Keep it collective
Thanks @melancon . A general point is that we need to know precisely how any graph was built if we are to interpret the result with rigour. As Fernando Vega-Redondo likes to say, “when you talk about networks, you have to specify what a link is”. So, I would like to know more of how we compute this DOI index.
A more general point is: I am not sure we should even have thread-level views. What can we learn from one such?
Let’s assume the best-case scenario: we look at a single thread that has all the co-occurrences that appear in the conversation-level co-occurrences graph. We can reasonably imagine we could use this highly representative thread as an entry point to the whole conversation. We could read the post and its comments, and immerse ourselves in a meaningful subset of primary data.
And yet, that would be far from the whole story. We are on a quest for collective intelligence. A co-occurrence in our imaginary “golden thread” is only important ex-post, because it also co-occurs elsewhere in the conversation. If it did not, it could just as easily be the quirk of some participant to the thread. Also, the single-thread co-occurrence graph would be flat; we would not be able to arrange co-occurrences in a hierarchy, and so tell the most salient ones from the rest.
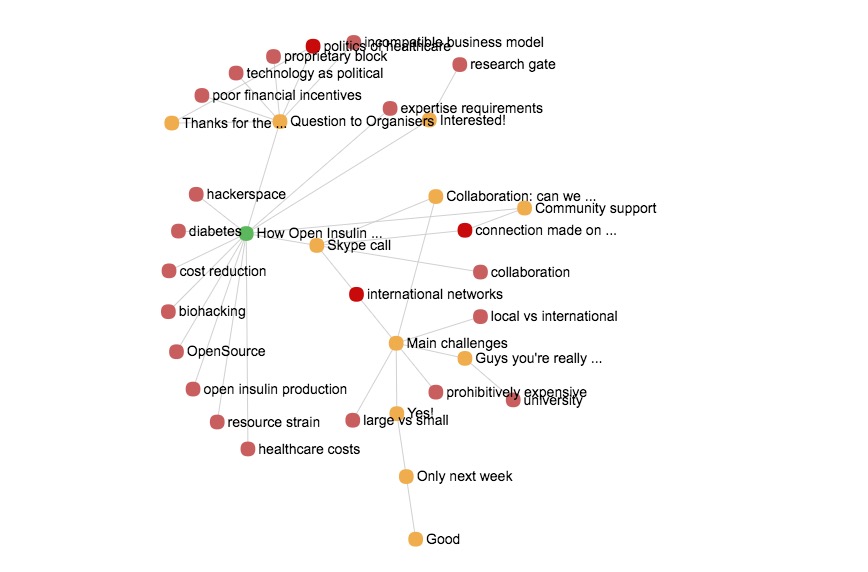
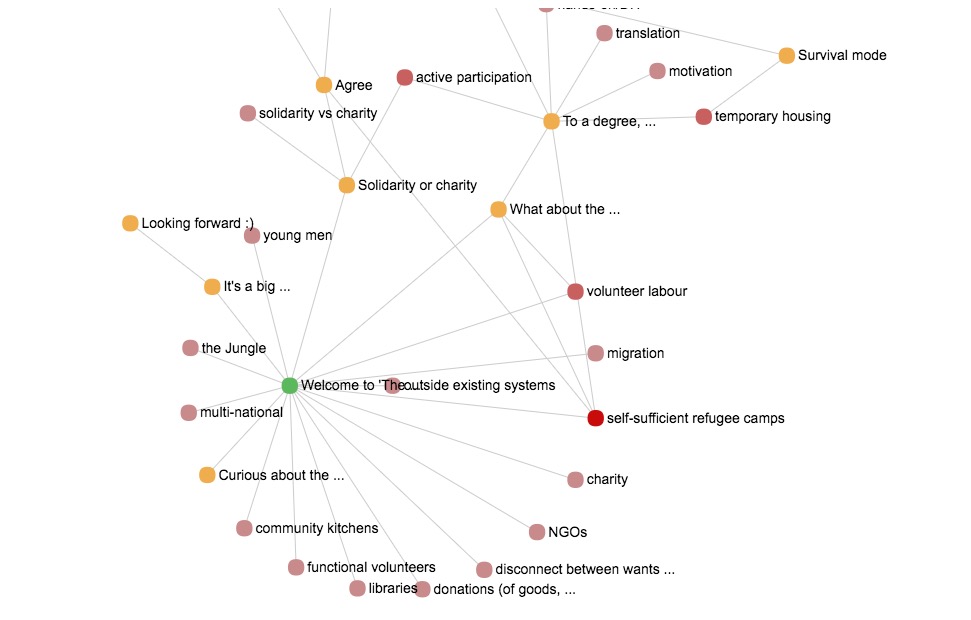
For example, in the Open Insulin post (see above) there are exactly zero pairs of codes that co-occur more than once. Of course each contribution with n codes induce an n-clique of codes co-occurring on that contribution, but that’s it. I tried to explore a few more threads. For example, this is @Alex_Levene 's first Jungle post:
Here, we actually have one real co-occurrence: self-sufficient refugee camps and volunteer labour co-occur twice, once in the post itself and the other in one of its comments.
You get the idea. I think there is not much point in having graph views on single threads. There is not much point. If it were up to me, I would simply delete the tab, and focus on building views that help analysts look for the signature of collective intelligence. “Collective” is the operative word: it means the data have to come from the whole conversation.
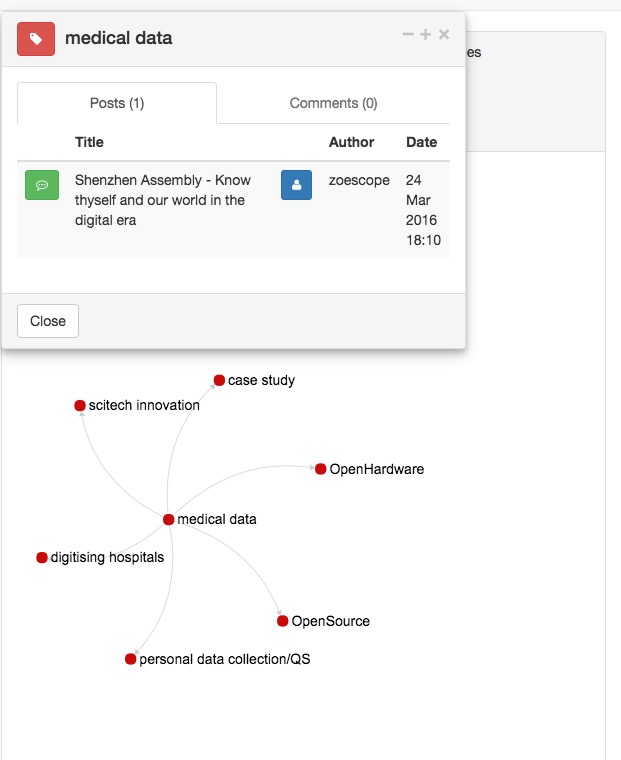
Still, I see a potential application for the work behind the view. If we can compute indices that represent “richness”, “coherence”, “interest” and the like, we can use them to recommend a point of entry into the conversation. Suppose I come to an already coded opencare conversation. I am interested in data in medicine. I discover a code called medical data. This is what I am interested in! At this point, I could get a list of threads that are associated with that code, with their richness/interest/innovation/whatever score. This would save me time by letting me zero in onto the most relevant content associated with my area of interest. The score could just be added to the list view:
What do other analysts think? @Noemi | @Amelia | @Federico_Monaco