
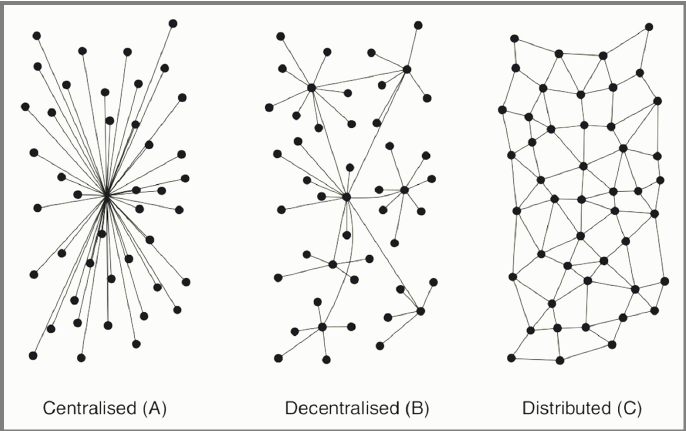
I was just in Berlin for the Data Terra Nemo conference and also ended up attending a DGOV meet-up. Data Terra Nemo is a conference to bring together the community developing open source protocols and clients for decentralized peer-to-peer applications. A very simplified introduction for those who are unfamiliar with the technology: Decentralized web applications are hosted without traditional servers. Instead, every client is both a host and a client. You can often still access these sites from traditional browsers, thanks to that many of them have been implemented in javascript. This shift allows for a lot interesting applications, and this is the scope of Data Terra Nemo.
Many of the sessions touched upon the current challenges of decentralized technologies.
Blindly hosting information for others comes at a cost
‘Gossip’ protocols like Scuttlebutt allows applications to share a pool of messages between users that are connected to each other. These messages are then interpreted by client applications, which can be social media applications, book recommendation services, chess games or private messages. I wrote a separate post about Scuttlebutt, and I am quite inspired by the community which has grown up around that technology. Largely because of the human-centric values of the core developers it has a unique feel and has attracted a big community for being such a bleeding edge technology. My reading of the role that Scuttlebutt plays in this space is that of the experimental avant-garde, the playground where new and radical ideas can be tested and implemented. Dominic Tarr, original developer of Scuttlebutt, had an interesting reflection on his own modus-operandi that I think has translated into Scuttlebutt itself, which is to “not build the next big thing, but rather build the thing that inspires the next big thing, that way you don’t have to maintain it”. And it turns out that the developers of Scuttlebutt are working on problems that affect a distributed technology at its core.
One of the core elements of Scuttlebutt is that I can host data for other people on the network without being connected to them directly. I can also host data on my own computer that is encrypted communication between users that I am connected to. This is a feature that is very useful in situations where Bob sends a message to Alice, who is in a country where traffic to the outside internet is highly restricted. If Cindy, who has the privilege of a VPN connection, is connected to both Bob and Alice, then Alice will receive the message from Bob as soon as Alice and Cindy connect to the same network. Cindy doesn’t even know that she is carrying a message between Bob and Alice, as both the message and the information about who is talking is encrypted. This is possible because, by default, everyone replicates the entire message stream of their entire network. In fact, many people replicate every message in their networks 2-3 hops aways from themselves.
This creates some challenges. If Hans is in your network and connects to Lars who is a neo-nazi connected to a group of other neo-nazis, you might actually be acting as a server for information that you would really rather not propagate. This is not a hypothetical case. There are already known instances of the Norwegian alt-right using Scuttlebutt as their preferred means of communication. Luckily for people that don’t want to deal with them or host their information, they are still quite an isolated part of the network and prefer to keep it that way. Nevertheless, it only takes that one well connected person on their network-island connects to another well-connected person in the Scuttlebutt mainstream for that isolation to be broken.
Scuttlebutt has tried to solve this with giving users the ability to block accounts they find abusive, but for those replicating data from a large network, they might actually never know who is posting that content. One solution that has been talked about is subscribable block-lists. This way, I could outsource blocking to a person or group I trust to maintain a block-list.
Luckily, the most worrisome case of abusive photographs and other image content is not as big of a problem. Images are only downloaded to your computer when your client actually sees them, making it clear to you that foul content has made it into your stream. You might still host links to those images without knowing, but you are not likely to have images on your hard drive that you have never seen.
Bottom line is that the community of Scuttlebutt is charging head first into the future, working on challenges that many more will be facing as the benefits of these technologies reach more hands. Distributed systems are both democratizing and empowering, and they come with a whole new set of possibilities.
I’d love to hear perspectives from @elch, @zelf and @hendrikpeter on this. Do you worry about this when using Scuttlebutt? How can we make these peculiarities of decentralized technologies visible without scaring people off?
{kind=link}