Maybe the mighty @bpinaud can help?
Hello all,
yeah, easy. When did you download Tulip? The installers for MacOS and Windows were replaced a few days ago due to this problem. See https://tulip.labri.fr.
A 5.5.1 version is coming quickly to fix some horrible regressions (my bad)
Bruno
4 Likes
That worked!
2 Likes
Thanks Bruno! While I was at it, I also upgraded to 5.5. I’m getting better at Tulip, you and @melancon would be proud of me!
1 Like
Yeah great!! Next time we meet, I want a demo and a drink (I remember one year ago in Brussels in the small Italian bar. That was a great moment.
1 Like
Bruno, just a heads up: I downloaded Tulip 5.5. The agent starts OK, but when I try to load my perspective they crash upon loading. I had do downgrade to 5.4, and everything worked again.
BTW let me know if I should post this stuff elsewhere, like a community forum for Tulip!
umh, this should not happen. Send me your file directly. In the Tulip world, I think you are trying to open project (a tlpx file) and not a perspective (which is a complex piece of c++ code and a type of plugin).
Is your file self-contained? Are you using any specific plugin not included in the Tulip distribution?
Now I cannot reproduce the error… ![]()
@rebelethno What do you say, guys, if we ask @alberto to create a new, more up-to-date file for the Tulip visualisation? I have created a code “populist politician” where I have copied and merged annotations of Trump, Orban, Salvini, Duda etc. I would like to see how this worked (it has 27 annotations connected from all three of the fora).
Can we set some deadline for (at least some) merging, and after that Alberto will create a new file for the SSNA visualisation? (Let’s say some day around the mid of February?)
We should also ask Alberto not to include annotations from Serbian forum into the “composite”, right?
1 Like
Sure! I agree, just when would you like to set the “deadline”? I am still working through load of terms papers that need to be graded, not sure how much will I manage to contribute with my code merges, though I plan to do at least some this week…
Hello, I re-computed the graph as promised.
Hello all, I know you are deep into coding and we are probably not ready to move on with the analysis by language. Nevertheless, I decided to revisit my code to make sure I can be ready when you want to start looking at graphs. It turned out to be a good decision, because I discovered a phenomenon that we must confront.
What I did
First, I amended the code to take into account a new language, German, and several new categories where material can be found.
Second, I built the overall graph, and ended up with 1,546 codes (excluding the “metacodes”, used in the hierarchy but not in annotations) and 53,111 stacked edges. None of the edges are self-loops: co-occurrences of a code with itself do not make analytical sense, so those edges are not created at all.
Third, I reduced it in two ways. The goal was to bring the reduced graph to fewer than 4 edges per code.
- One way selects only the edges representing co-occurrences found in the contributions of at least 4 different informants. This graph has 174 codes and 571 edges.
- The other way selects only the edges representing co-occurrences found at least 9 times. This graph has 470 codes and 1,770 edges.
Please notice that now edges are stacked by language, and are therefore not unique in these graphs. If code 1 and code 2 co-occur five times in the Polish corpus and two times in the German corpus, they will be connected by two edges, one with d(e1) = 5 and the other one with d(e2) = 2.
Here is what I found.
1. Reduction by d >= 7
This graph looks like this:
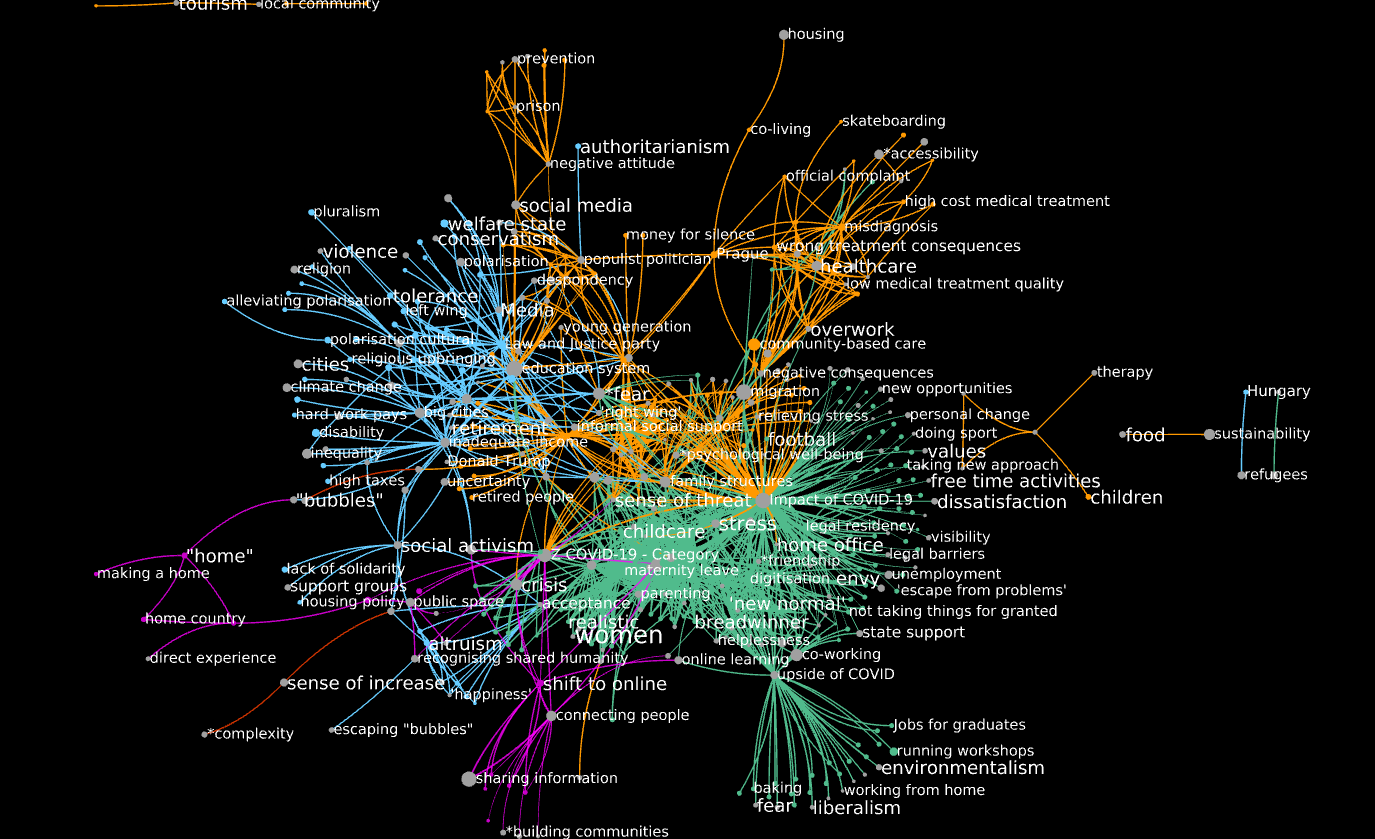
color_coding = {'German': 'green', 'Polish': 'blue', 'International': 'purple', 'Czech': 'orange', 'Serbian': 'red'}
A few comments:
- A giant component connects most codes, with only a few very small “islands”.
- German-language edges are the most numerous by far (1,069), followed by Czech-languages ones (396). This is in contrast with the unreduced graph, where Polish-language edges are the most numerous.
- Edges representing content in the same language are only in part grouped into communities, there is a fair amount of interpenetration between language communities. Several codes are incident to edges in two or three languages: some example are
universities(Polish, International, German),Z COVID 19 category(Czech, International, German),fearandeducation systems(Polish, German, Czech),
2. Reduction by b >= 3
This graph looks like this:
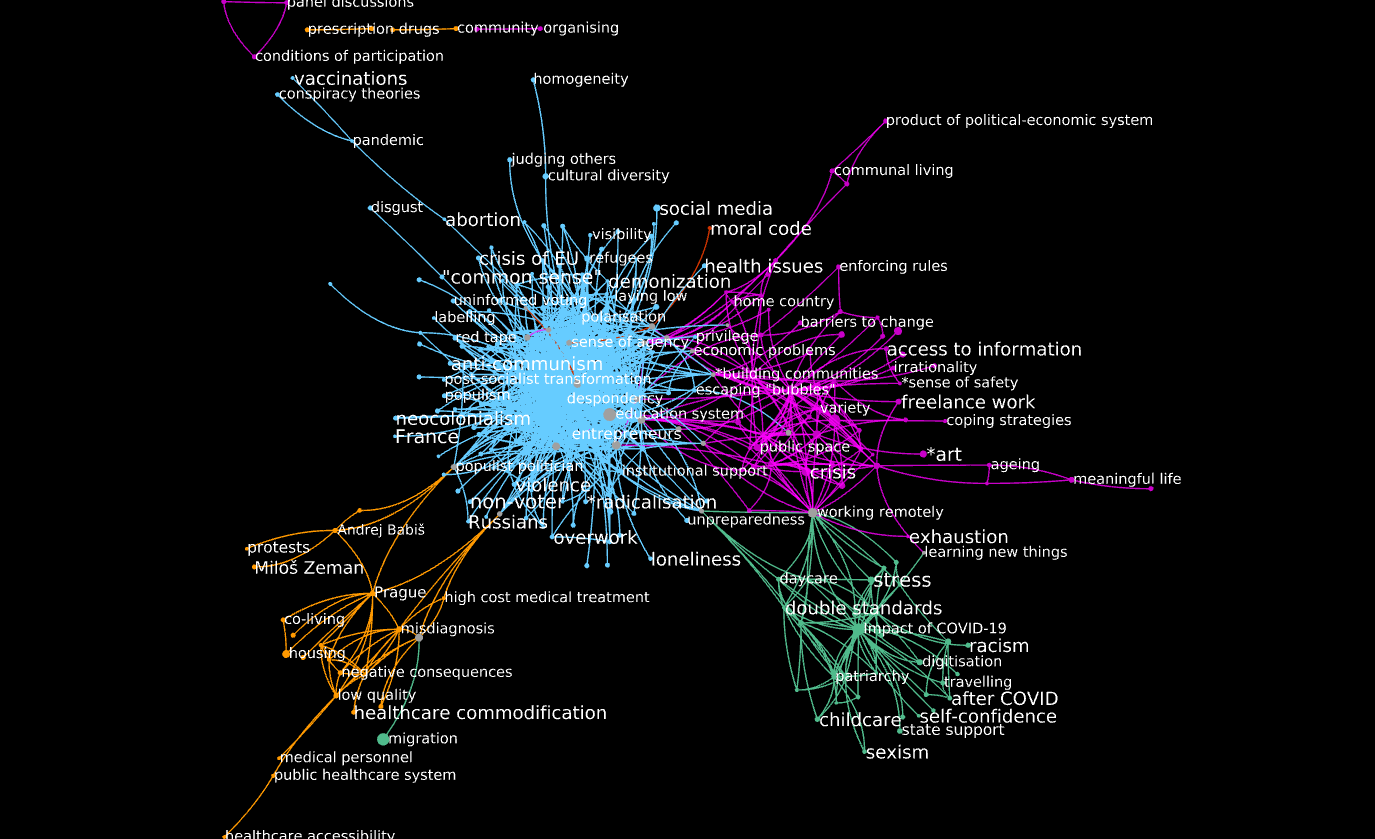
color_coding = {'German': 'green', 'Polish': 'blue', 'International': 'purple', 'Czech': 'orange', 'Serbian': 'red'}
A few comments:
- A giant component connects most codes.
- A large majority of edges are from the Polish part of the corpus (1,269 out of 1,6062). This probably reflects a larger number of informants expressing themselves in Polish. In fact, making sense of the Polish-language corpus might need further network reduction!
- In the giant component there is a very clear resolution by language community. Some codes connect the debate across different languages: the main ones, starting from the top and going clockwise, are
- Polish to Serbian:
sense of agency, sense of increase, Catholic Church, sense of decrease. - Polish to International:
alienation, bubbles, freedom of movement, economic problems, *building communities, informal social support, education systems, universities, uncertainty, institutional failure, family structures, inequality, media, mass media. - Polish to German:
motherhood. - International to German:
working remotelyandlearning new things. - Polish to Czech:
high pricesandpopulist politicians - Czech to German:
healthcare
- Polish to Serbian:
How to interpret all this?
It is possible that there are different coding styles in play; also, the higher number of informants behind the Polish-language corpus is likely to play a role.
The German corpus might have been coded using a relatively small number of codes, that co-occur often. Anecdotically, @Richard likes to use the same codes several times in the same post (example). As a result, when reducing by association depth d, quite a lot of edges from the German corpus get selected in. By contrast, the larger Polish corpus might have been coded in a more granular way: as a result, relatively fewer edges make it through the d(e) >= 7 threshold that we set here.
On the other hand, more informants have contributed to the Polish corpus than to any other. As a result, when reducing by association breadth b, quite a lot of edges from that corpus get selected in.