We are trying to reduce the brittleness in our software for SSNA (aka SenseStack). Right now, the situation is:
- Ethno coding is done in OpenEthnographer. OE is a piece of our Discourse platform, and so pretty robust. All the ethno data are saved in the same (relational) database as Edgeryders content.
- Graph analysis is done in GraphRyder. GraphRyder is not robust, just a prototype so far. GR does not build graphs directly from OE; it first imports data, and stores it in a Neo4J (graph) database and then builds a JSON version of this data which is stored in memory and served to GraphRyder.
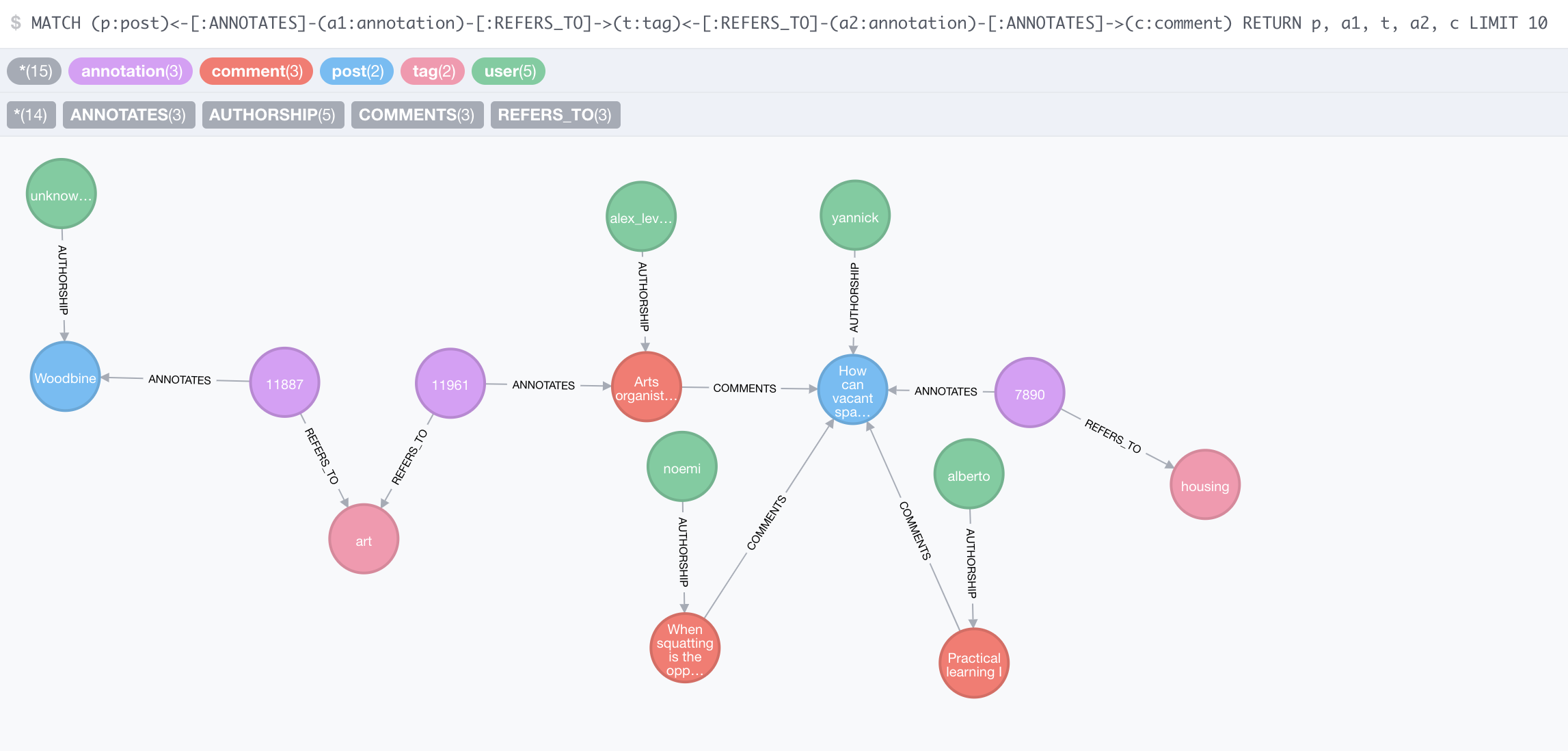
This wiki is a concept map of important entities in SSNs, and of the relationships linking those entities. The idea is that, by doing this, we set the scene for improving the stack. We might also get ideas to streamline it and make it more robust.
Logic
We follow the logic of the graph database. The annotated corpus is represented as a network. This network, however, is more complex than the SSN as proposed by our paper, as it includes more entites (ethnographers, collections) and more relationships.
Entities
Entities are:
- Participants. People who participate in the conversation.
- Contributions. Quanta of content with a unique identifier. In our case, posts on the forum.
- Annotations. Quanta of meta-content, associating contributions to some information created by analysts.
- Codes. Keywords used to assign semantic value to contributions.
- Researchers. Analysts who take part in analyzing the data.
- Projects. SSNA studies: collections of posts that make up ethnographic corpora, and of annotations thereof.
Relationships
- participant is-author-of contribution.
- contribution is-reply-to contribution.
- annotation annotates contribution.
- annotation contains code.
- researcher is-author-of annotation.
- researcher is-author-of code. We might even omit this, given the “wiki” nature of codes. On the other hand, different researchers and different studies might want to use the same code in different ways. This creates potential for confusion at the human level. How to solve it?
- annotation forms-part-of project.
All relationships can also be followed backwards: for example “contribution is-authored-by participant”.
Combining these relationships one gets all other relationships, including the mathematically meaningful ones we use in SSNA proper. For example, one edge in the co-occurrence network in GraphRyder means “code1 co-occurs-with code2”, which resolves in:
code1 is-contained-in annotation1, that annotates contribution1, that is-annotated-by annotation2, that contains code2
when
annotation1 forms-part-of project1 AND annotation2 forms-part-of project1 .
A radical approach to Graphryder functionalities would be to simply store the data in Neo4J according to this structure, then use Cypher queries to “flatten” the awkward six-mode graph into visually intuitive one-mode graphs. Neo has native layout algos, so visualization should not be a problem. There is also some limited export facilities (see).
However, if we do it that way we lose the nice lasso interactor in the Detangler view in Graphryder.