This post is a follow-up to a previous post I wrote here, so if you haven’t read it perhaps check that out first! I’m going to go through the points I made in that post more explicitly as they relate to the Open Village project and to future projects, as well as reflect on the co-occurrence network generated from the Open Village coding.
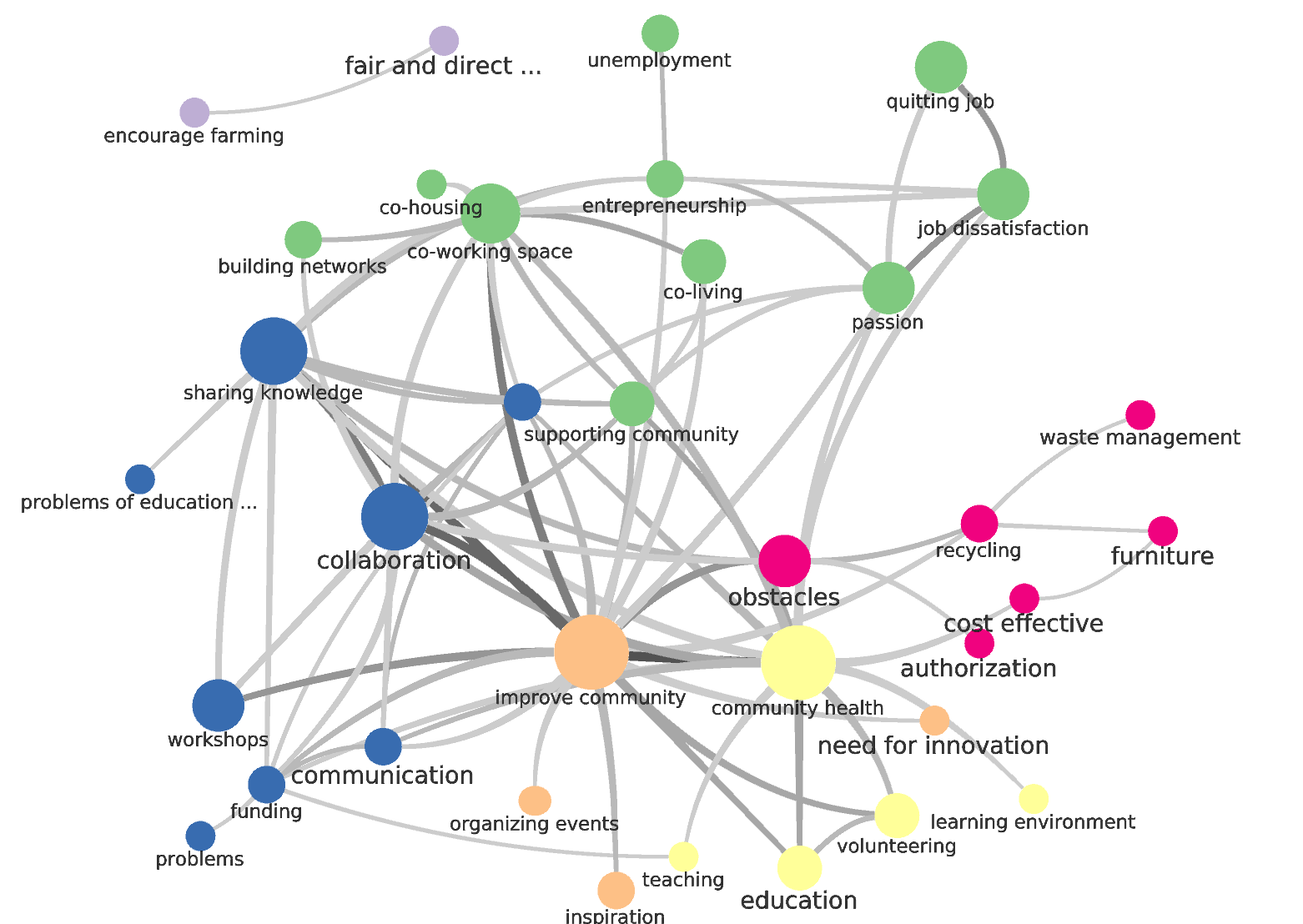
Let’s start with the co-occurrences network.
It seems to me that we need to implement something of what we have discussed with @melancon on multiple occasions – a way of creating code hierarchies. One of the reasons this graph is somewhat difficult to read is that there are a lot of higher-level codes that don’t carry that much specific meaning (e.g. “obstacles”; “improve community”; “supporting community”). These kinds of codes are definitely useful (think back to the “community-based care” code in Open Care that carried a lot of meaning in its co-occurrence with other codes). But because they are more generic, they are more likely to co-occur with other codes, as they apply to a wider range of concepts. You’ll find obstacles in places as disparate as recycling (to draw from this project) and domestic violence reporting (to think back on other projects). Also, I’m interested in how ‘obstacles’ is productively different than ‘problems’ which appears in the lower left hand part of the graph. (If there is no productive difference, they need to be merged. There is also ‘problems of education’ which is its own code despite there being ‘problems’ and ‘education’ codes).
This is why the ethnographer coding for SSNA has to be careful with these kinds of codes. Even more general codes have to have a precise meaning. So my concern with this particular ontology, for example, is that I can’t see a clear difference in meaning between “supporting community” and “improve community” based upon co-occurrences or in my own mind. As a result I think they need to be merged or clarified. “Community-based care”, for example, went through a few different merge/fork iterations, swallowing other codes that were being used interchangeably with it and forking from codes that were meaningfully different (such as ‘peer-to-peer’, for example, which community members were using in a specific context).
Similarly, how does ‘sharing knowledge’ differ meaningfully from “collaboration”? I can certainly imagine a few scenarios in which they’d be different (there are kinds of collaboration other than sharing knowledge, for example) but would expect more of a code network around to let us know.
I’d love to know how collaboration and obstacles connect, and am confused as to why there aren’t more codes surrounding those two. I can imagine if they co-occur so much that there should be codes co-occurring with the both of them that might illuminate WHAT those obstacles to collaboration are, or how collaboration can overcome obstacles! Those are the code co-occurrences that make SSNA so useful.
There are also codes that don’t have a clear meaning to me in isolation or in their network. What does “authorization” mean? Perhaps it is like our regulation - safety - existing system failure nexus in Open Care-- looking around it, it’s possible that lacking proper authorization (not sure from whom in this case) leads to obstacles, or vice versa?
Let’s crawl out of those weeds for a moment and look elsewhere in the larger picture. I’m interested in the quitting job - job dissatisfaction - passion triangle. I can imagine (and from reading many of the posts) I gather that a lot of people feel a lack of passion in their current employment situation. I also see unemployment, but am interested in why it is unconnected to that nexus.
Similarly, I’m interested in why ‘education’ is unconnected with ‘sharing knowledge’. But education - volunteering - community health could be interesting! How does education relate to community health? Are we talking about mental health or physical health? I’m also having difficulty clicking on nodes to see the conversations beneath to dig deeper, but I will give it another go soon.
As @alberto mentions in this post, the graph does illuminate solutions (and potentially the issues as well: job dissatisfaction, unemployment, potentially authorization, and funding problems (those are two different linked codes)). I definitely get a general sense of problems and solutions from the graph. I also feel a renewed sense of confidence in the method: even in suboptimal coding conditions, higher levels of meaning are still emerging in the social semantic network that allow us to get a big-picture view of a conversation as a whole.
Moving on from that brief discussion of the codes to other lessons learned.
-
It’s clear to me that we need people with explicit experience in both ethnographic research/writing and qualitative coding/data analysis. A lot goes into ethnographic coding that can be invisiblised, but in order to have high quality outputs there have to be high quality inputs. This graph to me illustrates a lack of underlying rigour in coding practices — merging similar codes, forking codes that have distinct meanings, generating codes that have a clear meaning, and coding thoroughly enough to create maps of co-occurrences. You can view my other post for a discussion of why coding fidelity is fidelity to our community members and is therefore a very important task. In future projects I therefore think it is imperative to take the time to onboard people with explicit experience and who demonstrate a committed attention to iterating in coding practice.
-
Flakiness test. This process was rife with flakiness issues — we lost a few people early on who had committed, and ended up re-onboarding a person who had originally disappeared. More periodic disappearances occurred after that, making the entire process frustrating. In future projects, we need people who commit to showing up for calls, since we are going to have to communicate frequently across language coding. Frequent and open communication is vital to make sure the coding starts high quality and remains that way throughout so that the emerging graph carries meaning.
-
Open Codebook. I talked about this in the last post, but in order to ensure rigorous coding I think we need to keep a codebook which allow us to keep our coding decisions rigourously supported and also easily communicable to our teammates.
Added later: I am also realising as I do this that the graph is an excellent way of doing code cleanup in a supervisory capacity (e.g. as the one not doing the coding)! If I had this throughout while supervising someone I could much easier actively advise them on where to look to potentially improve or clarify their codes.