Calling @rebelethno. In May we are supposed to release the Codebook, as Deliverable 2.6. I am aware that this clashes with the timeline we agreed with @Nica (coding ends on June 15th).
The Codebook can be delivered when:
The ontology of codes is reasonably stable.
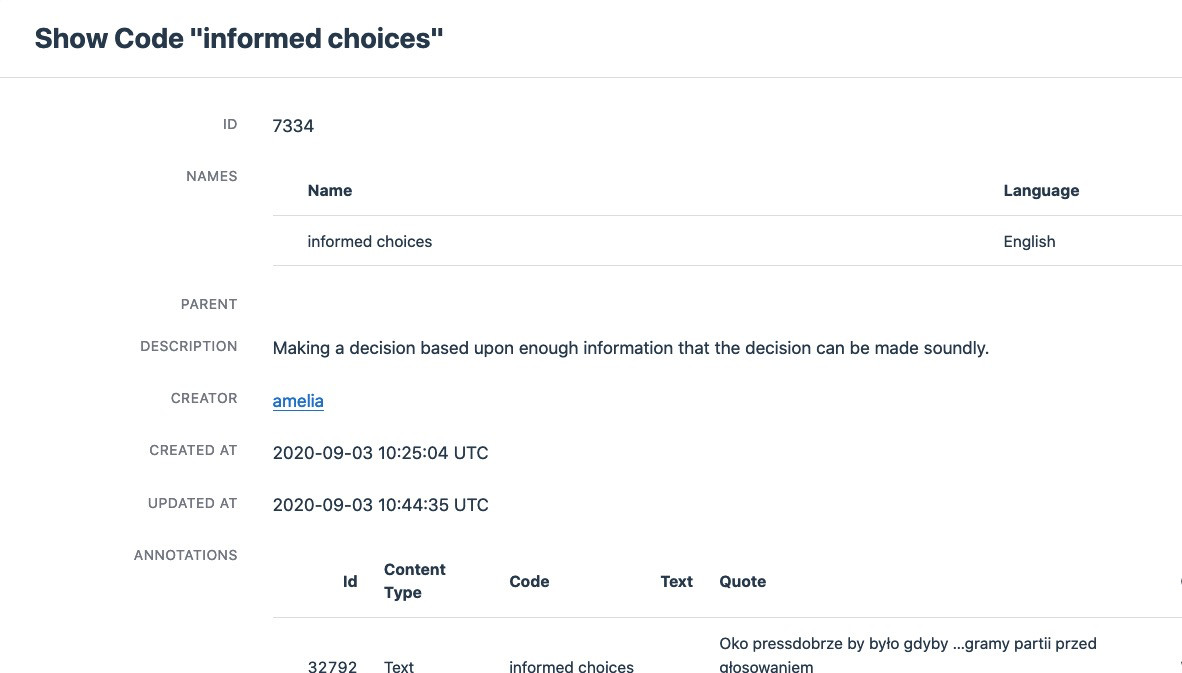
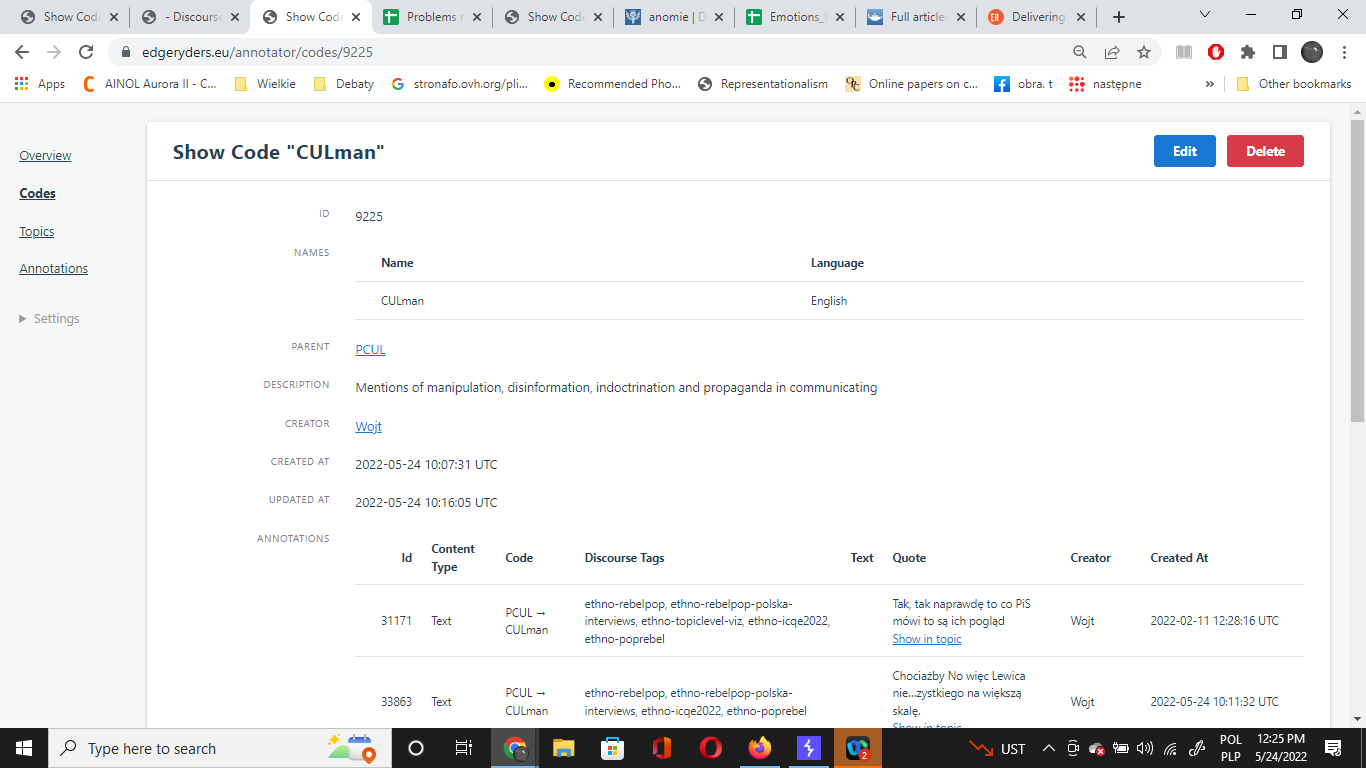
All codes are complete: label in English, eventual labels in other languages, description, like so:
Can you confirm this will be ready in June?
And to @matthias: I can export the codes via APIs, but: any suggestion on how to put it in a nice-looking, human-readable format, starting from the JSONs?
Is this supposed to be the final version of the codebook? Does it mean that we will not be able to introduce any changes to it after the release?
I think it is. Everything hinges on the definition of “reasonably”. I, for one, haven’t coded anything collected after the Russian invasion started and that event is likely to introduce some concepts/categories of concepts.
No, of course not. We can update as often as we want. But we do need much more than an early draft here. For example, if we still use ethno-poprebel, we get things like:
I noticed. Why is that? The idea behind a description is to enhance intercoder reliability. Amelia also was fond of examples of usage, and even indication of when not to use a code.
That made perfect sense, sure.
I don’t know about other people, but since she left I’ve devoted most of my time to working on the Google spreadsheet version of the codebook and visited backend only occasionally, probably saving checking it for last (once the codes and hierarchies from the spreadsheet version have been reflected in the system).
I see a couple of potential methodological problems, that could lead to bad results because of messy data organization. This is not, again, to lay the blame on you, @Wojt, or anybody else, in fact thanks for engaging. But the issues are there:
A fork in the dataset: now you have two version of the dataset, backend and Google Sheet, and they are different. Reconciling is going to be long and tedious. I would not have done it, but fair enough: you chose to do that, so OK. But now this creates a debt, as you manually copy work already done on another support. And copying is prone to introducing error.
A disconnect in the team: “I don’t know about other people…”. In the interest of intercoder reliability, all members of the team should be using the same tools, and adhering to the same conventions.
Trivially, Google Sheets “rip” the codes away from the data web of annotations and contributions, so we cannot use them to do data analysis, create visualizations, etc. When we were asked “one slide for the policy event”, it was only from the platform’s backend that we could induce a network, not from the sheet. Same for the ICQE paper. I strongly suggest we get rid of that sheet as soon as possible, after carefully bringing any changes into the complete and authoritative dataset.
Can you give me an estimate of the time it takes to update the back end and mothball the sheet?
We have an idea for managing that. Will discuss today.
The whole team was invited to participate in its development and they did. Richard and Jirka are quite familiar with what’s in there.
It does but we introduce the codes into the system by using them. Since there is a lot of material still to be coded, those that should appear eventually will.
I spoke to Jan yesterday and we will try to do it in two weeks, but we need to talk about the effects our actions may have on the corpus we’re using in the context of the ICQE delivery.
Decisions on the Codebook as of the meeting of today, 2022-05-20.
D.6 is pushed to September
Coding for dataset B1 should be finished by 15th of June. Finished means: good enough to start data analysis proper, but we accept smaller changes will be made for as along as we do analysis (roughly, 31st July).
The above concerns datasets A (forum) and B1 (pre-war interviews). The B2 dataset (post-war interview) will be pushed to a further deliverable (responsibility of UCL, not Edgeryders) or just to a future paper. Deliverable 2.7 will not analyze B2, but it will describe its data.
Also, we have created a “data catalogue” as a wiki. Edit away!
One more thing, is there a chance to add an option of destroying annotations from the Codes screen?
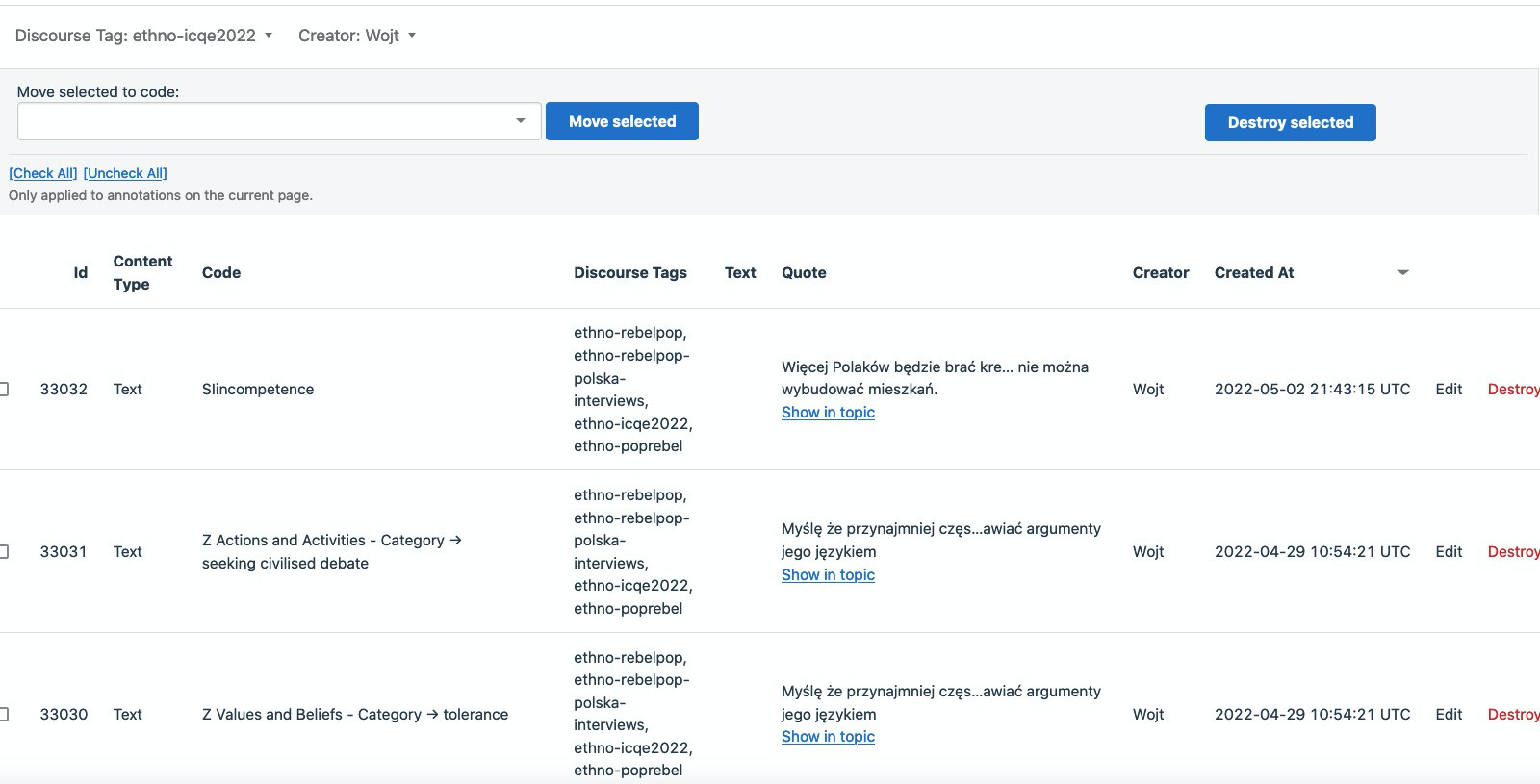
In the Annotations view, I can only search for phrases within annotations, not the name of the code associated with them and this is, I guess, the only place where I can destroy annotations in bulk.
If I cannot destroy annotations in bulk, I have to visit each text, find the annotation (which is sometimes tedious if the text is several pages long) and delete it manually.
Now the code https://edgeryders.eu/annotator/codes/729 should have no annotations associated with ethno-poprebel. Poprebel is henceforth using SAdiscrim.
Before I move forward with cleaning, I’d like to talk to you @alberto.
Hmm… I am not sure we should be able to bulk destroy things too easily. Plus, in code view you have (part of) the quote, so you can use that as you search for the annotation, no?
We DO have this option in the Annotations view, but it’s difficult to find annotations for any specific code.
I found a way to destroy annotations by their Id (which can be found in the Codes view), but I guess this method may be inaccessible to other coders since it requires modifying requests.
Yes, but some interviews span for more than one page and it takes several more clicks, ctrl+f’s, and more typing, not to mention the fact that they are sometimes hard to get to (if surrounded by other annotations).
You should refrain from doing that, because annotations can have more than one code. In that case, you want to edit the annotation rather then delete it, no?