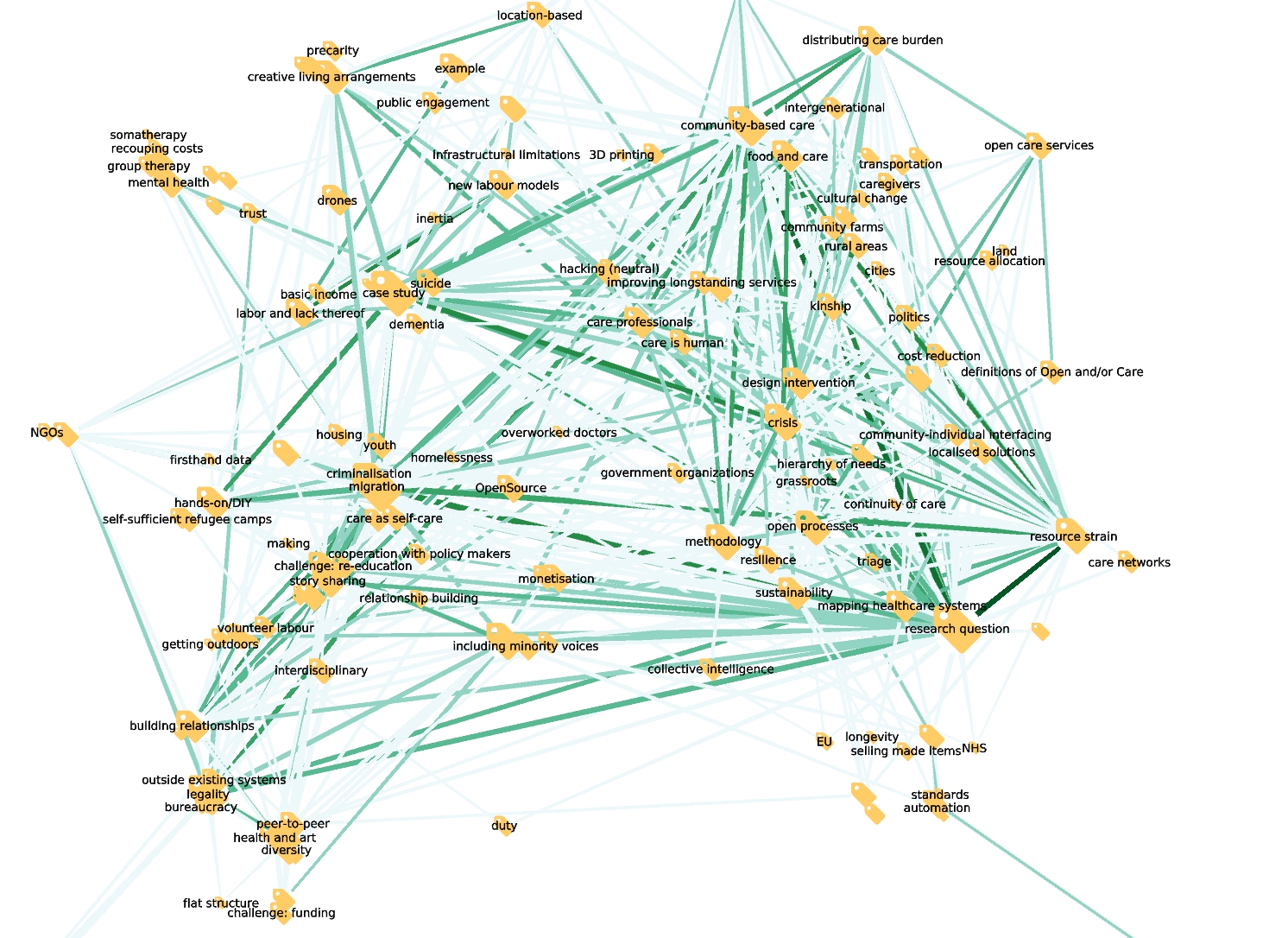
At this point, you can start to explore the graph. It’s quite a beautiful experience. I see it as exploring someone’s association pattern, except “someone” is not an individual, but the whole opencare community. It’s, well collective intelligence!
For example, look at the codes co-occurring with “mental health”:
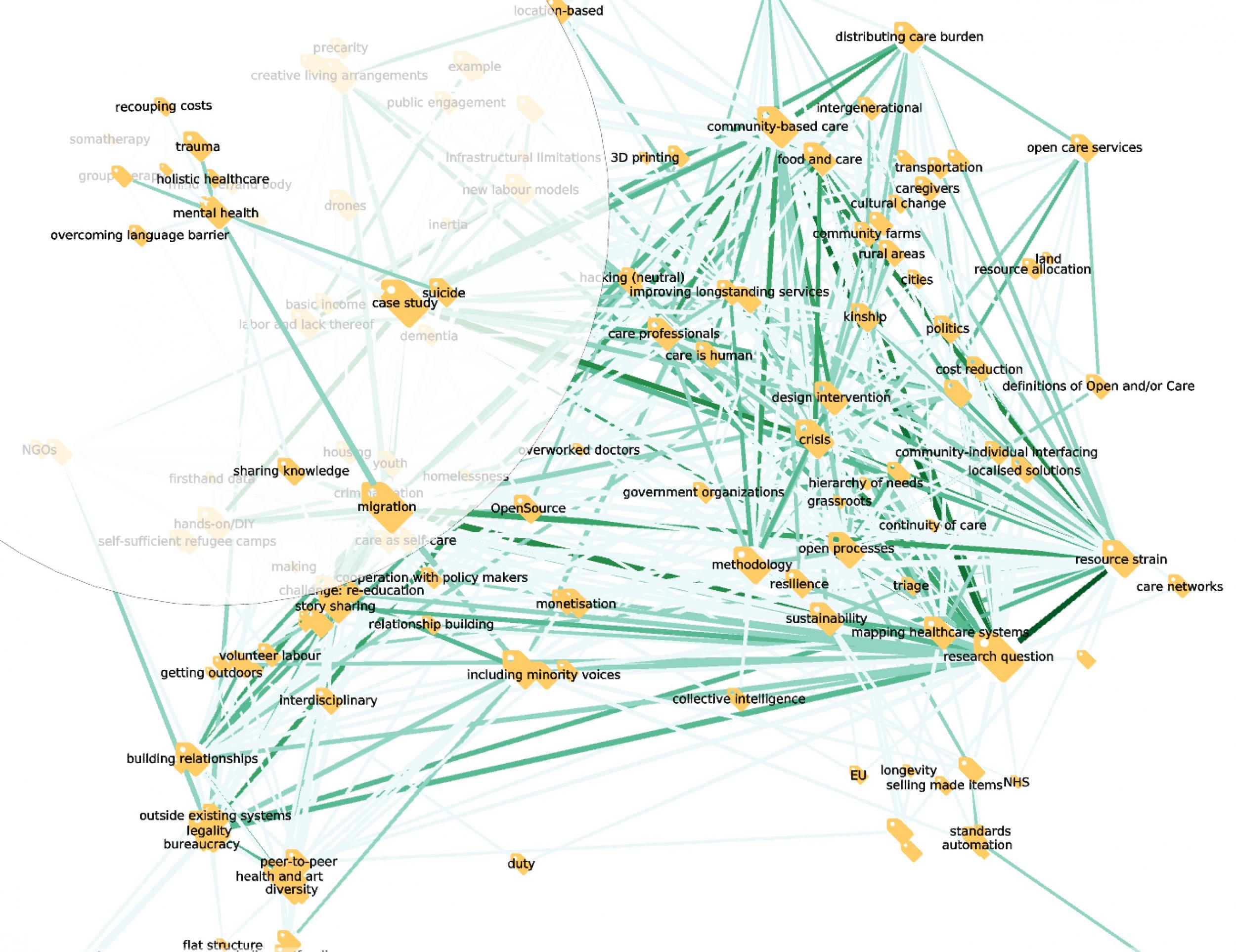
The community is saying there is a strong connection between migration, trauma and mental health. It is tempting to interpret this as an indication of priority: other things are surely important (eating disorders, for example), but these connections, and not others, are top of mind.
Another example: youth.

Very clear: you see the problems (housing, resource strain, discrimination) and the strategies deployed to face them (creative living arrangements, migration, skill sharing).
We can go much further. In fact, we already are. We can now induce the social network
So, I think we have a very, very promising research methodology on our hand. But we also have questions for Amelia. There are codes we do not understand, like “research-question” and “case-study”. They would make sense as meta-codes, categories of codes, but they are not, they are directly associated to snippets of texts. I guess doing open notebook ethnography, with people like me asking questions even while you still are coding, is more difficult! ![]()
