Czech

List of the codes co-occurring with CULman in the Czech corpus
Andrej Babiš
anti-vaxxers
Bill Gates
children
communism
confusing measures
covid conflict
CULdisorient
CULman
DDpolcor
drastic measures
Ecorrupt
EDprogramin
Eeconcor
HSalternative
IHphysical
impact of COVID-19
infection rate
interacting with family
LAunemployment
Lubomír Volný
MIGinmigra
online platforms
Pirate party
political choice right
respirators/face masks
SIincompetence
social media
SPD
vaccinations
vaccine injury
vigilantism
Volný blok
Polish
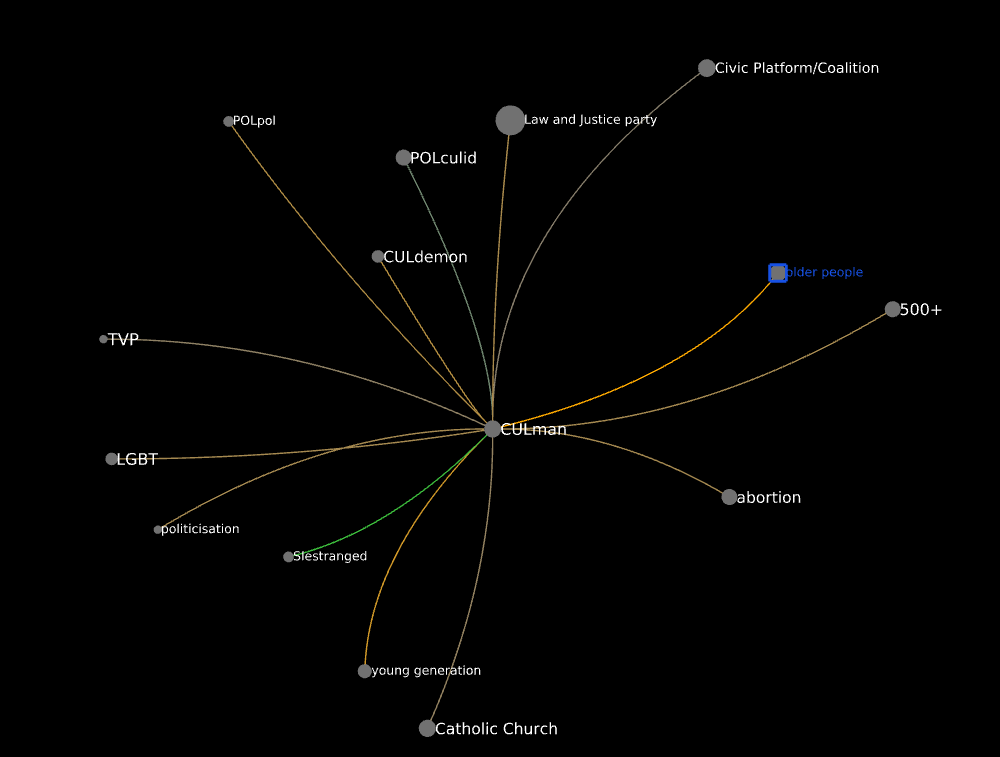
List of the codes co-occurring with CULman in the Polish corpus
500+
abortion
Catholic Church
Civic Platform/Coalition
CULdemon
CULman
Law and Justice party
LGBT
older people
POLculid
politicisation
POLpol
SIestranged
TVP
young generation