Several questions here…
Thanks @Jason_Vallet … but I still don’t understand.
For starters, it does not look like I can select an ethno code, like you did in your comment. I can only select posts:

But even then, I don’t understand this:
because of their high number of co-occurrences (the metric used to find the interesting nodes)
I assume you use “co-occurrence” in our usual sense: a co-occurrence of ethno codes happens when codes are associated to the same contribution, which can be either a post or a comment. Each contribution’s number of co-occurrences is a k-clique, where k is the number of codes associated to that contribution. Since we are on a quest for collective intelligence, we normally focus on co-occurrence across entities. This is why we never look at the unfiltered co-occurrence graph; if we impose that the number of co-occurrences is > 1 we are sure that two codes will have been associated in at least two contributions. The number of co-occurrences can link any two entities:
- link a post/comment
ito other posts/commentsj = 1, 2, ...n, j≠iwithmax (n_(i,j), wherenis the number of codes co-occurring both iniandj - link a code
wto other posts/commentsz = 1, 2, ...m, z≠wwithmax (n_(w,z), wherenis the number co-occurrences betweenwandz - link a person to another based on co-occurrences across the corpuses of the content they authored
But this is not what the view does. Consider my previous example. The post about open insulin has 16 comments. The view only selects one. And that has no codes associated to it (it is short and semantically insignificant). So, it cannot have been chosen by number of co-occurrences. In fact, no code co-occurs in both the post and any of its comments (see below). So how was this particular comment selected by the algorithm?
A much more simple view to interpret is the one called “neighbours”. It’s simply the post, plus its comments, plus the codes associated to both posts and comments. With this view, the first Open Insulin post by @dfko looks like this:
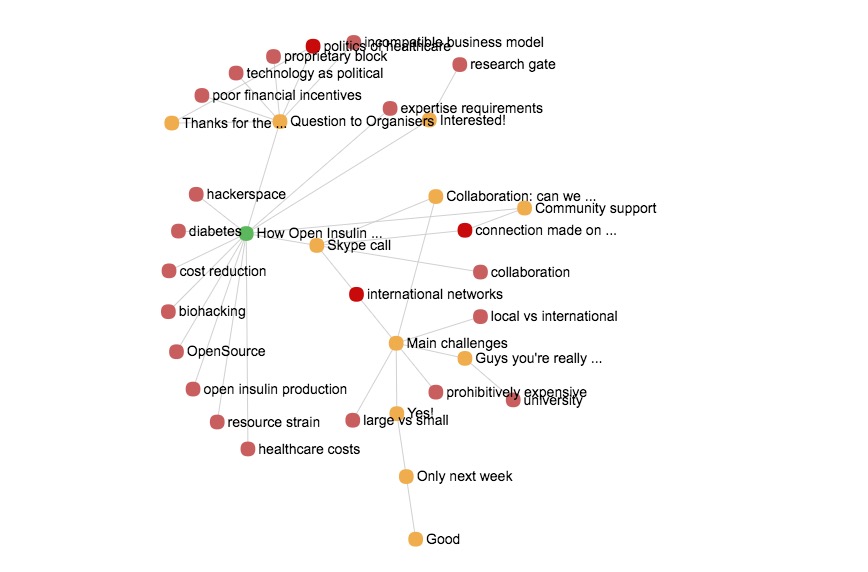
Co-occurrences of codes between the post and its comments are non-existent. Comments have not been coded with any of the 9 codes associated with the post. In fact, this graph is almost acyclical: only three codes (international networks, politics of healthcare and connection made on site) co-occur in two of the comments each. So, there is not much co-occurrence to drive the assemblage of the DOI view, let alone interpret it. The neighbours view could be interpreted as indicating the richness vs. coherence of the thread: more codes indicate a greater richness, more cycles in the graph indicate a greater coherence. But this information could just as well be conveyed by scalar indices. More in a further comment.