Let’s use it to enhance and update the report that @Leonie@CCS and I worked on before, so we can get it publish. Please check out the viz before our call tomorrow so we can discuss it, and we’ll prioritise this as an output that we get out ASAP. @katejsim
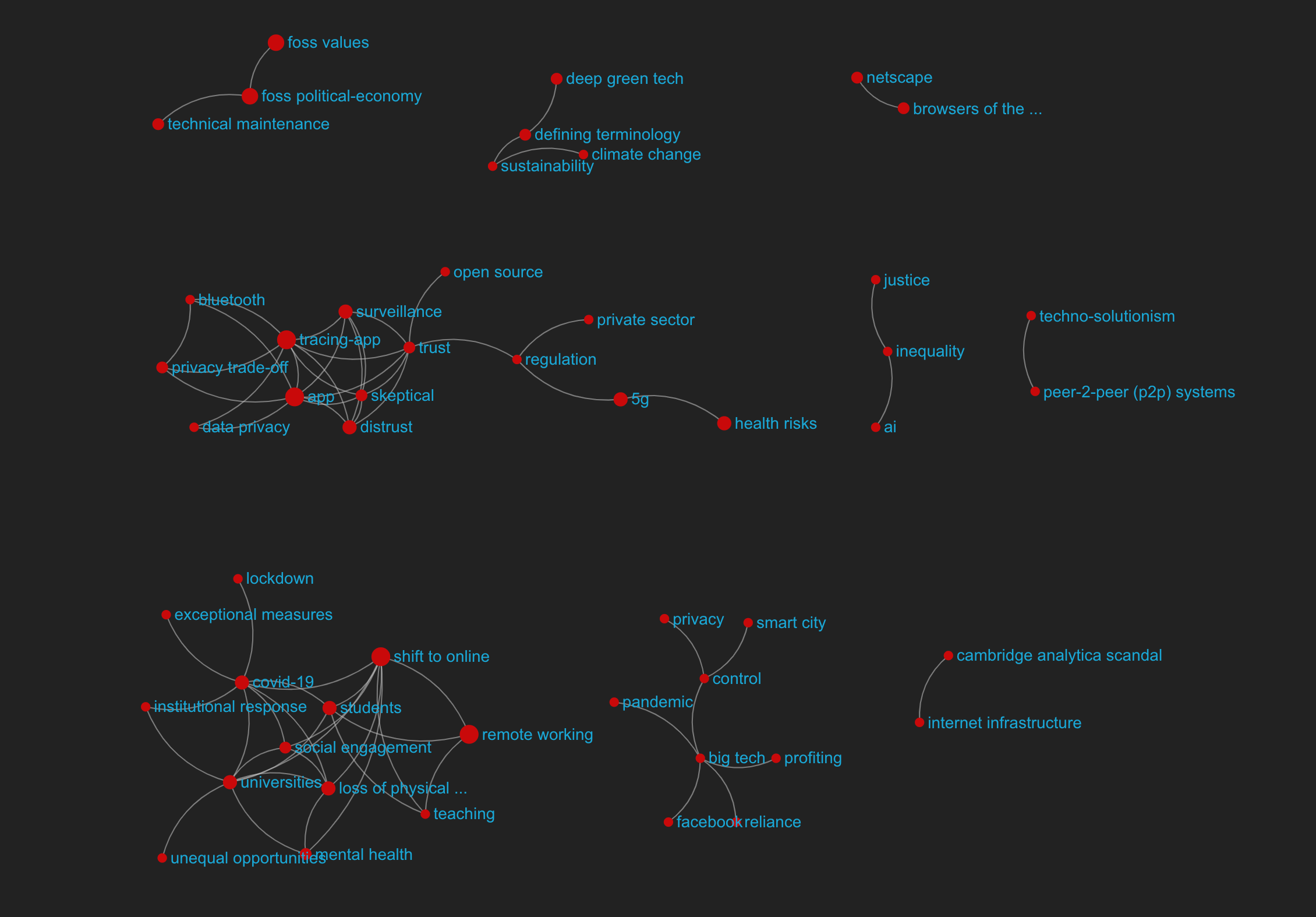
Here’s a screencap of the co-occurrence network set to k=3. My first observation is that we need to try and code with more attention to the big picture (using more top-level codes), because I know that there are more common threads than I am seeing here. So let’s go through the codebook alongside Graphryder to see what we codes we could copy into their higher-level hierarchical concept (without losing the smaller one, of course). If this is unclear right now, don’t worry, I can explain in the call (or check out the Hierarchies section of the Ethnographic Coding Wiki).
Second, we definitely need to merge instances of “tracing-app” into “app” (so, make “app” the parent of “tracing-app” and copy the annotations over).
The COVID and remote connection is the coolest to me right now, because we get a good idea of a issues, causes, reactions, and responses framework. Although I might be biased because I know I coded some of those threads
Just observations off the cuff. Looking forward to your interpretations! @alberto this might be of interest to you.
I did exactly the same thing (visualize with k=3) as soon as Matt released the dashboard. For me, the immediately intriguing bit was the cluster around app, trust and surveillance. Like you @amelia , I wondered at app and tracking-app: they are even connected to each other, which seems to indicate that they are not parent and child.
Over the last two weeks, we’ve been moving our NGI Codebooks from Google Docs to Sheets, and it is nearly complete! Sharing the link here. Comments welcome!
This is currently the ego network around the code “coworking”
From this, @katejsim, would you say that the graph was generated before or after you coded?
@nadia, we are also going to do a code merge and new viz over the next few weeks, so we can code any new content you post on the coworking thread for inclusion in this process too.
Also @Leonie and @katejsim remember that we designate invivo codes while we code in double quotations, not in parentheticals (see the coding wiki). Seeing the (invivo) on the code “not leaving”, so please edit any codes like that into the double quote format!
Notes after Codebook Category First Pass (for meeting tomorrow):
Many, many codes need forking (there are too many compound codes that won’t occur more than once or twice).
Create parent-child relations.
Too many meaningless invivo codes (only use invivo if they capture something unique and interesting)
Fix capitalisation (only proper nouns should be capitalised).
Fix invivo designations (double quote for invivo, single quotes for concepts).
Be more parsimonious – most of these codes won’t occur multiple times. Think about the SSNA – what will be likely to meaningfully co-occur? This means a) assigning less only slightly different and synonymous codes but also b) assigning more high-value codes that will ultimately co-occur with more concepts, and therefore produce richer codes in interaction with each other. By assigning lots of very specific codes, you miss the opportunity to see the meaningful interactions created by participants.
It might seem counterintuitive that forking codes will lead to more parsimony, but once you fork the codes you’ll see that they then will be mergeable with other codes, creating less codes with more co-occurrences (rather than lots of codes with very few occurrences or co-occurrences).
Tomorrow we’ll make a start on this together and I’ll show you what I mean through examples, and then we can continue the work asynchronously. Please do not code any new threads until this is done and use your hours to do this code refining work — we need to up the code quality before we proliferate more codes.
As a brief example:
Co-code “future” + “internet” rather than creating lots of codes like “future of the internet” “future of technology” “future of everyday life”.
The first approach will give you a semantic web of future + all the concepts related to the future. the second method/process won’t ever show up on the SSNA.
Coding in the former way will also allow you to see the global concepts that you’d miss otherwise — otherwise, the codes won’t show you much about the collective.
While you’re making the merges and forks to the codes based on the categories we defined, please also fix any issues you see as you go – spelling errors, lack of definitions, etc.
We have a huge problem right now with duplicate codes due to capitalisation errors. I’ve responded to and marked as important @matthias suggestion on GitHub to automatically merge any codes of the same name of the same case (thank you!), but we can’t do this for codes of a different case as we risk merging codes with different meanings that way. So I need the following:
Using the new “tree” display for speed, go through and make all non-proper nouns lowercase. I’d filter by user @CCS to start out with since it’s mostly those that are in uppercase. Once those codes are in lowercase and we have the automerge function in place, they should then be automatically merged into the other lowercase code, saving us time. This is important so please prioritise it – it shouldn’t take more than an hour. I recommend splitting the alphabet between the two of you. I’ve done a lot already but there’s quite a bit more to go.
Going forward, this is instructive. Please make sure both of you do code review after every coding session and clean your codes — make sure they fit the coding conventions both technically (in terms of case, invivo designation, etc) and semantically (that they aren’t a synonym of existing codes, that they aren’t compound codes, etc). We will save ourselves a lot of headache going forward if we do this while we work instead of trying to go through 1000s of codes retroactively.
As I make these changes, I want to reiterate something we discussed in the last meeting we had.
I’m noticing that the coding thus far is very literal but largely not very descriptive. When you code, don’t code for “content”. If a machine could assign the same code as you’re assigning, that’s a good sign that you need to rethink how you’re coding. As an example of this, I’m seeing a lot of invivo codes (where you use the same terminology as the participant) used when the term itself isn’t special, rather than thinking about what they mean and finding the right code to describe that meaning, in line with the codes you’ve used previously if the concept has come up before. See your desire to automatically assign an invivo code as a red flag going forward, and ask yourself if you’re using their exact word because it’s the word that saliently captures the concept (and the one you’ve been using thus far to capture that same concept) or because it’s the easiest thing to do in the moment. We code for meaning — what is the point of what this person is trying to say? What are they trying to get across? What values and worldview are they putting forward?
This means assigning more descriptive codes (like seeking purpose or defining justice or building inclusivity; access and education; complexity and asking experts) rather than codes like limiting or involvement, which have no real meaning. This also helps you not overassign codes or create overly compound or vague codes. @Leonie@katejsim. Think – if the codes I assigned to this post or comment were assembled together by themselves, would the viewer be able to tell the story of what this person is thinking or feeling?