This is a post to see where we are with the POPREBEL study, for the benefit mostly of @Jan and @rebelethno
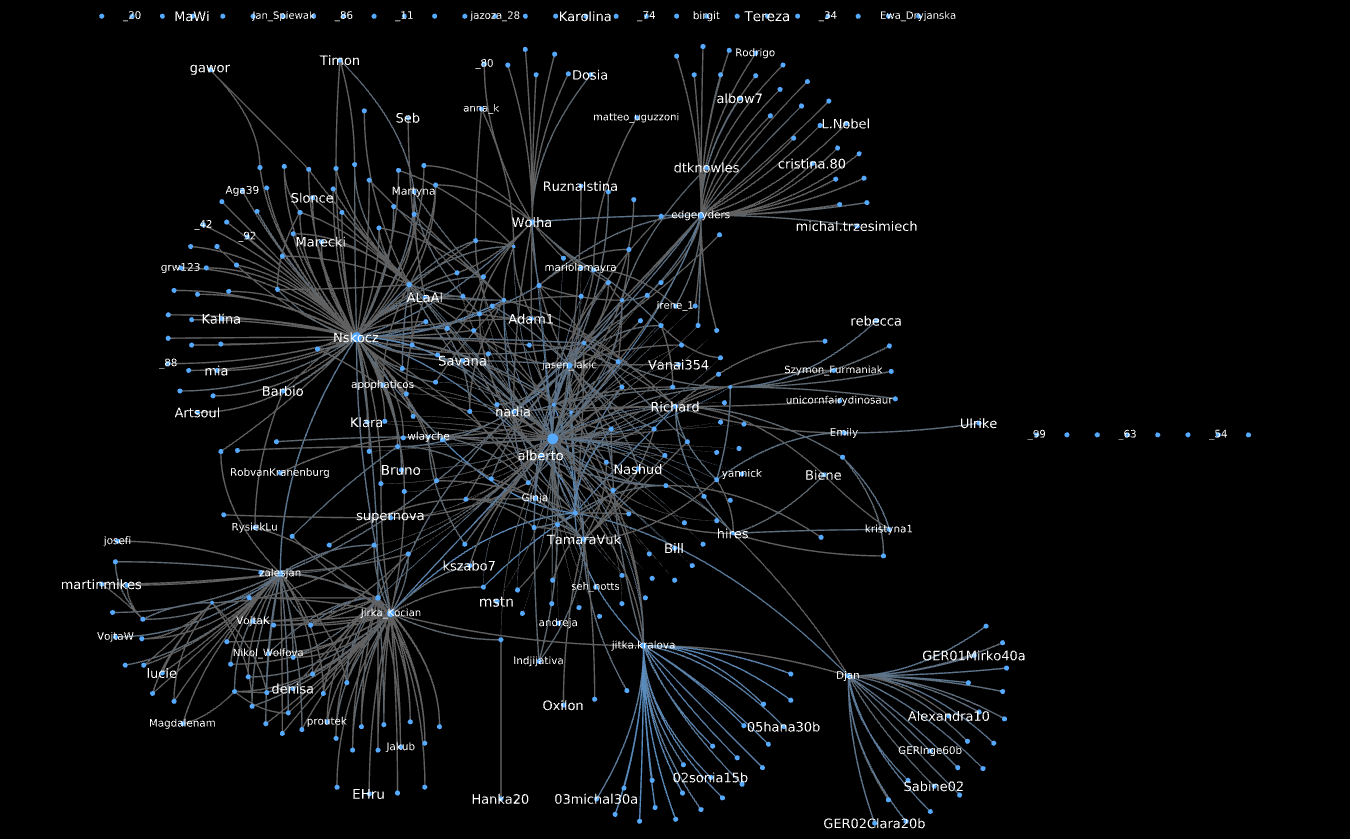
As we head towards the end of the project and turn the engagement engines off, the corpus has reached a respectable size: 381 informants, with 3915 contributions and 714K words overall. The overall hub-and-spoke structure of the social network has not changed. With one exception: more singletons, which now correspond to uploaded interviews.
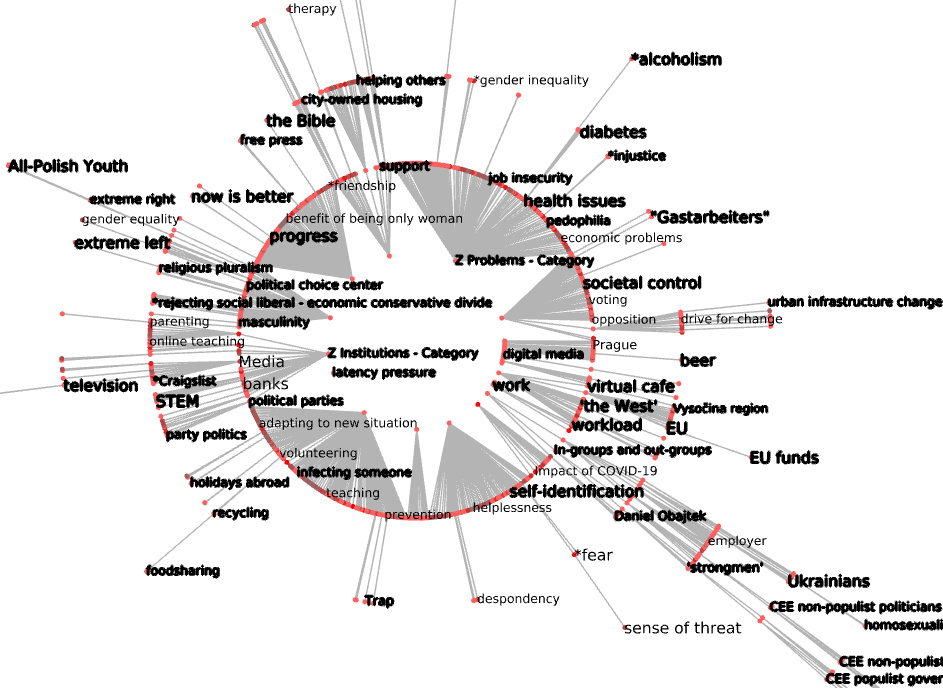
Coding has been intense in the past few months. The ontology of codes have been constantly under review, with a lot of merging, splitting, renaming and categorization. At the time of extracting the data (2021-09-28) there were 1,605 codes in use used across 6,677 annotations, connected by 158K edges representing codes. The unique co-occurrences (the stacked edges in the graph) are 52K. I included a visualization for k=015.
A lot of work has been done in reorganizing the codes into a hierarchy. Elements of hierarchy were present before, but there are now as many as 6-7 levels of hierarchy.
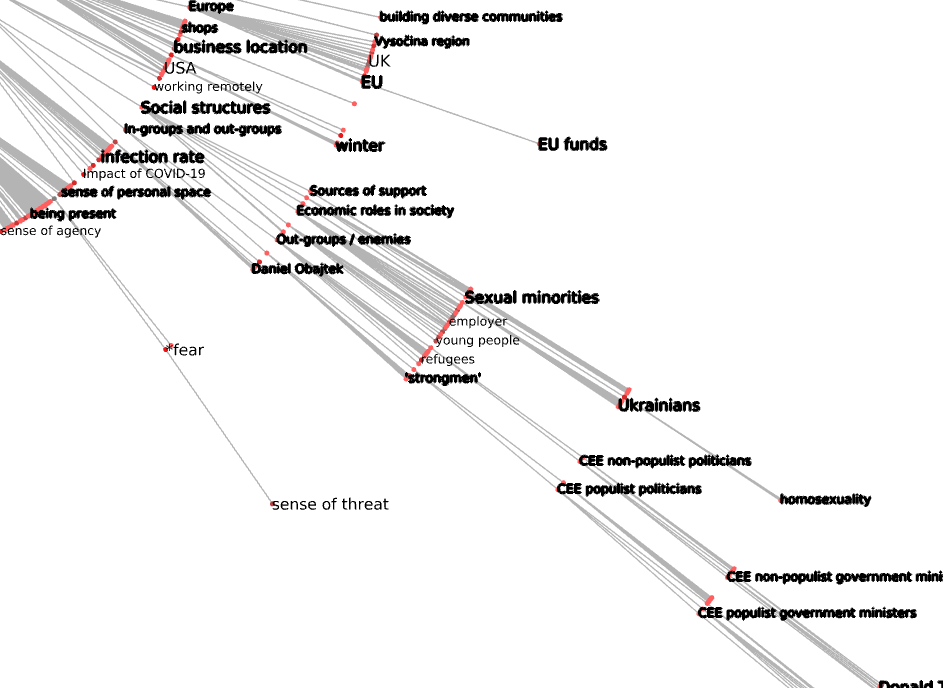
I need to pospone an analysis of the corpus by language because of some missing decisions about how to store the non-forum conversation ethnographic data.